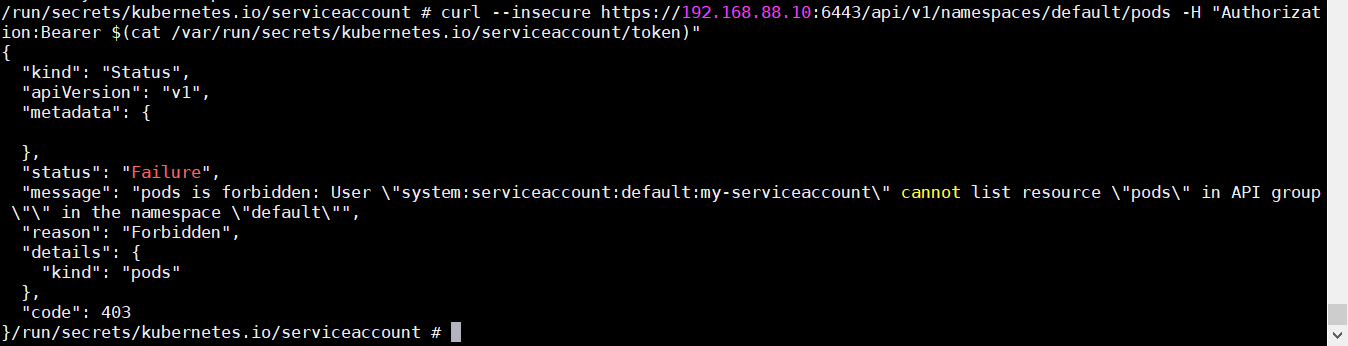
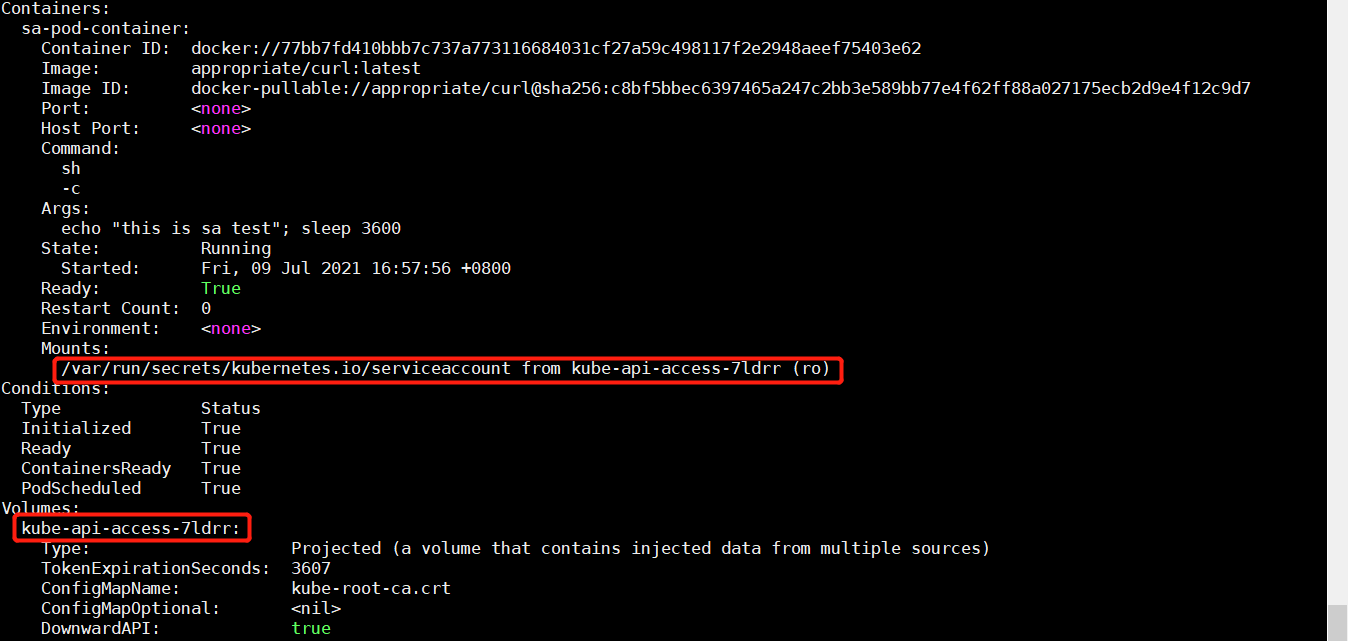
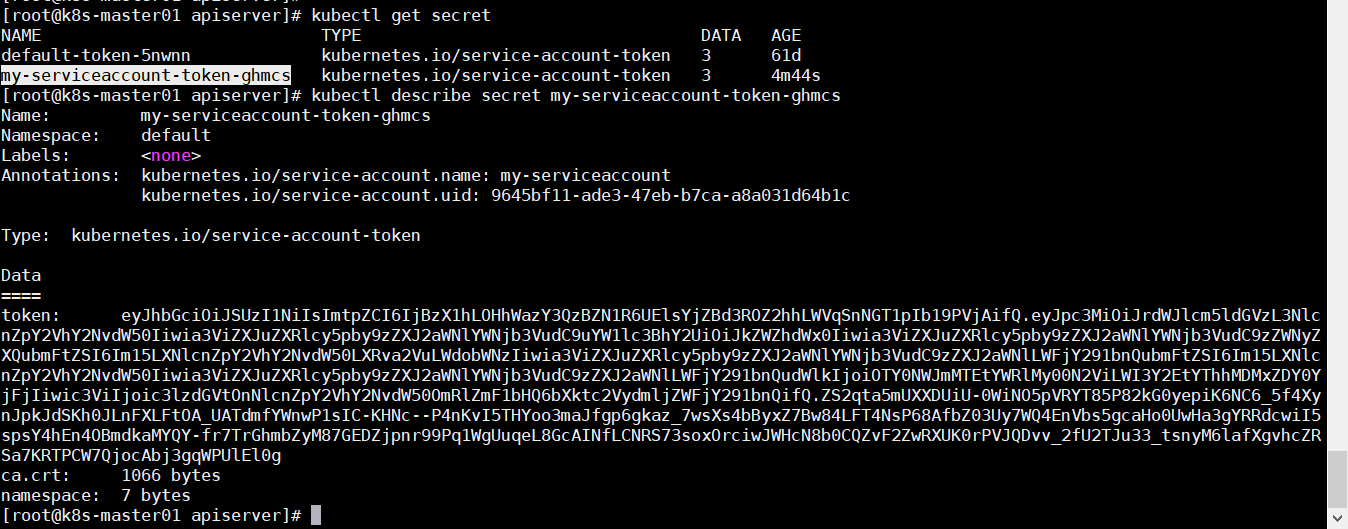
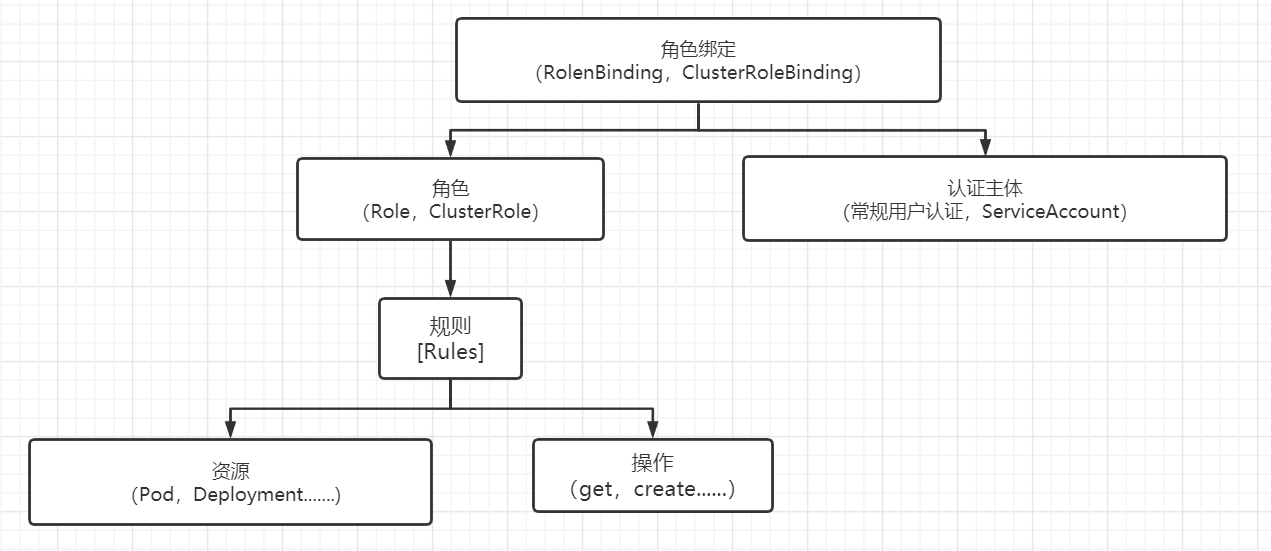
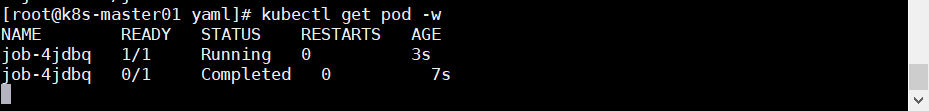一、概念 1.1 k8s概述 Kubernetes 是一个可移植的、可扩展的开源平台,用于管理容器化的工作负载和服务,可促进声明式配置和自动化。 Kubernetes 拥有一个庞大且快速增长的生态系统。Kubernetes 的服务、支持和工具广泛可用。
容器是打包和运行应用程序的好方式。在生产环境中,你需要管理运行应用程序的容器,并确保不会停机。 例如,如果一个容器发生故障,则需要启动另一个容器。如果系统处理此行为,会不会更容易?
这就是 Kubernetes 来解决这些问题的方法! Kubernetes 为你提供了一个可弹性运行分布式系统的框架。 Kubernetes 会满足你的扩展要求、故障转移、部署模式等。 例如,Kubernetes 可以轻松管理系统的 Canary 部署。
Kubernetes 简称 k8s,主要功能有:
服务发现和负载均衡
存储编排
自动部署和回滚
自动完成装箱计算
自我修复
密钥与配置管理
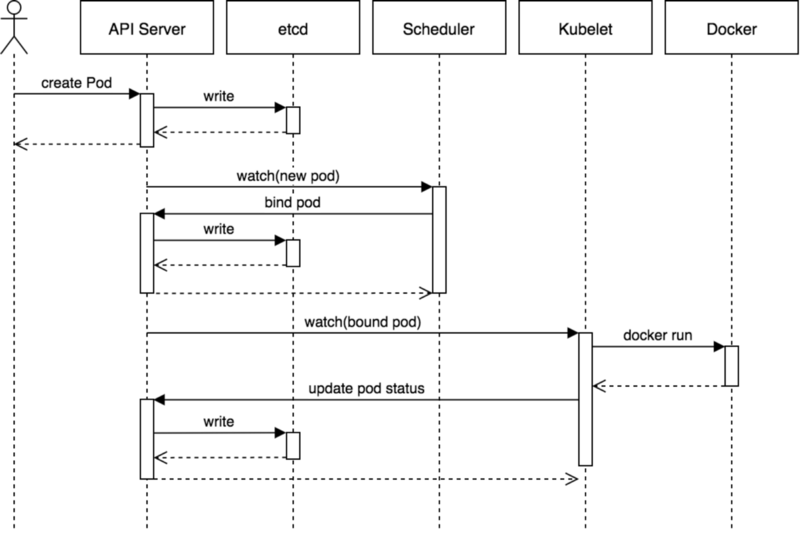
1.2 k8s组件 一个 Kubernetes 集群由一组被称作节点的机器组成。这些节点上运行 Kubernetes 所管理的容器化应用。集群具有至少一个工作节点。
工作节点托管作为应用负载的组件的 Pod 。控制平面管理集群中的工作节点和 Pod 。 为集群提供故障转移和高可用性,这些控制平面一般跨多主机运行,集群跨多个节点运行。
1.2.1 控制平面组件 kube-apiserver:
API 服务器是 Kubernetes 控制面的组件,该组件公开了 Kubernetes API。API 服务器是 Kubernetes 控制面的前端。
etcd:
etcd 是兼具一致性和高可用性的键值数据库,可以作为保存 Kubernetes 所有集群数据的后台数据库。
kube-scheduler:
控制平面组件,负责监视新创建的、未指定运行节点(node)的 Pods,选择节点让 Pod 在上面运行。
调度决策考虑的因素包括单个 Pod 和 Pod 集合的资源需求、硬件/软件/策略约束、亲和性和反亲和性规范、数据位置、工作负载间的干扰和最后时限。
kube-controller-manager:
在主节点上运行控制器的组件。
控制器包括:
节点控制器(Node Controller): 负责在节点出现故障时进行通知和响应
任务控制器(Job controller): 监测代表一次性任务的 Job 对象,然后创建 Pods 来运行这些任务直至完成
端点控制器(Endpoints Controller): 填充端点(Endpoints)对象(即加入 Service 与 Pod)
服务帐户和令牌控制器(Service Account & Token Controllers): 为新的命名空间创建默认帐户和 API 访问令牌
cloud-controller-manager:
云控制器管理器是指嵌入特定云的控制逻辑的控制平面组件。云控制器管理器允许您链接聚合到云提供商的应用编程接口中,并分离出相互作用的组件与您的集群交互的组件。
下面的控制器都包含对云平台驱动的依赖:
节点控制器(Node Controller): 用于在节点终止响应后检查云提供商以确定节点是否已被删除
路由控制器(Route Controller): 用于在底层云基础架构中设置路由
服务控制器(Service Controller): 用于创建、更新和删除云提供商负载均衡器
1.2.2 Node组件 节点组件在每个节点上运行,维护运行的 Pod 并提供 Kubernetes 运行环境。
kubelet:
一个在集群中每个节点(node)上运行的代理。它保证容器(containers)都运行在 Pod 中。
kubelet 接收一组通过各类机制提供给它的 PodSpecs,确保这些 PodSpecs 中描述的容器处于运行状态且健康。 kubelet 不会管理不是由 Kubernetes 创建的容器。
容器运行时(Container Runtime):
容器运行环境是负责运行容器的软件,例如 Docker 。
1.2.3 插件(Addons) 插件使用 Kubernetes 资源(DaemonSet、Deployment等)实现集群功能。 因为这些插件提供集群级别的功能,插件中命名空间域的资源属于 kube-system 命名空间。
DNS:
尽管其他插件都并非严格意义上的必需组件,但几乎所有 Kubernetes 集群都应该 有集群 DNS, 因为很多示例都需要 DNS 服务。
Web 界面(仪表盘):
Dashboard 是Kubernetes 集群的通用的、基于 Web 的用户界面。 它使用户可以管理集群中运行的应用程序以及集群本身并进行故障排除。
容器资源监控:
容器资源监控将关于容器的一些常见的时间序列度量值保存到一个集中的数据库中,并提供用于浏览这些数据的界面。
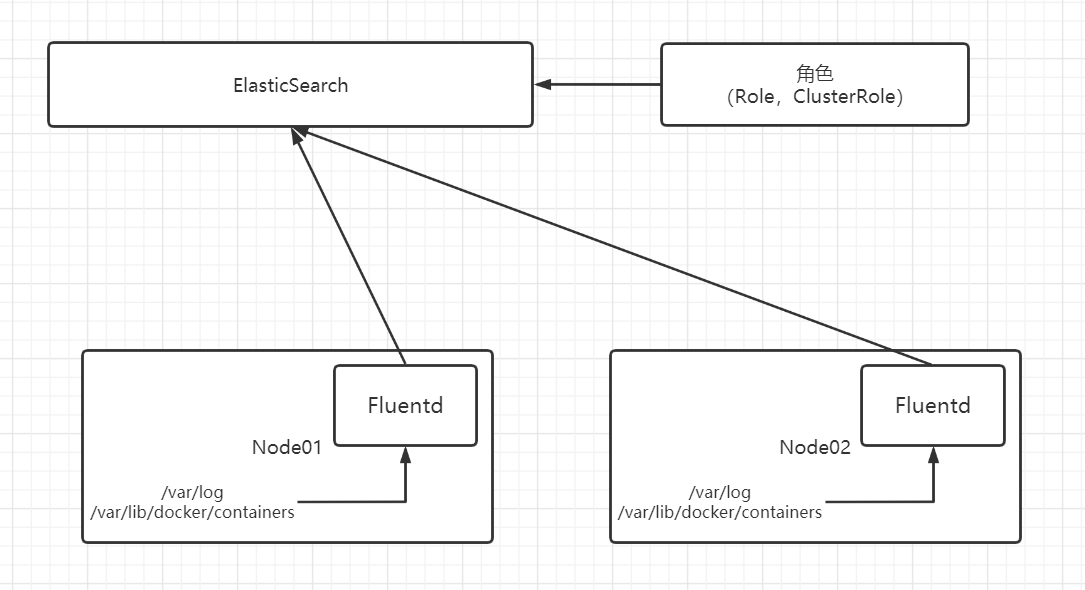
集群层面日志:
集群层面日志机制负责将容器的日志数据 保存到一个集中的日志存储中,该存储能够提供搜索和浏览接口。
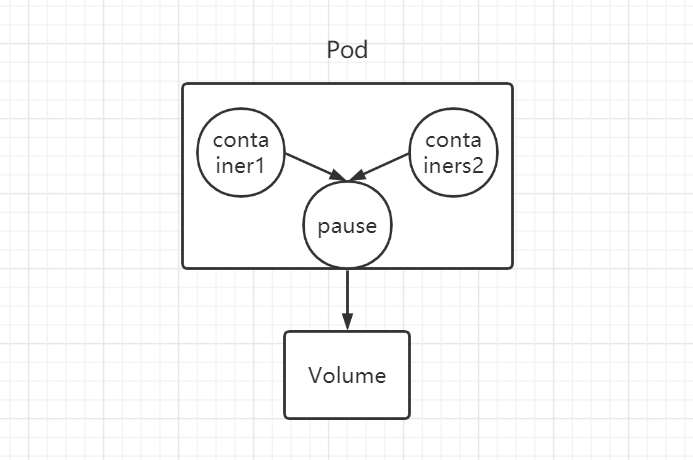
1.3 Pod 1.3.1 Pod概念 Pod 是 k8s 中的最小单元,一个 Pod 包含一个或多个容器,一个 Pod 不会跨越多个节点(Node)。
而每个 Pod 里都会有一个根容器 pause,Pod 中的其他容器都共享 pause 根容器的网络栈和volume挂载卷,因此容器之间的通信和数据交换会更为高效。
1.3.2 RC、RS、Deployment k8s 管理 Pod 主要用到以下三个组件:
Replication Controller(RC):用来确保容器应用的副本数始终保持在用户定义的副本数,如果有容器异常退出,会自动创建新的 Pod 来代替,如果有异常多出的容器也会自动回收。
ReplicaSet(RS):相比 RC 多了支持 selector,推荐使用 RS。
Deployment:用来管理 RS。
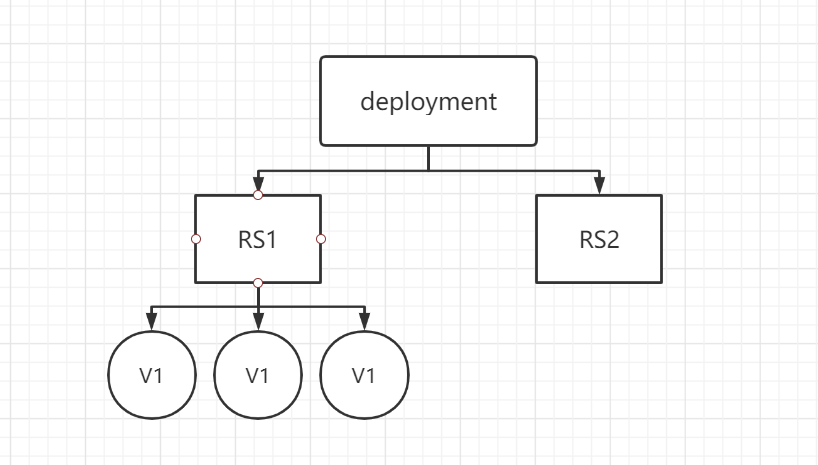
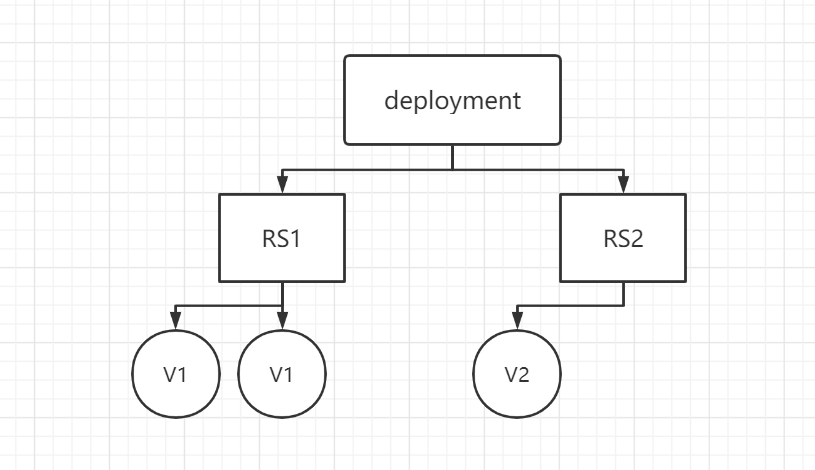
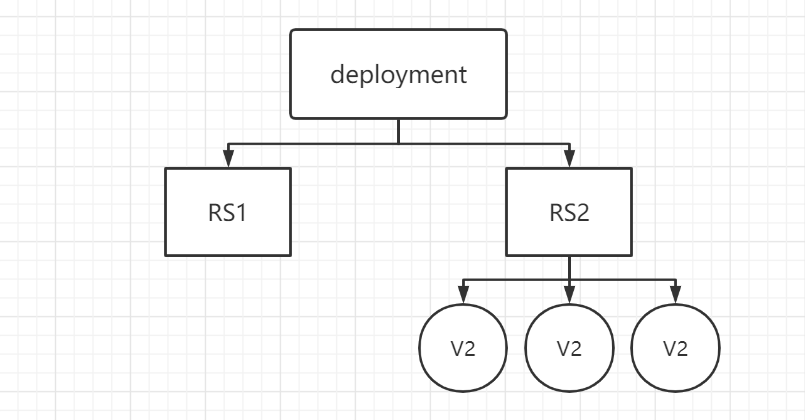
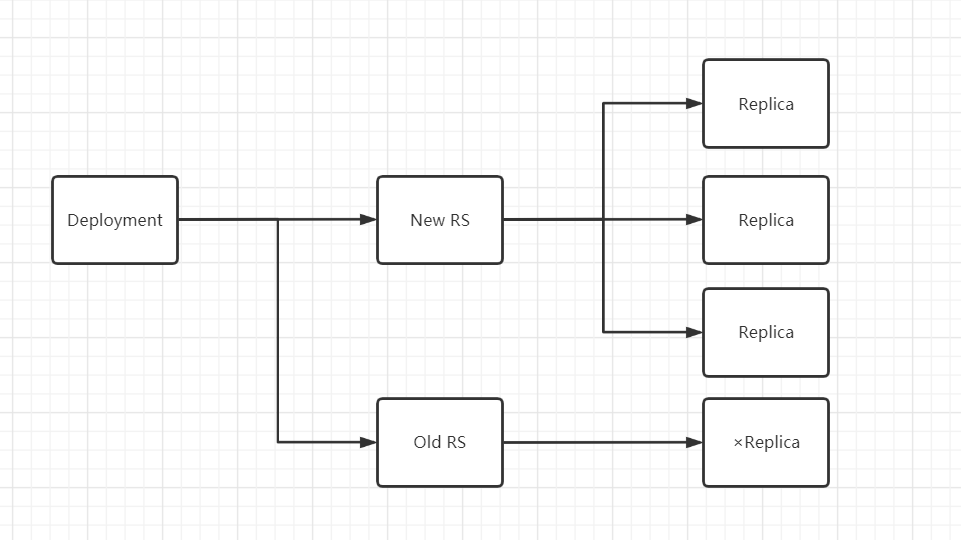
来看看 Deployment 和 RS 是如何实现更新的:
Deployment 创建新的 RS
RS1删除一个容器,接着 RS2 新建一个新版本的 Pod
全部更新完之后,RS1 并不会删除,而是保留着处于停用状态,如果新版本出了问题需要回滚,就可以反过来操作实现回滚
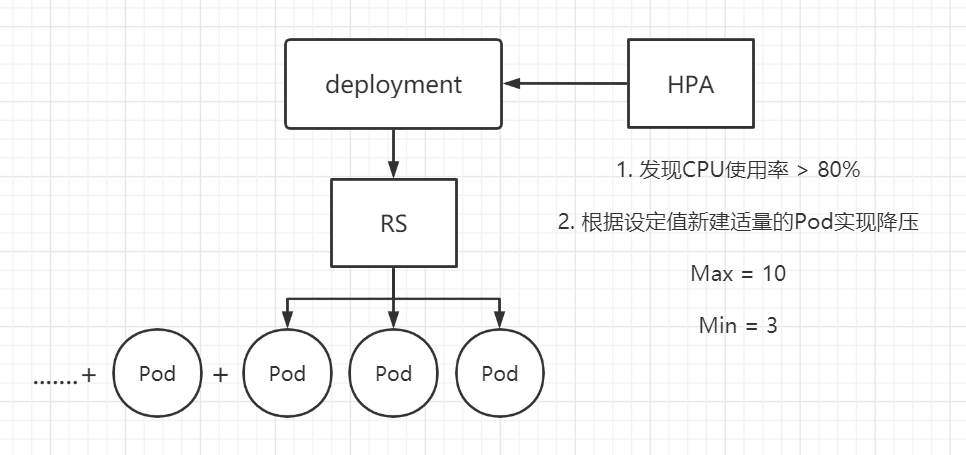
1.3.3 Horizontal Pod Autoscaler Horizontal Pod Autoscaler(HPA)在k8s集群中用于 Pod 水平自动弹性伸缩,它是基于 CPU 和内存利用率对 Deployment 和 RS 中的 Pod 数量进行自动扩缩容(除了 CPU 和内存利用率之外,也可以基于其他应程序提供的度量指标 custom metrics 进行自动扩缩容)。
假如 HPA 检测到当前 Deployment 和 RS 所管理的 Pod 的 CPU 或内存使用率超过了设定之后,就会创建新的 Pod 来实现降压,新建 Pod 的数量限制由 Max 和 Min 设定。
1.3.4 StatefulSet RS 和 Deployment 都是面向无状态的服务,它们所管理的 Pod 的 IP、名字,启停顺序等都是随机的,而 StatefulSet 是有状态的集合,管理所有有状态的服务,比如 MySQL、MongoDB 集群等。
StatefulSet 的特点有:
Pod 的一致性:包含次序(启停顺序,例如 mysql -> php-fpm -> nginx 的启动顺序)、网络一致性(与 Pod 相关,与被调度的 Node 节点无关)。
稳定的存储:即 Pod 重新调度之后还是访问到相同的持久化数据,基于 PVC(PV 是集群中由管理员提供或使用存储类动态提供的一块存储。它是集群中的资源,就像节点是集群资源一样。而 PVC 是用户对存储的请求。它类似于 Pod,Pod 消耗 Node 资源,而 PVC 消耗 PV 资源。) 来实现。
稳定的次序:对于N个副本的 StatefulSet,每个 Pod 都在 [0,N) 的范围内分配一个数字序号,且是唯一的。
稳定的网络:Pod 的 hostname 模式为:( StatefulSet 名称 ) - ( 序号 )。
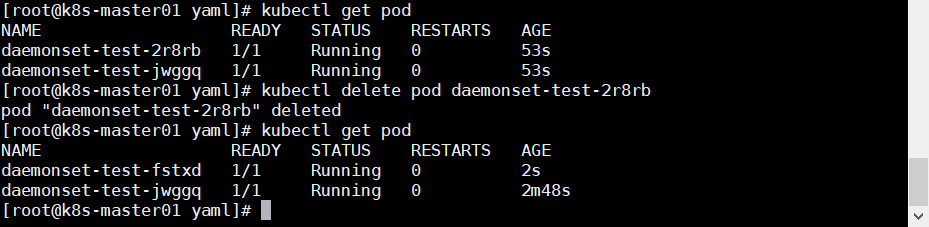
1.3.5 DaemonSet DaemonSet 确保全部或者一部分 Node 上运行一个 Pod 的副本,当有 Node 加入集群时,也会为他们新增一个 Pod,当这些 Node 退出集群时,这些 Pod 也会被回收。
DaemonSet 的一些典型用法:
运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph等。
运行日志收集daemon,例如fluentd、logstash等。
运行监控daemon,例如 Prometheus 的 Node exporter、zabbix等。
1.3.6 Job和Cron Job Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。
这里可能有人会想,那在 linux 上直接执行脚本不就行了吗?其实这就会有个问题,如果脚本执行失败那么久退出且不会再执行了,需要执行就必须手动,但 Job 设置的任务只有在正常执行结束后才会结束,否则一直执行到成功为止。Job 也可以设置成功的次数要达到几次才允许退出。
Cron Job 是基于时间管理控制 Job,即在给定的时间只运行一次、周期性的在指定时间运行。
1.3.7 Service Pod 的生命是有限的,如果 Pod 重启 IP 也可能会发生变化。如果我们将 Pod 的 IP 写死,Pod 如果挂了或重启,其它的服务也会不可用。我们可以把我们的服务(各种 Pod)注册到服务发现中心去,让服务发现中心去动态更新其它服务的配置就可以了,k8s 就给我们提供了这么一个服务,即 Service。
我们这样就可以不用去管后端的 Pod 如何变化,只需要指定 Service 的地址就可以了,因为我们在中间添加了一层服务发现的中间件,Pod 销毁或者重启后,把这个 Pod 的地址注册到这个服务发现中心去。
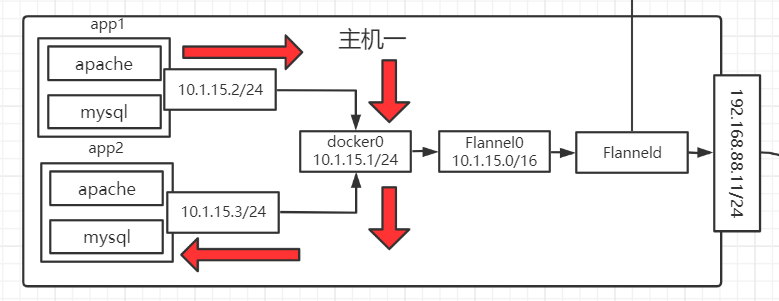
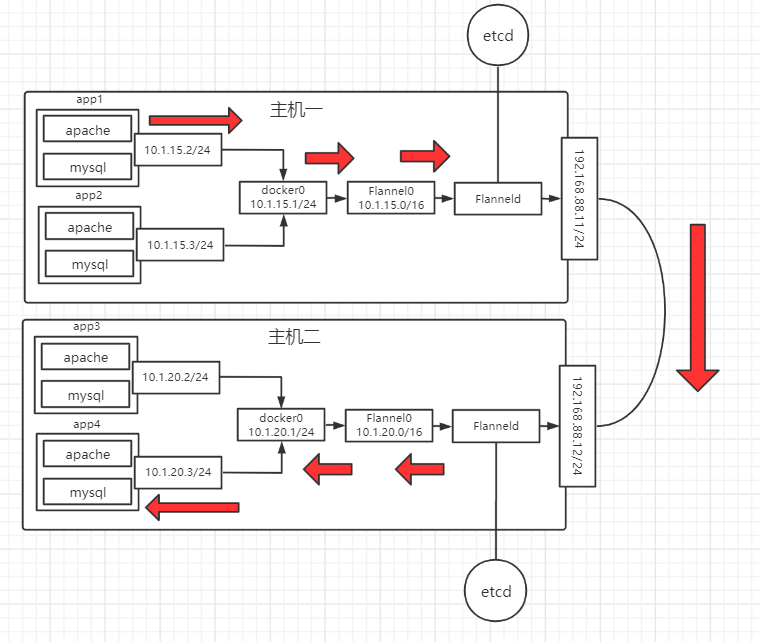
1.4 k8s的网络通讯方式 k8s 的网络模型假定了所有的 Pod 都在一个可以直接连通的扁平化网络空间中,在这 GCE(Google Compute Engine)里面是现成的网络模型。
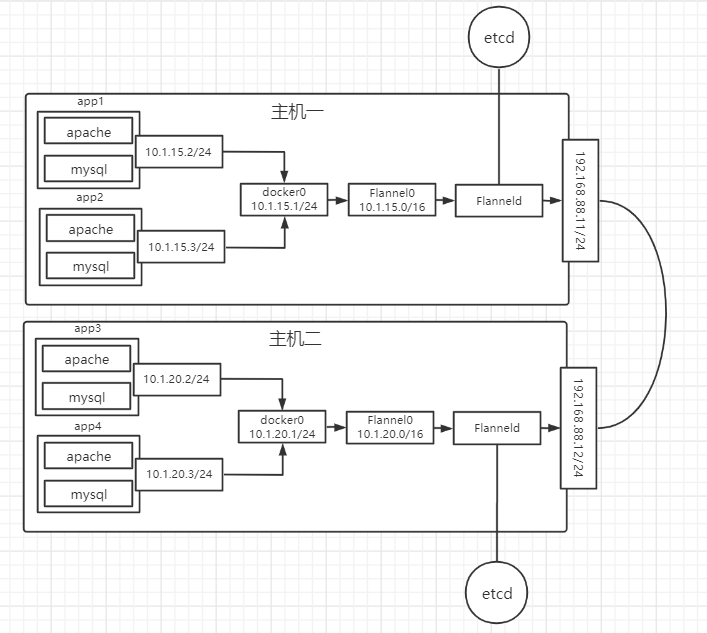
Flannel 是 CoreOS 团队针对 Kubernetes 设计一个网络规划服务,简单来说,它的功能是让集群中的不同节点主机创建 Docker 容器都具有全集群唯一的虚拟 IP 地址。而且它还能在这些 IP 地址之间建立一个覆盖网络(Overlay Network),通过覆盖网络将数据包原封不动的传递到目标容器内。
通过一个架构图来看看不同情况下的通讯是怎么样的:
通讯情况主要分为以下几种:
同一 Pod 不同容器之间的通信:采用 pause 网络栈。
同一 Node 不同 Pod 之间的通信:通过 docker0 网桥进行通信。
不同 Node 的 Pod 之间的通信:不同 Node 的 Pod 之间的通信是 k8s 网络通信的难点,是通过 Flannel 网络通讯方式来实现的,通讯的过程分为以下几个步骤:
数据包从 Node1 的 Pod 到达 docker0 网桥
Flanneld 会开启一个 Flannel0 的网桥,用来抓取到达 docker0 的数据,可以理解为一个钩子函数
Flanneld 会有很多路由表信息,是存储在 etcd 中由 Flanneld 自动获取的,通过路由表知道了转发信息后就通过物理网卡进行转发
发送到目标主机的物理网卡后,就会再通过 Flanneld -> Flannel0网桥 -> docker0网桥,最终到达目的 Pod
Pod 与 service 之间的通信:采用各节点的 iptables 规则来实现。
Pod 到外网:通过 Flanneld 到达物理网卡,经过路由选择后,iptables 执行 Masquerade,把Pod 的虚拟 IP 改为 物理网卡的 IP,在向外网服务器发出请求。
外网到 Pod:通过 service 进行访问,一般使用 NodePort。
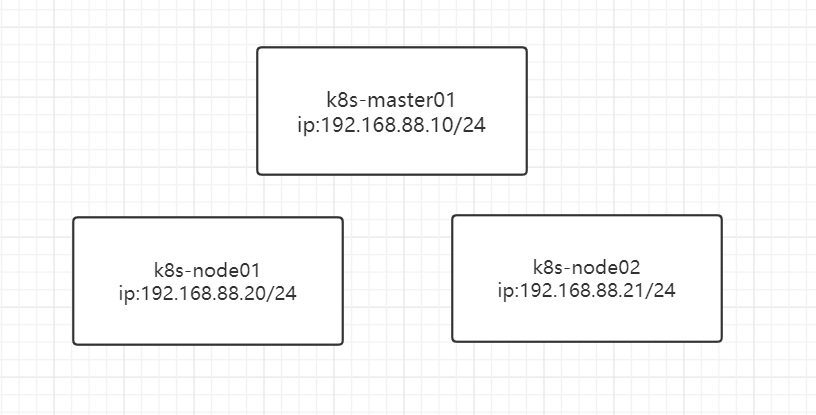
二、k8s部署 本次 k8s 部署为以下环境
2.1 基本环境配置(所有节点)
在各主机设置主机名以及host文件解析
1 2 3 4 5 6 7 hostnamectl set-hostname k8s-master01 hostnamectl set-hostname k8s-node01 hostnamectl set-hostname k8s-node02 vim /etc/hosts 192.168.88.10 k8s-master01 192.168.88.20 k8s-node01 192.168.88.21 k8s-node02
安装依赖
1 yum -y install conntrack ntpdate ntp ipvsadm ipset jp iptables curl stsstat libseccomp wget vim net-tools git
设置防火墙为iptables并设置空规则
1 2 3 4 5 systemctl stop firewalld && systemctl disable firewalld yum -y install iptables-services systemctl start iptables systemctl enable iptables iptables -F && service iptables save
关闭虚拟内存和selinux
1 2 swapoff -a && sed -i '/ swap / s/^\(.*\)$/#/g' /etc/fstab setenforce 0 && sed -i 's/^SELINUX=.*/SELINUX=disabled/' /etc/selinux/config
调整内核参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 cat > kubernetes.conf <<EOF net.bridge.bridge-nf-call-iptables=1 net.bridge.bridge-nf-call-ipv6tables=1 net.ipv4.ip_forward=1 net.ipv4.tcp_tw_recycle=0 vm.swappiness=0 # 禁用swap,只有系统OOM时才允许使用 vm.overcommit_memory=1 # 不检查物理内存是否够用 vm.panic_on_oom=0 # 开启OOM fs.inotify.max_user_instances=8192 fs.inotify.max_user_watches=1048576 fs.file-max=52706963 fs.nr_open=52706963 net.ipv6.conf.all.disable_ipv6=1 net.netfilter.nf_conntrack_max=2310720 EOF cp kubernetes.conf /etc/sysctl.d/kubernetes.conf sysctl -p /etc/sysctl.d/kubernetes.conf
调整系统时区
1 2 3 4 5 6 7 # 设为中国/上海 timedatectl set-timezone Asia/Shanghai # 将当前UTC时间写入硬件时钟 timedatectl set-local-rtc 0 # 重启依赖于时间的服务 systemctl restart rsyslog systemctl restart crond
关闭不需要的服务
1 2 # 关闭邮件服务 systemctl stop postfix && systemctl disable postfix
设置rsyslog和systemd journald
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 # 持久化保存日志目录 mkdir /var/log/journal mkdir /etc/systemd/journald.conf.d cat > /etc/systemd/journald.conf.d/99-prophet.conf <<EOF [Journal] # 持久化保存到磁盘 Storage=persistent # 压缩历史日志 Compress=yes SyncIntervalSec=5m RateLimitInterval=30s RateLimitBurst=1000 # 最大占用空间 10G SystemMaxUse=10G # 单日志文件最大 200M SystemMaxFileSize=200M # 日志保存时间 2 周 MaxRetentionSec=2week # 不将日志转发到 syslog ForwardToSyslog=no EOF systemctl restart systemd-journald
升级内核
1 2 3 4 5 6 7 8 9 10 # 导入公钥 rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org # 安装elrepo源 yum -y install https://www.elrepo.org/elrepo-release-7.el7.elrepo.noarch.rpm # 升级内核 yum --enablerepo=elrepo-kernel install -y kernel-lt # 设置开机从新内核启动 grub2-set-default "CentOS Linux (5.4.116-1.e17.elrepo.x86_64) 7 (Core)" # 查看内核启动项 grub2-editenv list
2.2 kubeadm部署(所有节点)
kube-proxy开启ipvs前置条件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 modprobe br_netfilter vim /etc/sysconfig/modules/ipvs.modules # !/bin/bash ipvs_modules="ip_vs ip_vs_lc ip_vs_wlc ip_vs_rr ip_vs_wrr ip_vs_lblc ip_vs_lblcr ip_vs_dh ip_vs_sh ip_vs_fo ip_vs_nq ip_vs_sed ip_vs_ftp nf_conntrack" for kernel_module in ${ipvs_modules}; do /sbin/modinfo -F filename ${kernel_module} > /dev/null 2>&1 if [ $? -eq 0 ]; then /sbin/modprobe ${kernel_module} fi done chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules && lsmod | grep -e ip_vs -e nf_conntrack
安装docker
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 yum -y install yum-utils device-mapper-persistent-data lvm2 yum-config-manager --add-repo https://mirrors.tuna.tsinghua.edu.cn/docker-ce/linux/centos/docker-ce.repo yum makecache fast yum -y install docker-ce docker-ce-cli mkdir /etc/docker cat > /etc/docker/daemon.json <<EOF { "registry-mirrors": ["http://f1361db2.m.daocloud.io"], "exec-opts":["native.cgroupdriver=systemd"], "log-driver":"json-file", "log-opts":{ "max-size":"100m" } } EOF mkdir -p /etc/systemd/system/docker.service.d systemctl daemon-reload && systemctl start docker && systemctl enable docker
2.3 安装kubeadm(所有节点)
安装 kubeadm kubectl kubelet
1 2 3 4 5 6 7 8 9 10 11 12 cat <<EOF > /etc/yum.repos.d/kubernetes.repo [kubernetes] name=kubernetes baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64 enabled=1 gpgcheck=1 repo_gpgcheck=1 gpgkey=https://mirrors.aliyun.com/kubernetes/yum/doc/yum-key.gpg https://mirrors.aliyun.com/kubernetes/yum/doc/rpm-package-key.gpg EOF yum -y install kubeadm kubectl kubelet systemctl enable kubelet
通过kubeadm查看目前各镜像版本
1 2 3 4 5 6 7 8 kubeadm config images list k8s.gcr.io/kube-apiserver:v1.21.0 k8s.gcr.io/kube-controller-manager:v1.21.0 k8s.gcr.io/kube-scheduler:v1.21.0 k8s.gcr.io/kube-proxy:v1.21.0 k8s.gcr.io/pause:3.4.1 k8s.gcr.io/etcd:3.4.13-0 k8s.gcr.io/coredns/coredns:v1.8.0
编写脚本,通过阿里镜像安装
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vim k8s_images.sh # !/bin/bash apiserver_var=v1.21.0 controller_manager_var=v1.21.0 scheduler_var=v1.21.0 proxy_var=v1.21.0 pause_var=3.4.1 etcd_var=3.4.13-0 coredns_var=v1.8.0 image_aliyun=(kube-apiserver:$apiserver_var kube-controller-manager:$controller_manager_var kube-scheduler:$scheduler_var kube-proxy:$proxy_var pause:$pause_var etcd:$etcd_var coredns/coredns:$coredns_var) for image in ${image_aliyun[@]} do docker pull registry.cn-hangzhou.aliyuncs.com/google_containers/$image docker tag registry.cn-hangzhou.aliyuncs.com/google_containers/$image k8s.gcr.io/${image} docker rmi registry.cn-hangzhou.aliyuncs.com/google_containers/$image done ./k8s_images.sh # 问题 # 由于杭州阿里源里目前没有coredns:v1.8.0版本,所以在北京阿里源下载 docker pull registry.cn-beijing.aliyuncs.com/dotbalo/coredns:1.8.0 docker tag registry.cn-beijing.aliyuncs.com/dotbalo/coredns:1.8.0 k8s.gcr.io/coredns/coredns:v1.8.0 docker rmi registry.cn-beijing.aliyuncs.com/dotbalo/coredns:1.8.0
2.4 初始化Master节点 1 kubeadm config print init-defaults > kubeadm.config.yml
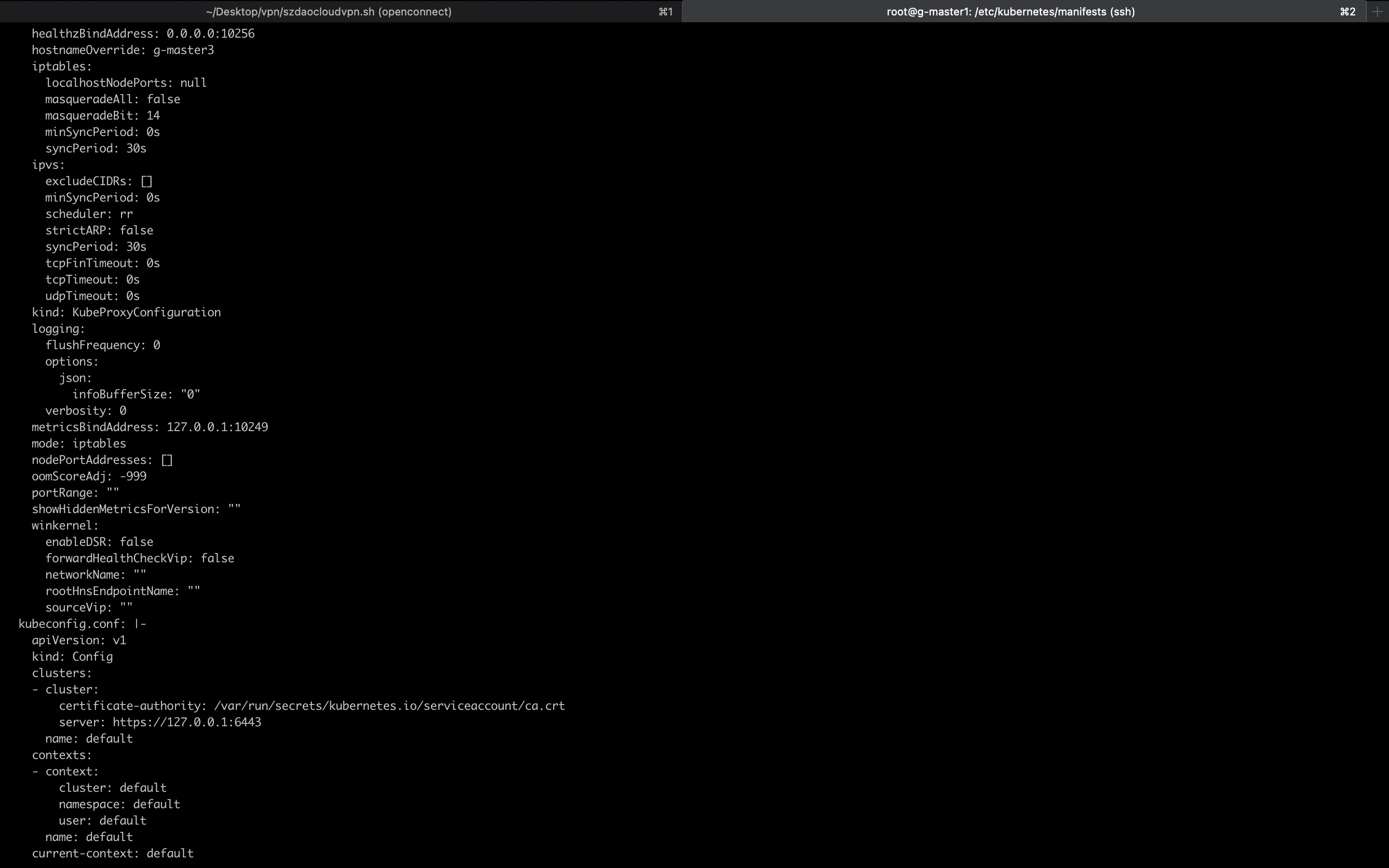
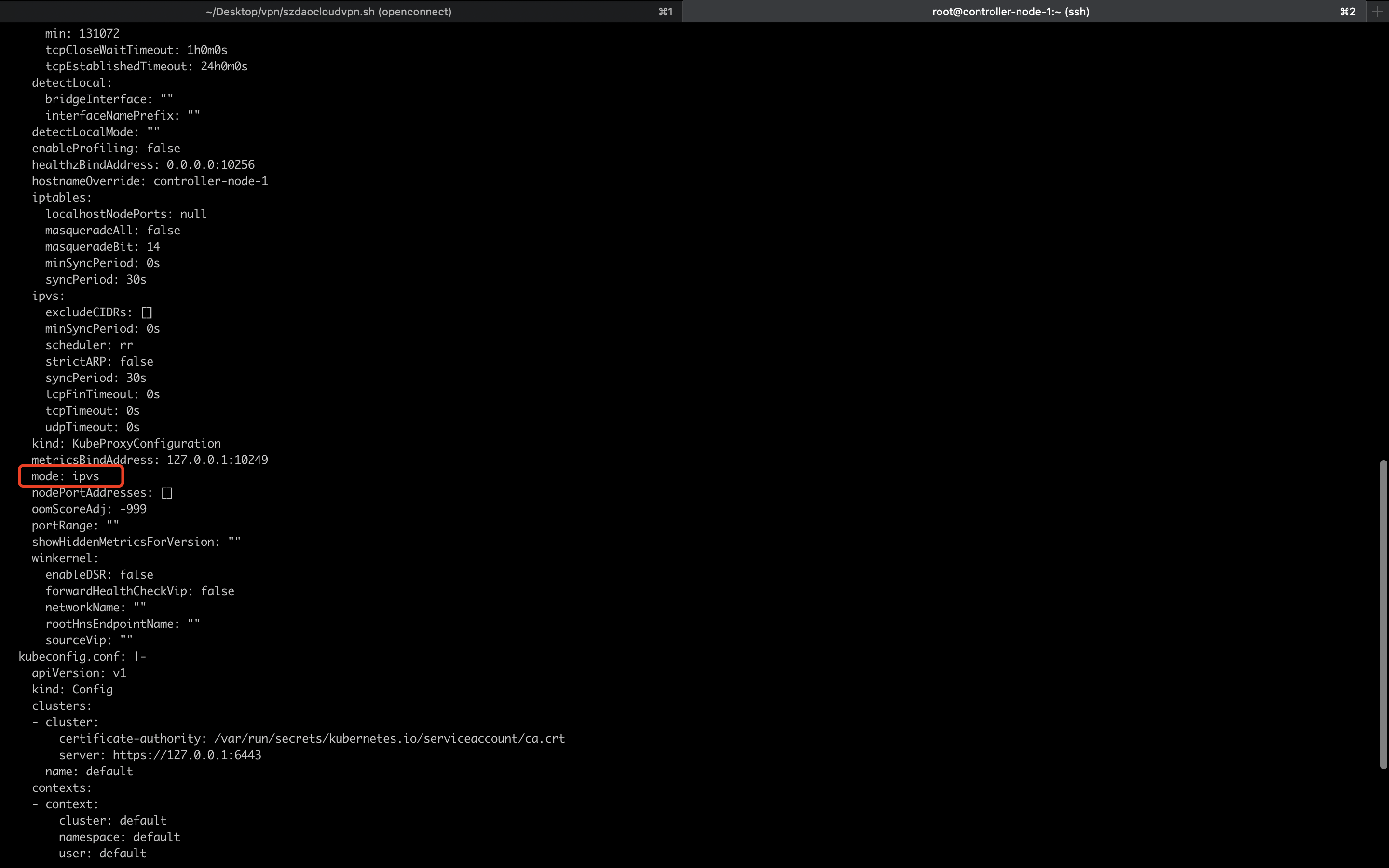
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 vim kubeadm.config.yml apiVersion: kubeadm.k8s.io/v1beta2 bootstrapTokens: - groups: - system:bootstrappers:kubeadm:default-node-token token: abcdef.0123456789abcdef ttl: 24h0m0s usages: - signing - authentication kind: InitConfiguration localAPIEndpoint: advertiseAddress: 192.168 .88 .10 bindPort: 6443 nodeRegistration: criSocket: /var/run/dockershim.sock name: node taints: null --- apiServer: timeoutForControlPlane: 4m0s apiVersion: kubeadm.k8s.io/v1beta2 certificatesDir: /etc/kubernetes/pki clusterName: kubernetes controllerManager: {}dns: type: CoreDNS etcd: local: dataDir: /var/lib/etcd imageRepository: k8s.gcr.io kind: ClusterConfiguration kubernetesVersion: 1.21 .0 networking: dnsDomain: cluster.local podSubnet: 10.244 .0 .0 /16 serviceSubnet: 10.96 .0 .0 /12 scheduler: {}--- apiVersion: kubeproxy.config.k8s.io/v1alpha1 kind: KubeProxyConfiguration kubeproxy: config: mode: ipvs
1 2 3 4 5 6 kubeadm init --config=kubeadm.config.yml --upload-certs | tee kubeadm-init.log ... # 初始化后操作 mkdir -p $HOME/.kube cp -i /etc/kubernetes/admin.conf $HOME/.kube/config chown $(id -u):$(id -g) $HOME/.kube/config
2.5 部署网络 1 2 3 mkdir -p k8s/plugin/flannel && cd k8s/plugin/flannel wget https://raw.githubusercontent.com/coreos/flannel/master/Documentation/kube-flannel.yml kubectl create -f kube-flannel.yml
kube-flannel.yml文件内容
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 --- apiVersion: policy/v1beta1 kind: PodSecurityPolicy metadata: name: psp.flannel.unprivileged annotations: seccomp.security.alpha.kubernetes.io/allowedProfileNames: docker/default seccomp.security.alpha.kubernetes.io/defaultProfileName: docker/default apparmor.security.beta.kubernetes.io/allowedProfileNames: runtime/default apparmor.security.beta.kubernetes.io/defaultProfileName: runtime/default spec: privileged: false volumes: - configMap - secret - emptyDir - hostPath allowedHostPaths: - pathPrefix: "/etc/cni/net.d" - pathPrefix: "/etc/kube-flannel" - pathPrefix: "/run/flannel" readOnlyRootFilesystem: false runAsUser: rule: RunAsAny supplementalGroups: rule: RunAsAny fsGroup: rule: RunAsAny allowPrivilegeEscalation: false defaultAllowPrivilegeEscalation: false allowedCapabilities: ['NET_ADMIN' , 'NET_RAW' ] defaultAddCapabilities: [] requiredDropCapabilities: [] hostPID: false hostIPC: false hostNetwork: true hostPorts: - min: 0 max: 65535 seLinux: rule: 'RunAsAny' --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: flannel rules: - apiGroups: ['extensions' ] resources: ['podsecuritypolicies' ] verbs: ['use' ] resourceNames: ['psp.flannel.unprivileged' ] - apiGroups: - "" resources: - pods verbs: - get - apiGroups: - "" resources: - nodes verbs: - list - watch - apiGroups: - "" resources: - nodes/status verbs: - patch --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: flannel roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: flannel subjects: - kind: ServiceAccount name: flannel namespace: kube-system --- apiVersion: v1 kind: ServiceAccount metadata: name: flannel namespace: kube-system --- kind: ConfigMap apiVersion: v1 metadata: name: kube-flannel-cfg namespace: kube-system labels: tier: node app: flannel data: cni-conf.json: | { "name": "cbr0", "cniVersion": "0.3.1", "plugins": [ { "type": "flannel", "delegate": { "hairpinMode": true, "isDefaultGateway": true } }, { "type": "portmap", "capabilities": { "portMappings": true } } ] } net-conf.json: | { "Network": "10.244.0.0/16", "Backend": { "Type": "vxlan" } } --- apiVersion: apps/v1 kind: DaemonSet metadata: name: kube-flannel-ds namespace: kube-system labels: tier: node app: flannel spec: selector: matchLabels: app: flannel template: metadata: labels: tier: node app: flannel spec: affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/os operator: In values: - linux hostNetwork: true priorityClassName: system-node-critical tolerations: - operator: Exists effect: NoSchedule serviceAccountName: flannel initContainers: - name: install-cni image: quay.io/coreos/flannel:v0.14.0-rc1 command: - cp args: - -f - /etc/kube-flannel/cni-conf.json - /etc/cni/net.d/10-flannel.conflist volumeMounts: - name: cni mountPath: /etc/cni/net.d - name: flannel-cfg mountPath: /etc/kube-flannel/ containers: - name: kube-flannel image: quay.io/coreos/flannel:v0.14.0-rc1 command: - /opt/bin/flanneld args: - --ip-masq - --kube-subnet-mgr resources: requests: cpu: "100m" memory: "50Mi" limits: cpu: "100m" memory: "50Mi" securityContext: privileged: false capabilities: add: ["NET_ADMIN" , "NET_RAW" ] env: - name: POD_NAME valueFrom: fieldRef: fieldPath: metadata.name - name: POD_NAMESPACE valueFrom: fieldRef: fieldPath: metadata.namespace volumeMounts: - name: run mountPath: /run/flannel - name: flannel-cfg mountPath: /etc/kube-flannel/ volumes: - name: run hostPath: path: /run/flannel - name: cni hostPath: path: /etc/cni/net.d - name: flannel-cfg configMap: name: kube-flannel-cfg
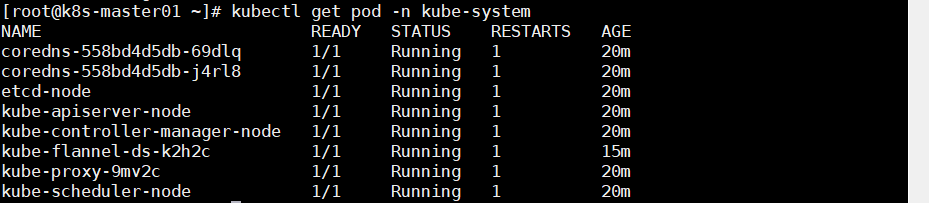
部署完后可以看到 flannel 网卡
通过命令查看各模块运行情况
1 kubectl get pod -n kube-system
2.6 添加Node节点
查看kubeadm-init.log
1 2 3 ... kubeadm join 192.168.88.10:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:37c9645a7a2ee75301f132537240157ecd4f464494022cc442f77489c1978989
在node主机上执行
1 2 kubeadm join 192.168.88.10:6443 --token abcdef.0123456789abcdef \ --discovery-token-ca-cert-hash sha256:37c9645a7a2ee75301f132537240157ecd4f464494022cc442f77489c1978989
在master主机查看是否加入成功
1 2 3 4 kubectl get node ... kubectl get pod -n kube-system -o wide ...
三、k8s资源清单 在 k8s 中,一般使用 yaml 格式的文件来创建符合我们预期期望的 pod,这样的 yaml 文件我们一般称为资源清单。
3.1 资源类型 名称空间级别
工作负载型资源:Pod、RS、Deployment、StatefulSet、DaemonSet、Job、CronJob
服务发现及负载均衡型资源:Service
配置与存储型资源:Volume、CSI
特殊类型的存储卷:ConfigMap(当配置中心来使用的资源类型)、Secret(保存敏感数据)、DownwarAPI(把外部环境中的信息输出给容器)
集群级资源:Namespace、Node、Role、ClusterRole、RoleBinding、ClusterRoleBinding
元数据型资源:HPA、PodTemplate、LimitRange
3.2 常用字段 必要属性
参数名
字段类型
说明
apiVersion
String
K8S API 的版本,目前基本是v1,可以用 kubectl api-versions 命令查询
kind
String
这里指的是 yaml 文件定义的资源类型和角色,比如: Pod
metadata
Object
元数据对象,固定值写 metadata
metadata.name
String
元数据对象的名字,这里由我们编写,比如命名Pod的名字
metadata.namespace
String
元数据对象的命名空间,由我们自身定义
spec
Object
详细定义对象,固定值写Spec
spec.containers[]
list
这里是Spec对象的容器列表定义,是个列表
spec.containers[].name
String
这里定义容器的名字
spec.containers[].image
String
这里定义要用到的镜像名称
spec 主要对象
参数名
字段类型
说明
spec.containers[].name
String
定义容器的名字
spec.containers[].image
String
定义要用到的镜像的名称
spec.containers[].imagePullPolicy
String
定义镜像拉取策略,有 Always,Never,IfNotPresent 三个值课选 (1)Always:意思是每次尝试重新拉取镜像 (2)Never:表示仅使用本地镜像 (3)IfNotPresent:如果本地有镜像就是用本地镜像,没有就拉取在线镜像。上面三个值都没设置的话,默认是 Always
spec.containers[].command[]
List
指定容器启动命令,因为是数组可以指定多个,不指定则使用镜像打包时使用的启动命令
spec.containers[].args[]
List
指定容器启动命令参数,因为是数组可以指定多个
spec.containers[].workingDir
String
指定容器的工作目录
spec.containers[].volumeMounts[]
List
指定容器内部的存储卷配置
spec.containers[].volumeMounts[].name
String
指定可以被容器挂载的存储卷的名称
spec.containers[].volumeMounts[].mountPath
String
指定可以被容器挂载的容器卷的路径
spec.containers[].volumeMounts[].readOnly
String
设置存储卷路径的读写模式,true 或者 false,默认为读写模式
spec.containers[].ports[]
List
指定容器需要用到的端口列表
spec.containers[].ports[].name
String
指定端口名称
spec.containers[].ports[].containerPort
String
指定容器需要监听的端口号
spec.containers[].ports.hostPort
String
指定容器所在主机需要监听的端口号,默认跟上面 containerPort 相同,注意设置了 hostPort 同一台主机无法启动该容器的相同副本(因为主机的端口号不能相同,这样会冲突)
spec.containers[].ports[].protocol
String
指定端口协议,支持TCP和UDP,默认值为TCP
spec.containers[].env[]
List
指定容器运行千需设置的环境变量列表
spec.containers[].env[].name
String
指定环境变量名称
spec.containers[].env[].value
String
指定环境变量值
spec.containers[].resources
Object
指定资源限制和资源请求的值(这里开始就是设置容器的资源上限)
spec.containers[].resources.limits
Object
指定设置容器运行时资源的运行上限
spec.containers[].resources.limits.cpu
String
指定CPU的限制,单位为 core 数,将用于 docker run –cpu-shares 参数
spec.containers[].resources.limits.memory
String
指定 MEM 内存的限制,单位为 MIB,GIB
spec.containers[].resources.requests
Object
指定容器启动和调度室的限制设置
spec.containers[].resources.requests.cpu
String
CPU请求,单位为 core 数,容器启动时初始化可用数量
spec.containers[].resources.requests.memory
String
内存请求,单位为 MIB,GIB 容器启动的初始化可用数量
额外的参数项
参数名
字段类型
说明
spec.restartPolicy
String
定义Pod重启策略,可以选择值为 Always、OnFailure、Never,默认值为 Always。1. Always:Pod一旦终止运行,则无论容器是如何终止的,kubelet 服务都将重启它。2. OnFailure:只有 Pod 以非零退出码终止时,kubelet 才会重启该容器。如果容器正常结束(退出码为0),则 kubelet 将不会重启它。3. Never:Pod 终止后,kubelet 将退出码报告给 Master,不会重启该 Pod。
spec.nodeSelector
Object
定义 Node 的 Label 过滤标签,以 key:value 格式指定
spec.imagePullSecrets
Object
定义pull 镜像是使用 secret 名称,以 name:secretkey 格式指定
spec.hostNetwork
Boolean
定义是否使用主机网络模式,默认值为 false。设置 true 表示使用宿主机网络,不使用 docker 网桥,同时设置了 true 将无法在同一台宿主机上启动第二个副本。
辅助命令
1 2 # 查看资源对象用法 kubectl explain <资源对象>
例子:
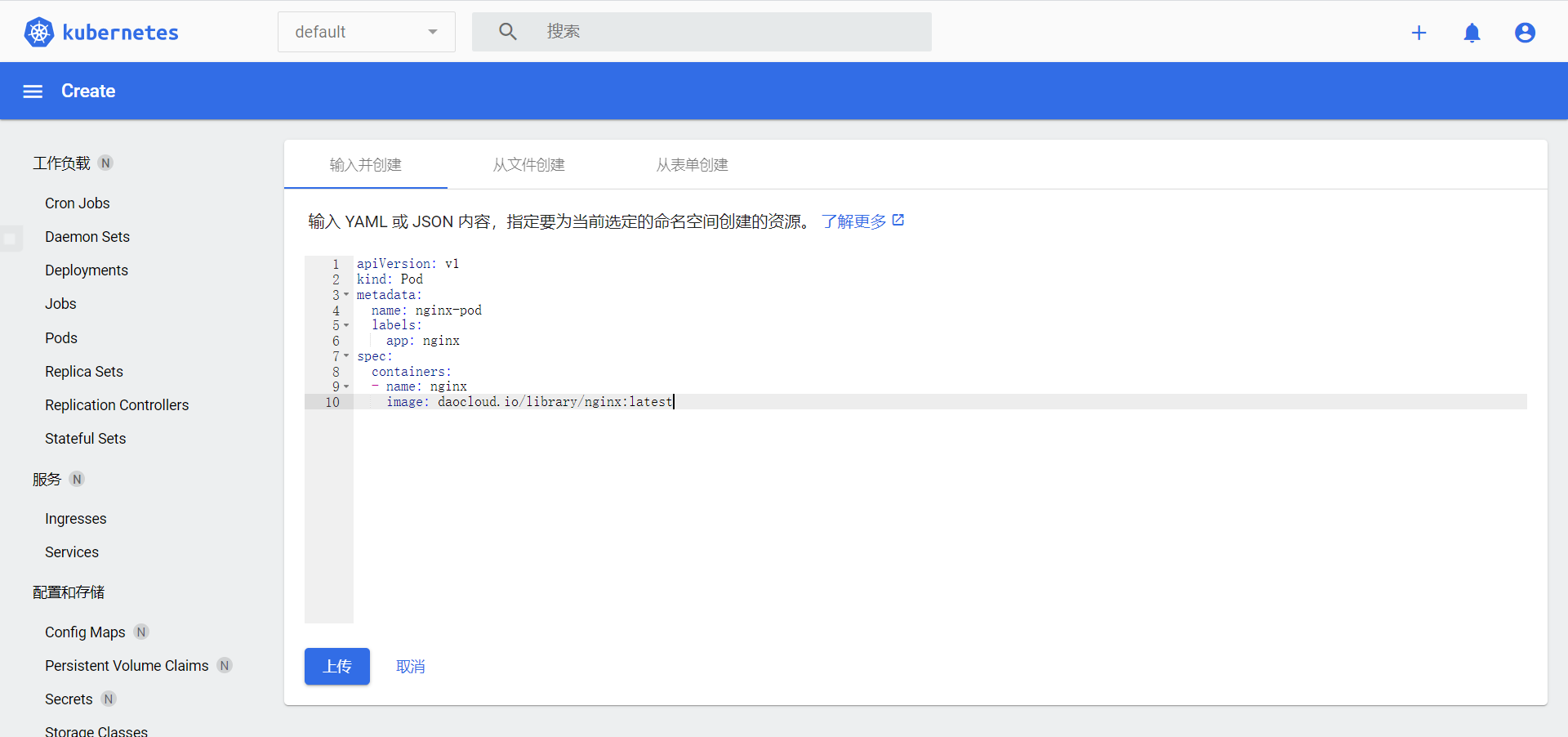
创建 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 vim nginx.yaml apiVersion: v1 kind: Pod metadata: name: nginx-pod labels: app: nginx spec: containers: - name: nginx image: daocloud.io/library/nginx:latest
创建pod
1 kubectl apply -f nginx.yaml
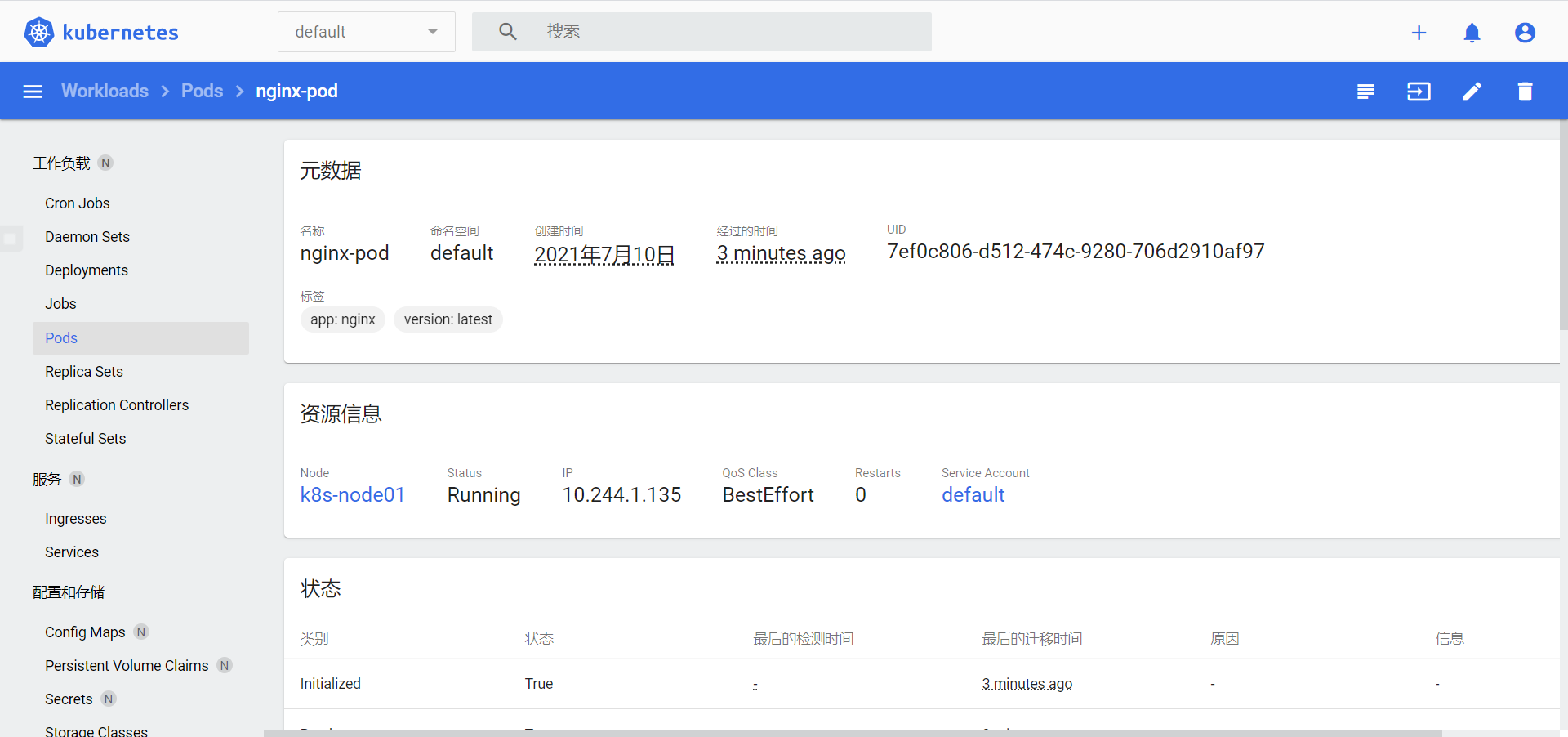
查看状态
1 2 3 4 5 6 7 8 9 # 查看是否生成pod kubectl get pod ... # 查看pod详细信息 kubectl describe pod nginx-pod ... # 测试能否访问 curl 10.244.1.2 # 此处为flannel分配的地址 ...
3.3 容器生命周期 每一个 Pod 被成功创立之前,都会进行初始化,会运行零个或若干个 init 容器,init 容器运行完就释放,接着才会运行 main 主容器,当然在 init 容器运行之前会先运行 pause 容器,以保证存储和网络的可用。
init 容器与普通的容器非常相似,除了以下两点:
init 容器总是运行到完成。
每个 init 容器都要在下一个容器启动之前完成。
如果 Pod 的 Init 容器失败,kubelet 会不断地重启该 Init 容器直到该容器成功为止。 然而,如果 Pod 对应的 restartPolicy 值为 “Never”,Kubernetes 不会重新启动 Pod。
如果为一个 Pod 指定了多个 Init 容器,这些容器会按顺序逐个运行。 每个 Init 容器必须运行成功,下一个才能够运行。当所有的 Init 容器运行完成时, Kubernetes 才会为 Pod 初始化应用容器并像平常一样运行。
init 容器的使用
因为 Init 容器具有与应用容器分离的单独镜像,其启动相关代码具有如下优势:
Init 容器可以包含一些安装过程中应用容器中不存在的实用工具或个性化代码。 例如,没有必要仅为了在安装过程中使用类似 sed、awk、python 或 dig 这样的工具而去 FROM 一个镜像来生成一个新的镜像。
Init 容器可以安全地运行这些工具,避免这些工具导致应用镜像的安全性降低。
应用镜像的创建者和部署者可以各自独立工作,而没有必要联合构建一个单独的应用镜像。
Init 容器能以不同于 Pod 内应用容器的文件系统视图运行。因此,Init 容器可以访问应用容器不能访问的 Secret 的权限。
由于 Init 容器必须在应用容器启动之前运行完成,因此 Init 容器提供了一种机制来阻塞或延迟应用容器的启动,直到满足了一组先决条件。 一旦前置条件满足,Pod 内的所有的应用容器会并行启动。
init 容器使用例子
编写 yaml 文件
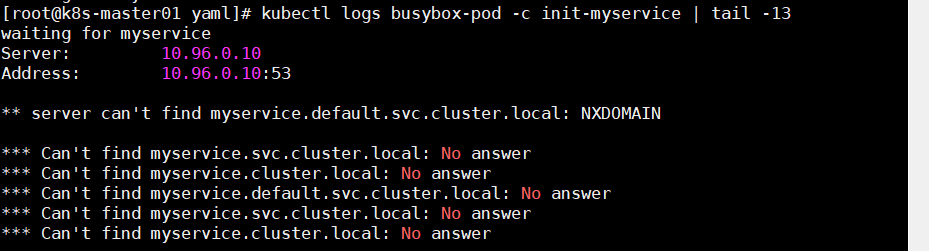
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 vim busybox.yaml apiVersion: v1 kind: Pod metadata: name: busybox-pod labels: app: busybox spec: containers: - name: busybox image: busybox:latest command: ['sh' ,'-c' ,'echo The busybox app is running! && sleep 3600' ] initContainers: - name: init-myservice image: busybox command: ['sh' ,'-c' ,'until nslookup myservice; do echo waiting for myservice; sleep 2; done' ] - name: init-mydb image: busybox command: ['sh' ,'-c' ,'until nslookup mydb; do echo waiting for mydb; sleep 2; done' ]
运行
1 kubectl create -f busybox.yaml
可以看到一直处于 Init:0/2 状态,因为第一个 init 容器一直没完成
编写 yaml 文件添加 service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 vim service.yaml apiVersion: v1 kind: Service metadata: name: myservice spec: ports: - protocol: TCP port: 80 targetPort: 9376 --- apiVersion: v1 kind: Service metadata: name: mydb spec: ports: - protocol: TCP port: 80 targetPort: 9377
运行
1 kubectl create -f service.yaml
可以看到两个 init 容器都执行完,main 主容器也就运行了
3.4 探针 探针(probe)是由 kubelet 对容器执行的定期诊断。 要执行诊断,kubelet 调用由容器实现的 Handler (处理程序)。有三种类型的处理程序:
ExecAction : 在容器内执行指定命令。如果命令退出时返回码为 0 则认为诊断成功。TCPSocketAction : 对容器的 IP 地址上的指定端口执行 TCP 检查。如果端口打开,则诊断被认为是成功的。HTTPGetAction : 对容器的 IP 地址上指定端口和路径执行 HTTP Get 请求。如果响应的状态码大于等于 200 且小于 400,则诊断被认为是成功的。
每次探测都将获得以下三种结果之一:
Success(成功):容器通过了诊断。Failure(失败):容器未通过诊断。Unknown(未知):诊断失败,因此不会采取任何行动。
探针可以分为以下三种:
livenessProbe:指示容器是否正在运行。如果存活态探测失败,则 kubelet 会杀死容器, 并且容器将根据其重启策略 决定未来。如果容器不提供存活探针, 则默认状态为 Success。readinessProbe:指示容器是否准备好为请求提供服务。如果就绪态探测失败, 端点控制器将从与 Pod 匹配的所有服务的端点列表中删除该 Pod 的 IP 地址。 初始延迟之前的就绪态的状态值默认为 Failure。 如果容器不提供就绪态探针,则默认状态为 Success。startupProbe: 指示容器中的应用是否已经启动。如果提供了启动探针,则所有其他探针都会被禁用,直到此探针成功为止。如果启动探测失败,kubelet 将杀死容器,而容器依其重启策略 进行重启。 如果容器没有提供启动探测,则默认状态为 Success。
3.4.1 readinessProbe就绪检测
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vim readinessProbe.yaml apiVersion: v1 kind: Pod metadata: name: readiness-httpget-pod namespace: default spec: containers: - name: readiness-httpget-container image: daocloud.io/library/nginx:latest readinessProbe: httpGet: port: 80 path: /test.html initialDelaySeconds: 1 periodSeconds: 3
生成 Pod
1 kubectl create -f readinessProbe.yaml
可以看到虽然 Pod 运行了,但 ready 状态是不对的
进入容器创建文件,问题即可解决
1 2 kubectl exec -it readiness-httpget-pod -- /bin/sh echo 'this is test' > /usr/share/nginx/html/test.html
3.4.2 livenessProbe存活检测 livenessProbe-exec
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 vim livenessProbe_exec.yaml apiVersion: v1 kind: Pod metadata: name: liveness-exec-pod namespace: default spec: containers: - name: liveness-exec-container image: busybox command: ['sh' ,'-c' ,'touch /tmp/test; sleep 60; rm -rf /tmp/test; sleep 3600' ] imagePullPolicy: IfNotPresent livenessProbe: exec: command: ['test' ,'-e' ,'/tmp/test' ] initialDelaySeconds: 1 periodSeconds: 3
生成 Pod
1 kubectl create -f livenessProbe.yaml
可以看到当 test 文件给删除的时候,Pod 就会重启,重启后又会有 test 文件,一直循环下去
livenessProbe-httpget
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 vim livenessProbe_httpget.yaml apiVersion: v1 kind: Pod metadata: name: liveness-httpget-pod namespace: default spec: containers: - name: liveness-httpget-container image: daocloud.io/library/nginx:latest ports: - name: http containerPort: 80 livenessProbe: httpGet: port: http path: /index.html initialDelaySeconds: 1 periodSeconds: 3 timeoutSeconds: 10
创建容器,可以看到是在正常运行的
1 kubectl create -f livenessProbe_httpget.yaml
删除 index.html 文件,可以看到会执行重启
1 2 kubectl exec -it liveness-httpget-pod -- /bin/sh rm -rf /usr/share/nginx/html/index.html
livenessProbe-tcp
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vim livenessProbe_tcp.yaml apiVersion: v1 kind: Pod metadata: name: liveness-tcp-pod namespace: default spec: containers: - name: liveness-tcp-container image: daocloud.io/library/nginx:latest livenessProbe: initialDelaySeconds: 5 timeoutSeconds: 1 tcpSocket: port: 8080 periodSeconds: 3
生成 Pod,会发现一直处于重启状态
1 kubectl create -f livenessProbe_tcp.yaml
3.4.3 Start 和 Stop Start 和 Stop 是指 Pod 在生成后执行和结束前执行的命令
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 vim start_stop.yml apiVersion: v1 kind: Pod metadata: name: start-stop-pod namespace: default spec: containers: - name: start-stop-container image: daocloud.io/library/nginx:latest lifecycle: postStart: exec: command: ['/bin/sh' ,'-c' ,'echo this is postStart test > /usr/share/message' ] preStop: exec: command: ['/bin/sh' ,'-c' ,'echo this is preStop test > /usr/share/message' ]
生成 Pod,进入 Pod 可以看到 Start 执行的命令,由于 Pod 停止后就没有了,所以看不到 Stop 执行的命令
1 kubectl exec -it start-stop-pod -- /bin/sh
四、k8s控制器 4.1 什么是控制器 k8s 中内置了很多 controller,用来控制 Pod 的具体状态和行为。
控制器的类型有:
ReplicationController(已弃用) 和 ReplicaSet
Deployment
DaemonSet
StateFulSet
Job 和 CronJob
Horizontal Pod Autoscaling
4.2 RS 与 Deployment k8s 管理 Pod 主要用到以下三个组件:
Replication Controller(RC):用来确保容器应用的副本数始终保持在用户定义的副本数,如果有容器异常退出,会自动创建新的 Pod 来代替,如果有异常多出的容器也会自动回收。
ReplicaSet(RS):相比 RC 多了支持 selector,推荐使用 RS。
Deployment:用来管理 RS。
RS 单独使用
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 vim rs_test.yaml apiVersion: apps/v1 kind: ReplicaSet metadata: name: rs-test spec: replicas: 3 selector: matchLabels: tier: rs-test template: metadata: labels: tier: rs-test spec: containers: - name: rs-nginx-container image: daocloud.io/library/nginx:latest
生成 RS,可以看到会根据 replicas设置的数量创建 Pod
1 kubectl create -f rs_test.yaml
删除这些 Pod,RS 也会按照副本数重新建立新的 Pod
1 kubectl delete pod --all
RS 与 Deployment
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vim nginx_deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment spec: replicas: 3 selector: matchLabels: app: nginx-deployment template: metadata: labels: app: nginx-deployment spec: containers: - name: nginx-deployment-container image: daocloud.io/library/nginx:latest ports: - containerPort: 80
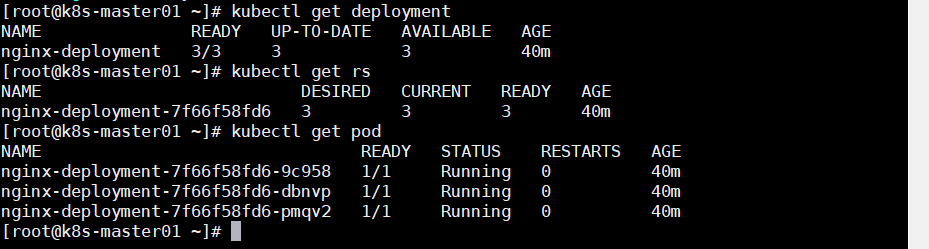
生成 Deployment
1 2 kubectl create -f nginx_deployment.yaml --record record:记录命令,方便每次 reversion 的变化
可以看到会生成对应的 RS 和 Pod
扩容
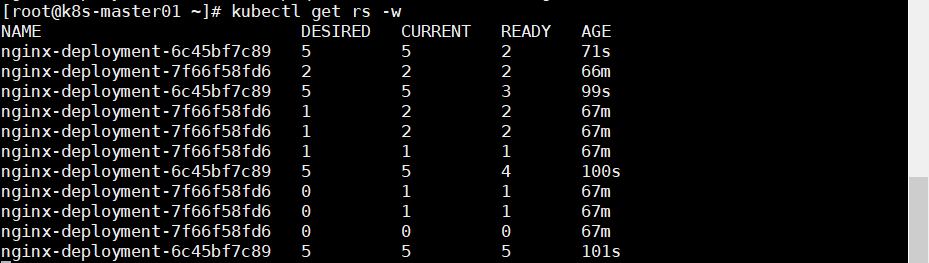
1 kubectl scale deployment nginx-deployment --replicas 5
更新镜像
1 kubectl set image deployment/nginx-deployment nginx-deployment-container=daocloud.io/library/nginx:1.19.1
可以看到会创建一个新的 RS,以实现灰度更新
回滚
1 kubectl rollout undo deployment/nginx-deployment
查看回滚状态
1 kubectl rollout status deployment/nginx-deployment
查看历史版本
1 kubectl rollout history deployment/nginx-deployment
回到历史指定版本
1 kubectl rollout undo deployment/nginx-deployment --to-revision=1
暂停更新
1 kubectl rollout pause deployment/nginx-deployment
4.3 DaemonSet DaemonSet 确保全部或者一部分 Node 上运行一个 Pod 的副本,当有 Node 加入集群时,也会为他们新增一个 Pod,当这些 Node 退出集群时,这些 Pod 也会被回收。
DaemonSet 的一些典型用法:
运行集群存储 daemon,例如在每个 Node 上运行 glusterd、ceph等。
运行日志收集daemon,例如fluentd、logstash等。
运行监控daemon,例如 Prometheus 的 Node exporter、zabbix等。
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 vim daemonset_test.yaml apiVersion: apps/v1 kind: DaemonSet metadata: name: daemonset-test labels: app: daemonset-nginx spec: selector: matchLabels: name: daemonset-nginx template: metadata: labels: name: daemonset-nginx-pod spec: containers: - name: daemonset-nginx-container image: daocloud.io/library/nginx:latest
生成 DaemonSet
1 kubectl create -f daemonset_test.yaml
删除一个 Pod 之后 DaemonSet 为保证每个节点都至少有一个副本,就会重新创建新的 Pod
4.4 Job 和 CronJob 4.4.1 Job Job 负责批处理任务,即仅执行一次的任务,它保证批处理任务的一个或多个 Pod 成功结束。
Job spec
spec.template格式同 Pod 相同
RestartPolicy仅支持Never和OnFailure
单个 Pod 时,默认 Pod 成功运行后 Job 即结束
spec.completions标志 Job 结束时需要成功运行的 Pod 个数,默认为1
spec.parallelism标志并行运行的 Pod 个数,默认为1
spec.activeDeadlineSeconds标志失败 Pod 的重试最大时间,超过该时间就不会再重试
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 vim job.yaml apiVersion: batch/v1 kind: Job metadata: name: job spec: template: metadata: name: job-pod spec: containers: - name: job-pod-container image: perl imagePullPolicy: IfNotPresent command: ['perl' ,'-Mbignum=bpi' ,'-wle' ,'print bpi(2000)' ] restartPolicy: Never
生成 Job,可以看到开始是 Running,接着就是 Completed,代表 Job 已经完成
1 kubectl create -f job.yaml
查看日志可以看到计算好的圆周率
4.4.2 CronJob Cron Job 是基于时间管理控制 Job,即在给定的时间只运行一次、周期性的在指定时间运行。
CronJob spec
所有 CronJob 的 schedule: 时间都是基于 kube-controller-manager 的时区。
.spec.schedule 是 .spec 需要的域。它使用了 Cron 格式串,例如 0 * * * * or @hourly ,做为它的任务被创建和执行的调度时间。.spec.jobTemplate是任务的模版,是必须项。.spec.startingDeadlineSeconds 域是可选项。它表示任务如果由于某种原因错过了调度时间,开始该任务的截止时间的秒数。过了截止时间,CronJob 就不会开始任务。 不满足这种最后期限的任务会被统计为失败任务。如果该域没有声明,那任务就没有最后期限。.spec.suspend域也是可选的。如果设置为 true ,后续发生的执行都会挂起。 这个设置对已经开始的执行不起作用。默认是关闭的。.spec.successfulJobsHistoryLimit 和 .spec.failedJobsHistoryLimit是可选的。 这两个字段指定应保留多少已完成和失败的任务。 默认设置为3和1。限制设置为0代表相应类型的任务完成后不会保留。
并发性规则
.spec.concurrencyPolicy声明了 CronJob 创建的任务执行时发生重叠如何处理。 spec 仅能声明下列规则中的一种:
Allow (默认):CronJob 允许并发任务执行。Forbid: CronJob 不允许并发任务执行;如果新任务的执行时间到了而老任务没有执行完,CronJob 会忽略新任务的执行。Replace:如果新任务的执行时间到了而老任务没有执行完,CronJob 会用新任务替换当前正在运行的任务。
并发性规则仅适用于相同 CronJob 创建的任务。如果有多个 CronJob,它们相应的任务总是允许并发执行的。
编写 yaml 文件
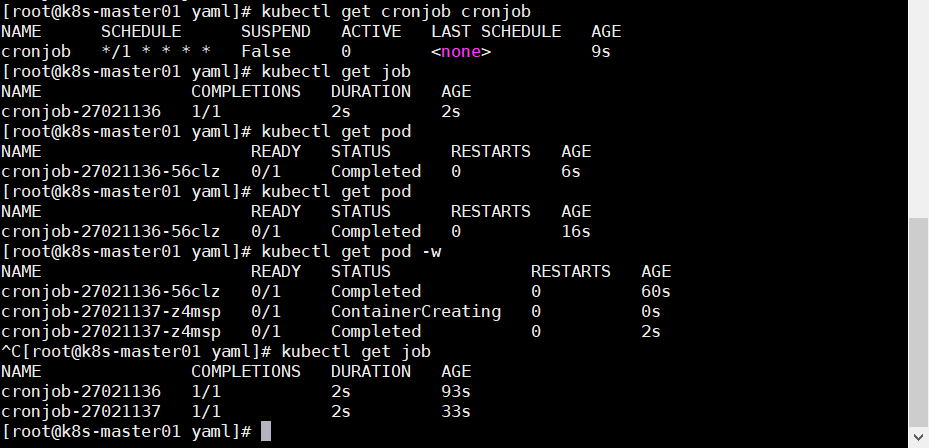
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 vim crontjob.yaml apiVersion: batch/v1 kind: CronJob metadata: name: cronjob spec: schedule: "*/1 * * * *" jobTemplate: spec: template: spec: containers: - name: crontab-pod image: busybox imagePullPolicy: IfNotPresent command: - /bin/sh - -c - date; echo 'Welcome My K8s' restartPolicy: OnFailure
生成 CronJob,可以看到每分钟都会创建一个 Job 和 Pod
1 kubectl create -f cronjob.yaml
五、Service 5.1 什么是Service
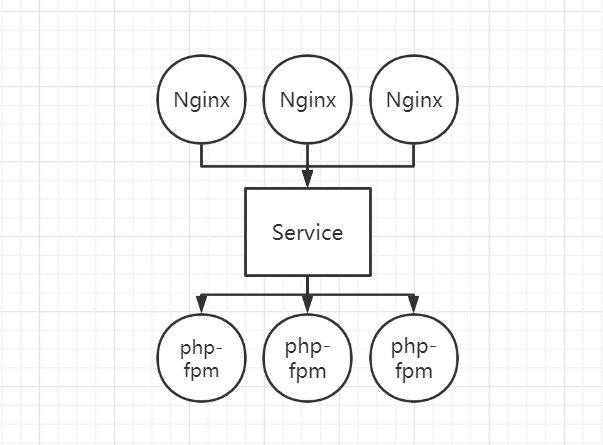
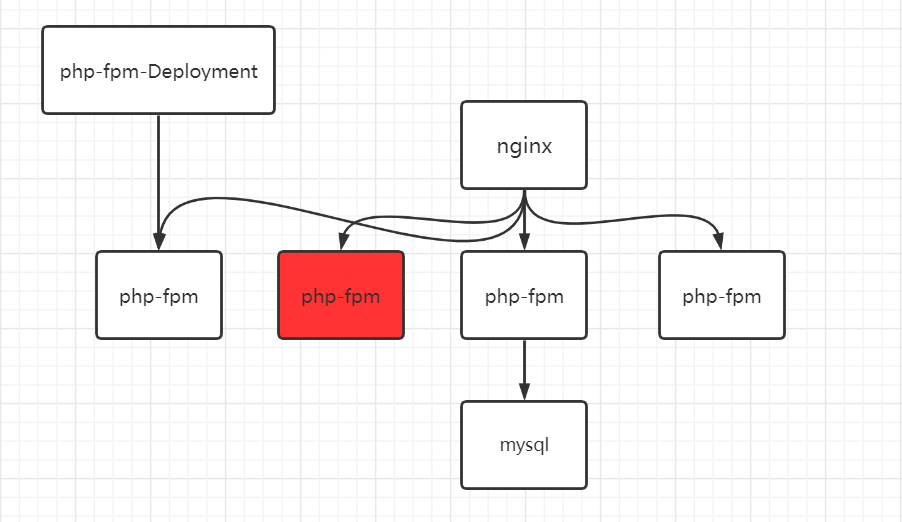
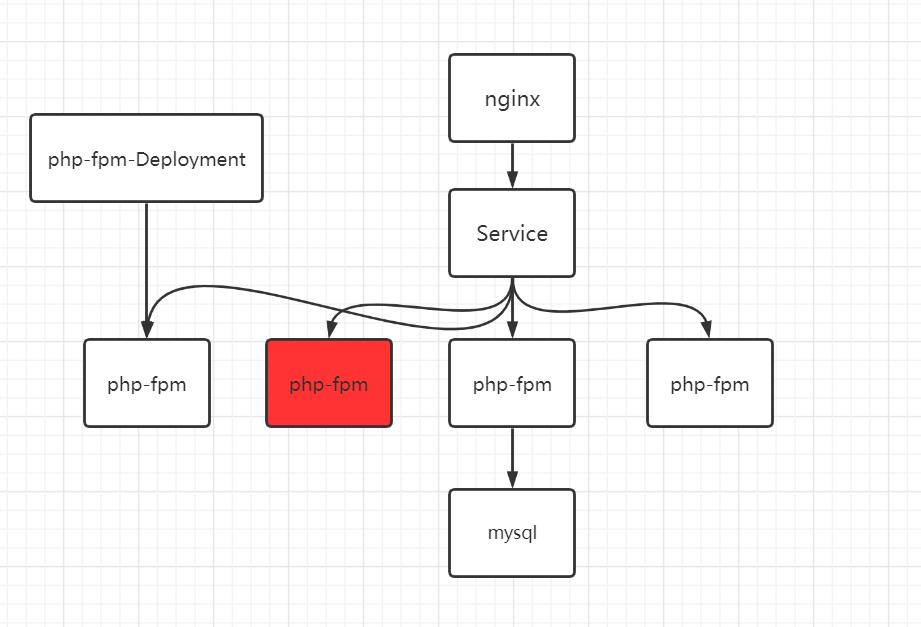
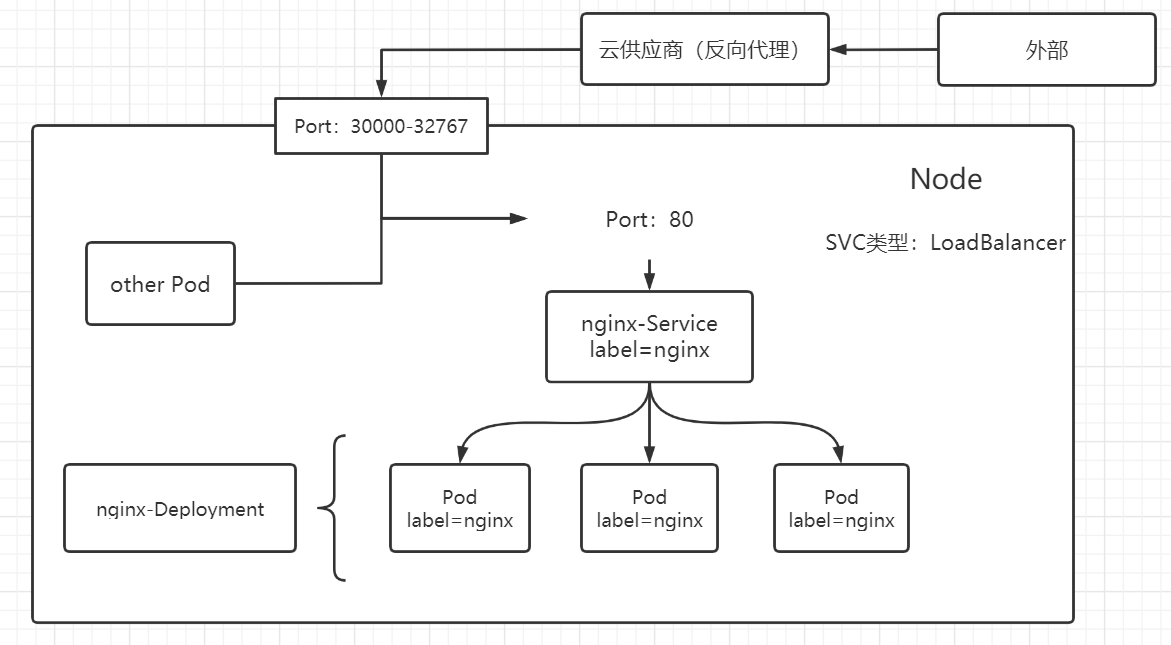
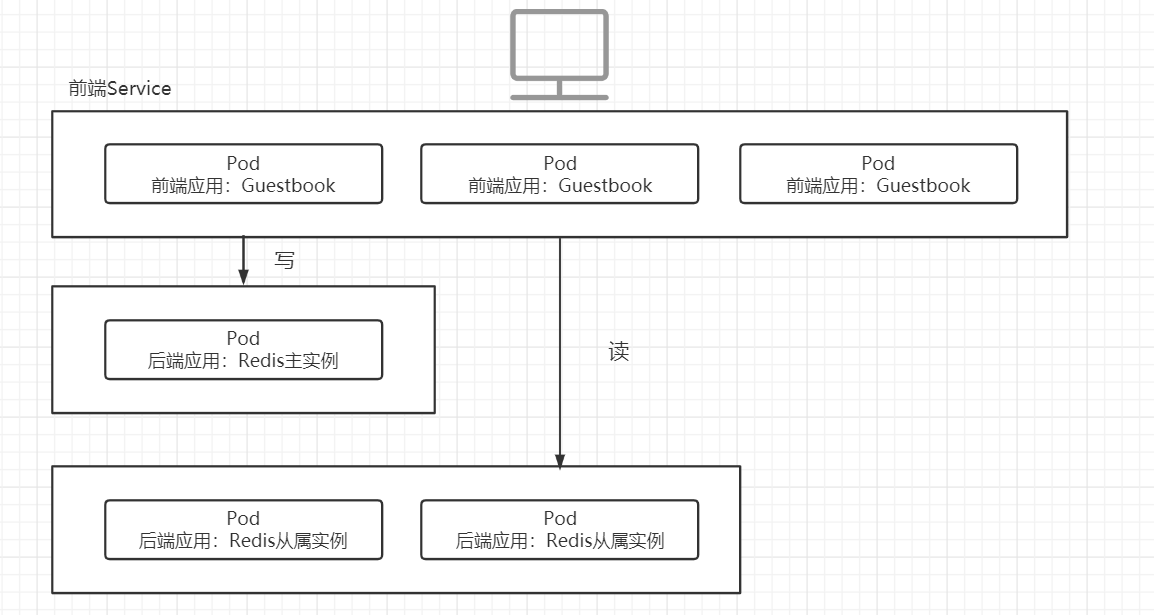
到这里我们都知道,Deployment 会根据 replicas保证 Pod 的数量,当上图的其中一个 php-fpm Pod 出现问题时,就会新建一个来代替。但这时候会会出现一个问题,新的 Pod 的地址与旧的很可能不一样,那 nginx 也无法连接到新的 Pod,除非修改 nginx 的配置,这样的 k8s 集群效率是非常低的。
Service 就能解决该问题,在 nginx 和 php-fpm 中间添加一个 Service,由该 Service 来管理各 php-fpm Pod 的信息,每个 Pod 会设置一个标签,只要与 SVC 中设置的标签相匹配,就可以进行管理,其它 Pod(例如下图的 nginx)想要访问该 SVC 管理的 Pod,只要通过 SVC 的地址就可以访问到。
Service 定义了这样一种抽象:逻辑上的一组 Pod,一种可以访问它们的策略 —— 通常称为微服务。
5.2 Service发布服务(服务类型) 对一些应用的某些部分(如前端),可能希望将其暴露给 Kubernetes 集群外部 的 IP 地址。
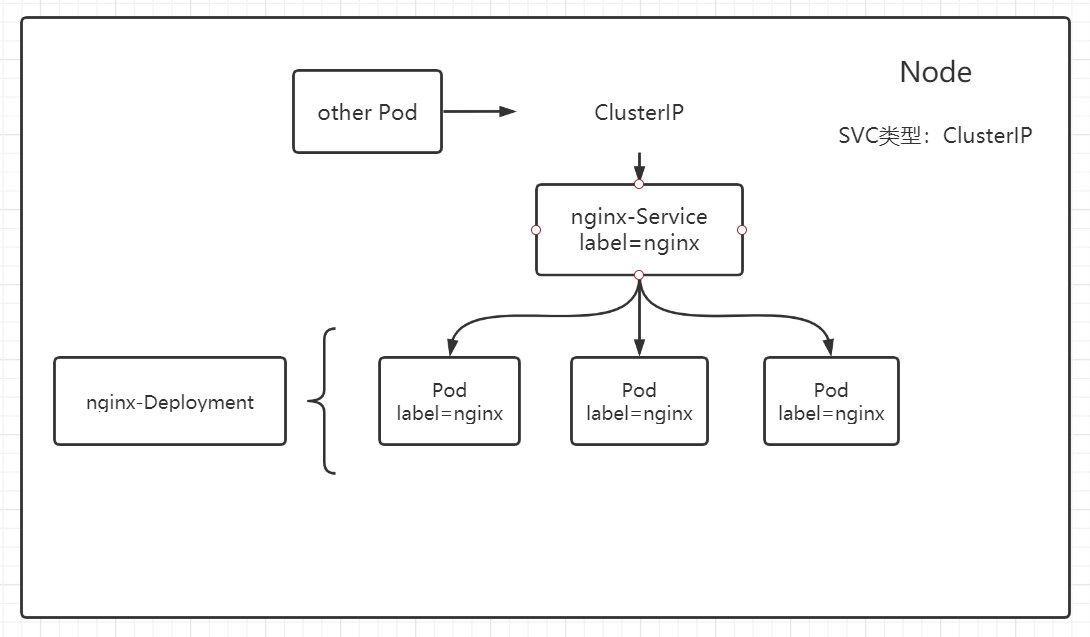
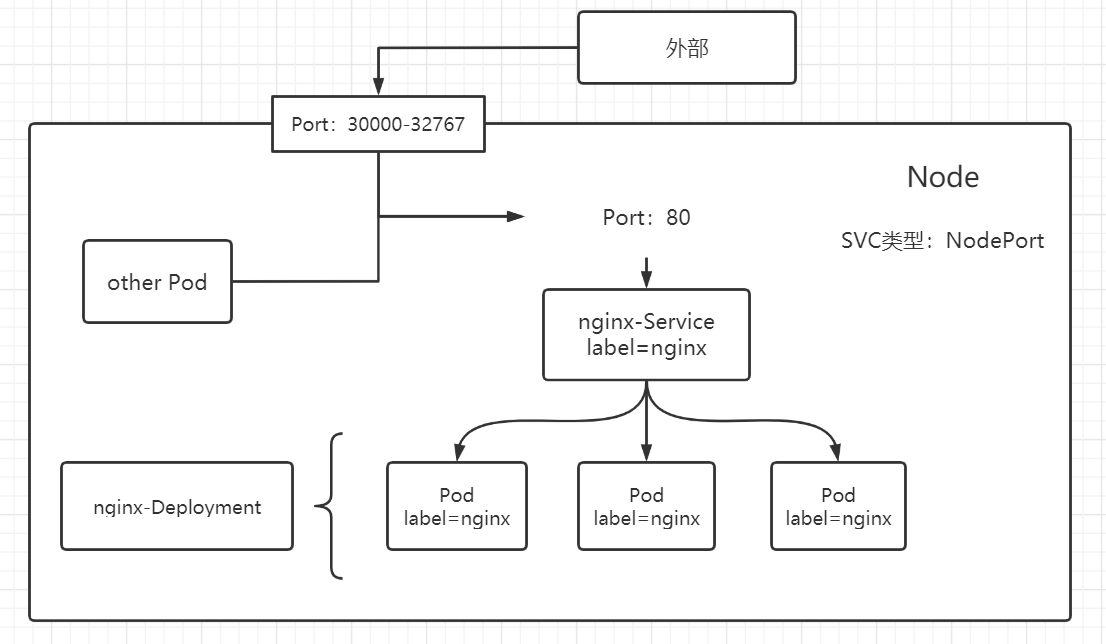
Kubernetes ServiceTypes 允许指定你所需要的 Service 类型,默认是 ClusterIP。
Type 的取值以及行为如下:
ClusterIP:通过集群的内部 IP 暴露服务,选择该值时服务只能够在集群内部访问。 这也是默认的 ServiceType。NodePortNodePort)暴露服务。 NodePort 服务会路由到自动创建的 ClusterIP 服务。 通过请求 <节点 IP>:<节点端口>,你可以从集群的外部访问一个 NodePort 服务。LoadBalancerNodePort 服务和 ClusterIP 服务上。ExternalNameCNAME 和对应值,可以将服务映射到 externalName 字段的内容(例如,foo.bar.example.com)。 无需创建任何类型代理。
ClusterIP
NodePort
LoadBalancer
ExternalName
5.3 虚拟 IP 和 Service 代理 在 Kubernetes 集群中,每个 Node 运行一个 kube-proxy 进程。 kube-proxy 负责为 Service 实现了一种 VIP(虚拟 IP)的形式,而不是 ExternalName
代理模式分类:
userspace 代理模式
在该模式下,所有操作都要通过 kube-proxy 进行一个代理的操作,kube-proxy 的压力相对会较大。
iptables 代理模式
在该模式下,所有的访问都通过 iptables 来处理,kube-proxy 的压力就会减小很多。
IPVS 代理模式
在该模式下,iptables 换成了 IPVS,通过内核模块来实现负载均衡。
在 ipvs 模式下,kube-proxy 监视 Kubernetes 服务和端点,调用 netlink 接口相应地创建 IPVS 规则, 并定期将 IPVS 规则与 Kubernetes 服务和端点同步。 该控制循环可确保 IPVS 状态与所需状态匹配。访问服务时,IPVS 将流量定向到后端Pod之一。
IPVS代理模式基于类似于 iptables 模式的 netfilter 挂钩函数, 但是使用哈希表作为基础数据结构,并且在内核空间中工作。 这意味着,与 iptables 模式下的 kube-proxy 相比,IPVS 模式下的 kube-proxy 重定向通信的延迟要短,并且在同步代理规则时具有更好的性能。 与其他代理模式相比,IPVS 模式还支持更高的网络流量吞吐量。
IPVS 提供了更多选项来平衡后端 Pod 的流量。 这些是:
rr:轮替(Round-Robin)lc:最少链接(Least Connection),即打开链接数量最少者优先dh:目标地址哈希(Destination Hashing)sh:源地址哈希(Source Hashing)sed:最短预期延迟(Shortest Expected Delay)nq:从不排队(Never Queue)
注意:当 kube-proxy 以 IPVS 代理模式启动时,它将验证 IPVS 内核模块是否可用。 如果未检测到 IPVS 内核模块,则 kube-proxy 将退回到以 iptables 代理模式运行。
5.4 ClusterIP ClusterIP 主要在每个 Node 节点使用 iptables / IPVS,将发向 ClusterIP 对应端口的数据,转发到 kube-proxy 中,kube-proxy 内部可以实现负载均衡,并可以查询到该 Service 下对应 Pod 的地址和端口,进而把数据转发给对应的 Pod 的地址和端口。
示例
创建 Deployment
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vim nginx_svc_deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment namespace: default spec: replicas: 3 selector: matchLabels: app: nginx version: latest template: metadata: labels: app: nginx version: latest spec: containers: - name: nginx-pod image: daocloud.io/library/nginx:latest ports: - name: http-port containerPort: 80
创建 Service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vim clusterip_svc.yaml apiVersion: v1 kind: Service metadata: name: nginx-clusterip-service namespace: default spec: type: ClusterIP selector: app: nginx version: latest ports: - name: http-port port: 80 targetPort: 80
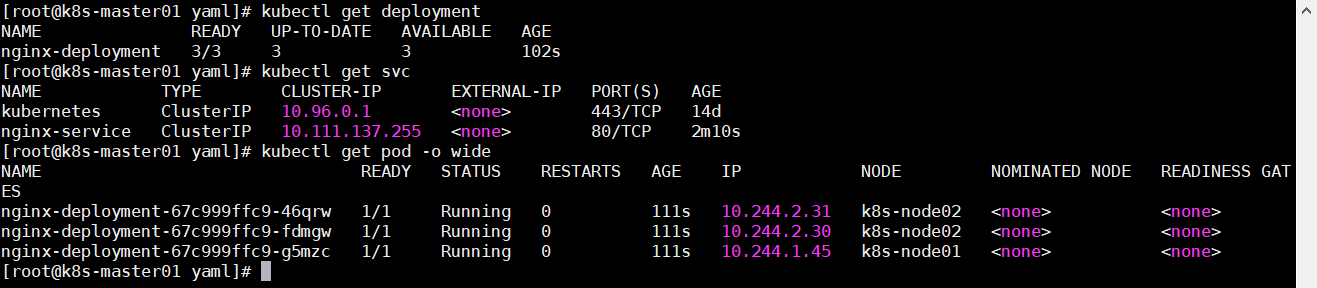
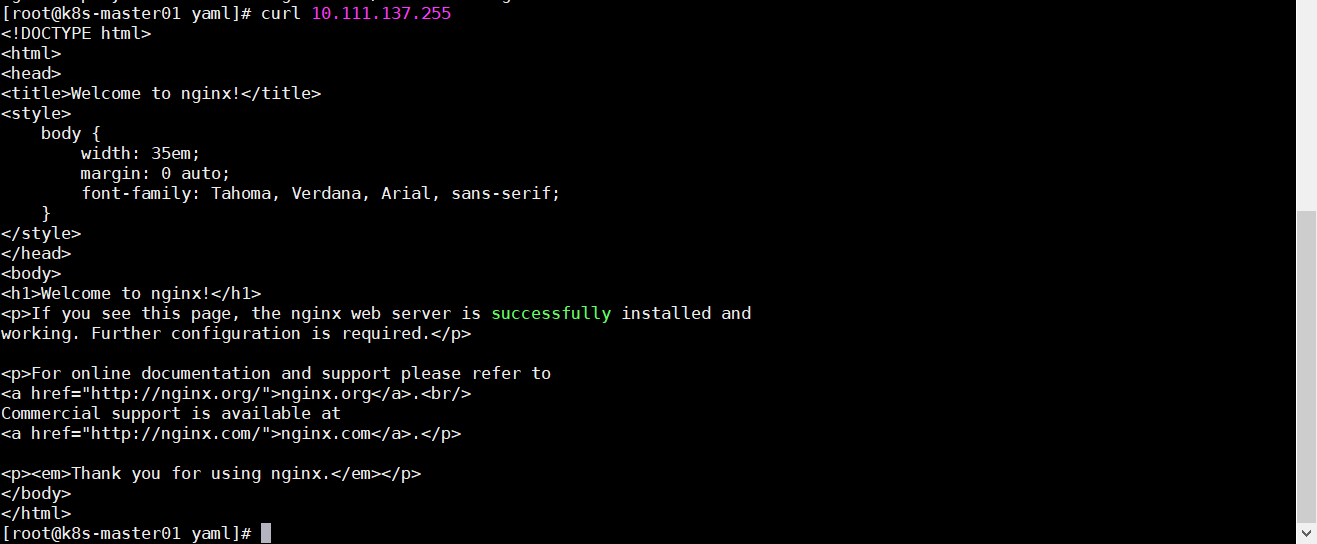
可以看到 Deployment 和 SVC 都已经创建成功,且直接访问 SVC 的 ClusterIP 地址就可以访问到 Pod 了
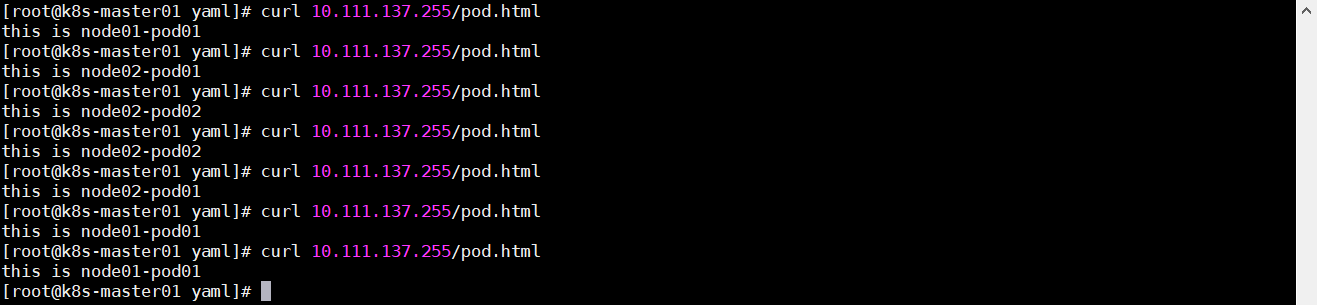
测试负载均衡,在各容器内部创建一个 html 页面
1 2 3 4 kubectl exec -it nginx-deployment-*** -- /bin/bash echo 'this is node01-pod01' > /usr/share/nginx/html/pod.html echo 'this is node02-pod01' > /usr/share/nginx/html/pod.html ...
可以看到是实现了负载均衡的
5.5 无头服务(Headless Services) 有时不需要或不想要负载均衡,以及单独的 Service IP。 遇到这种情况,可以通过指定 Cluster IP(spec.clusterIP)的值为 "None" 来创建 Headless Service。
可以使用无头 Service 与其他服务发现机制进行接口,而不必与 Kubernetes 的实现捆绑在一起。
对这无头 Service 并不会分配 Cluster IP,kube-proxy 不会处理它们, 而且平台也不会为它们进行负载均衡和路由。 DNS 如何实现自动配置,依赖于 Service 是否定义了选择算符。
示例
创建 Headless Service
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vim headless_service.yaml apiVersion: v1 kind: Service metadata: name: headless-service namespace: default spec: selector: app: nginx version: latest clusterIP: "None" ports: - port: 80 targetPort: 80
可以看到是没有分配 VIP 的
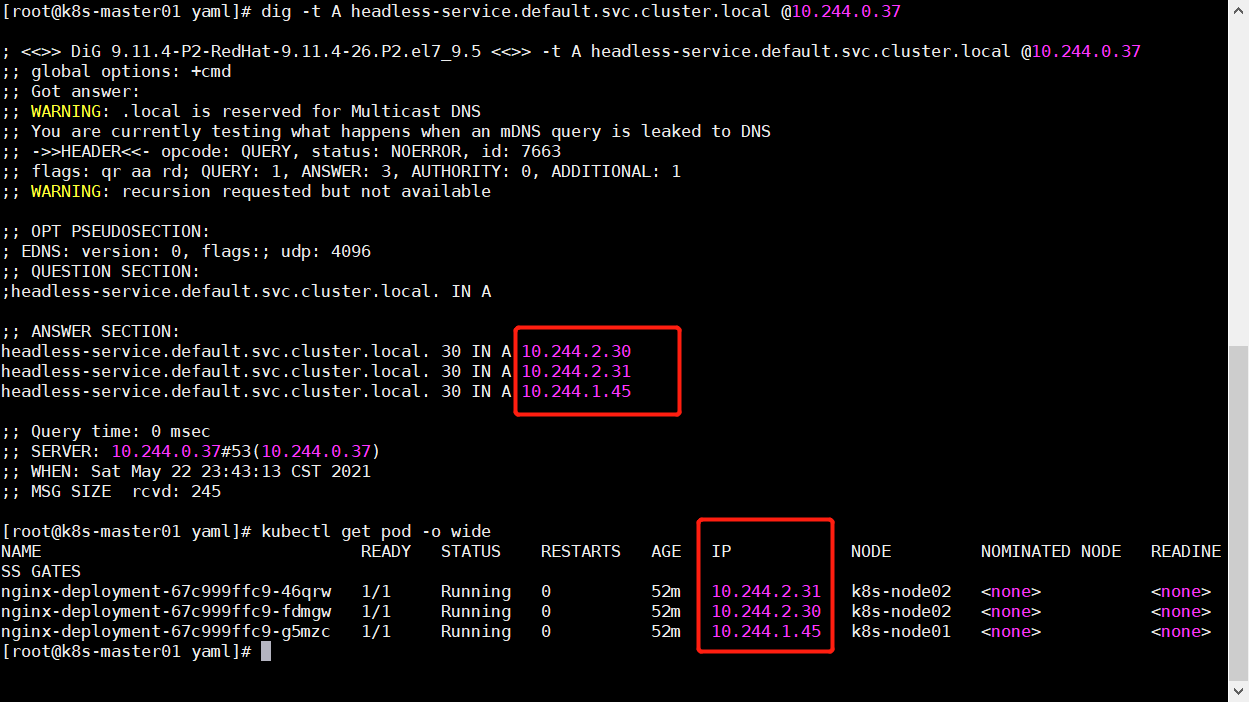
安装 bind-utils 工具来测试无头服务的作用,可以看到即使没有了 VIP,但依旧可以通过域名来访问到不同的 Pod
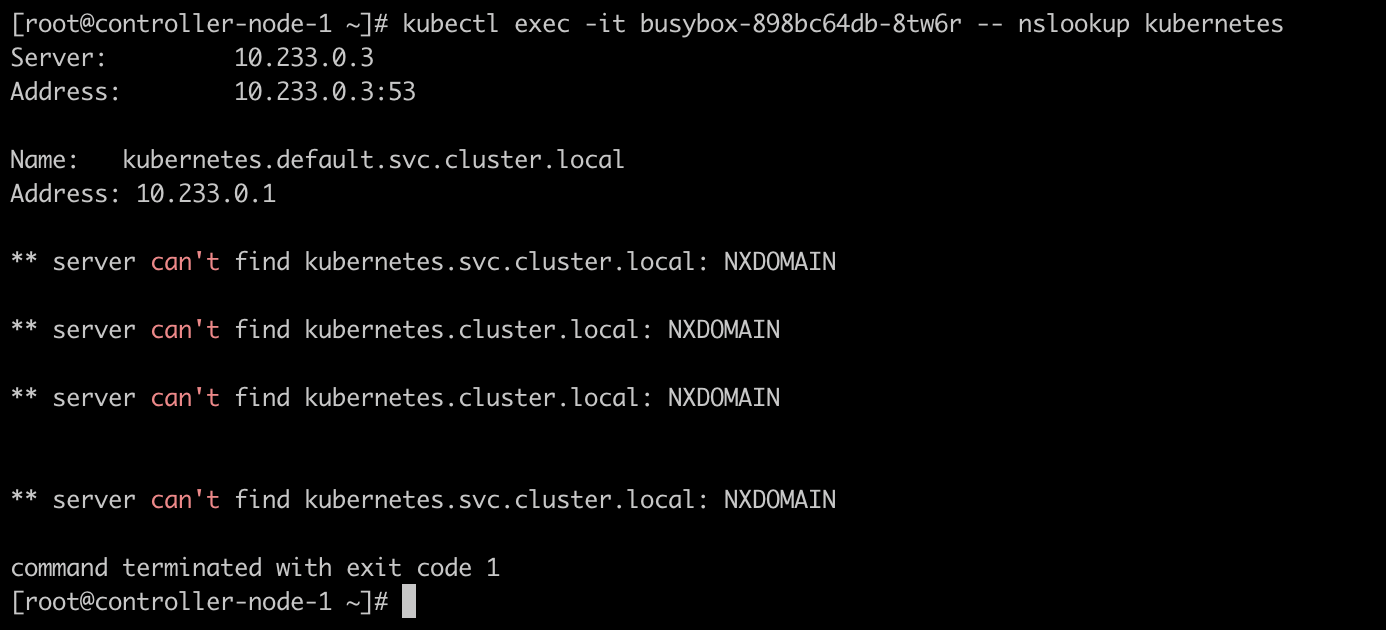
1 2 3 4 5 6 yum -y install bind-utils # k8s内部使用dns访问格式:SVC名称.命名空间.svc.集群域(默认集群域为cluster.local) # dig命令可以用来获取域名的详细信息 # 10.244.0.37是其中一个coredns的地址 # -t A:显示A记录,A记录是将域名指向一个IPv4地址,即一个域名解析到一个IP地址 dig -t A headless-service.default.svc.cluster.local @10.244.0.37
5.6 NodePort NodePort 的原理在于在 Node 上开放了一个端口,将该端口的流量导入到 kube-proxy 中,然后再由 kube-proxy 传送给不同的 Pod。
示例
创建 Service,这里的标签仍与上面 ClusterIP 中的 Deployment 创建的 Pod 相匹配
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 vim nodeport_svc.yaml apiVersion: v1 kind: Service metadata: name: nginx-nodeport-service namespace: default spec: type: NodePort selector: app: nginx version: latest ports: - name: http-port port: 80 targetPort: 80
可以看到会暴露一个端口,外部通过这个端口就可以访问到内部的 Pod,且是每一个 Node 都开启了这个端口,所以也可以实现负载均衡
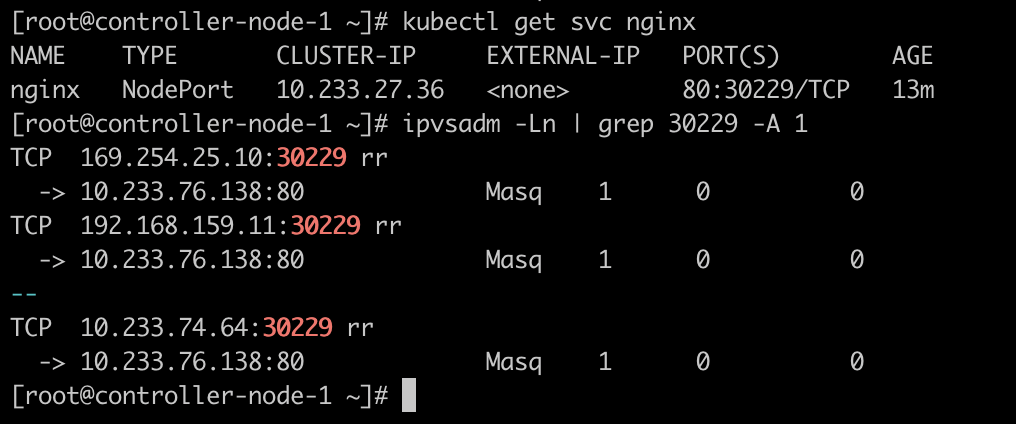
在 iptables / IPVS 规则中可以看到开启该端口的规则
1 2 iptables -t nat -nvl | grep 31419 ipvsadm -Ln | grep 31419
5.7 LoadBalancer LoadBalancer 就是在 NodePort 的基础上,通过 LAAS 来实现负载均衡,用户指要访问 LAAS即可,LAAS 会将请求通过调度转发给不同的 Node。
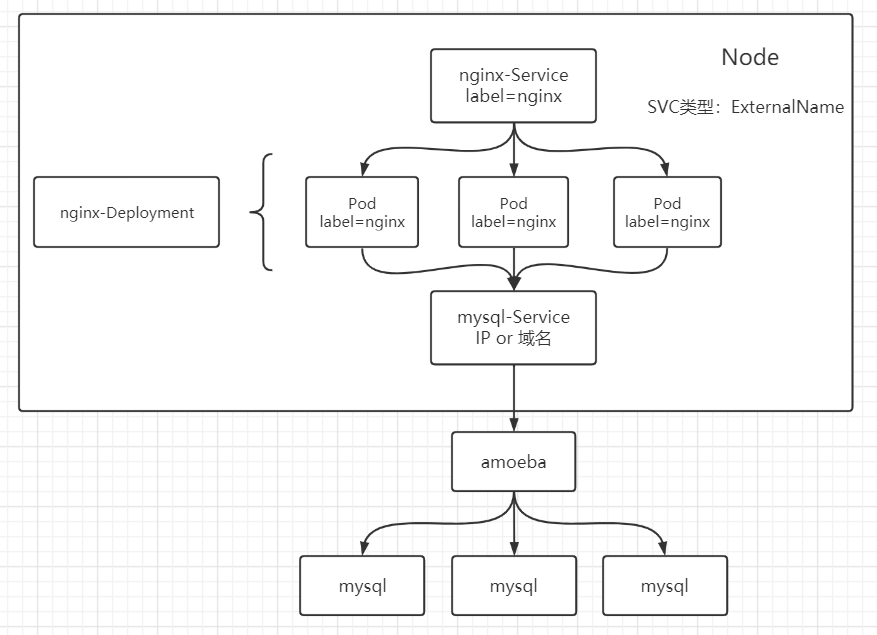
5.8 ExternalName ExternalName 通过返回 CNAME 和它的值,将服务映射到 ExternalName 字段的内容,ExternalName 没有 selector,也没有端口的设置,对于运行在集群之外的服务,ExternalName 是通过该外部服务的别名来提供服务的。
当这个 Service 创建成功时,就会有 externalname-service.default.svc.cluster.local 的 fqdn 被创建,如果有用户访问到这个 fqdn,就会被改写成 my.database.example.com,这就是 DNS 内部的一个 CNAME 记录,也就是别名记录。
示例
创建测试用的 Pod
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: v1 kind: Pod metadata: name: curl-pod spec: containers: - name: curl-pod-container image: docker.io/appropriate/curl imagePullPolicy: IfNotPresent command: ['sh' , '-c' ] args: ['echo "curl test"; sleep 3600' ]
创建 ExternalName
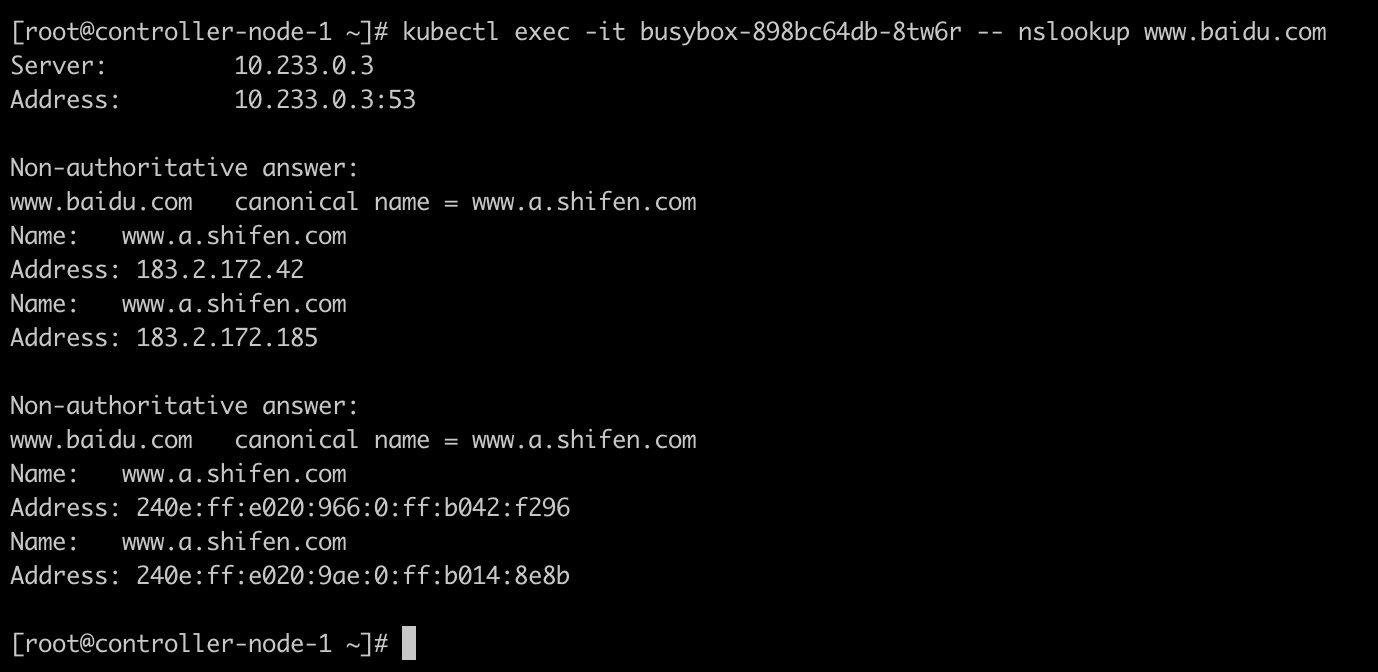
1 2 3 4 5 6 7 8 apiVersion: v1 kind: Service metadata: name: externalname-svc spec: type: externalname externalName: www.baidu.com
进入 Pod 内部测试可以看到,通过 nslookup 可以解析到百度的地址
1 nolookup SVC名称.命名空间.svc.集群域
5.9 ingress 5.9.1 什么是ingress ingress 是对集群中服务的外部访问进行管理的 API 对象,典型的访问方式是 HTTP。
ingress 可以提供负载均衡、SSL 终结和基于名称的虚拟托管。
ingress 由两部分构成:
ingress controller:将新加入的 ingress 转化成 Nginx 的配置文件并使之生效。
ingress 服务:将 Nginx 的配置抽象成一个 ingress 对象,每添加一个新的服务只需写一个新的 ingress 的 yaml 文件即可。
ingress controller 主要有两种,nginx-ingress和traefik-ingress,这里主要讲nginx-ingress。
ingress 官方网址:https://kubernetes.github.io/nginx-ingress
ingress GitHub 网址:https://github.com/kubernetes/nginx-ingress
nginx-ingress功能
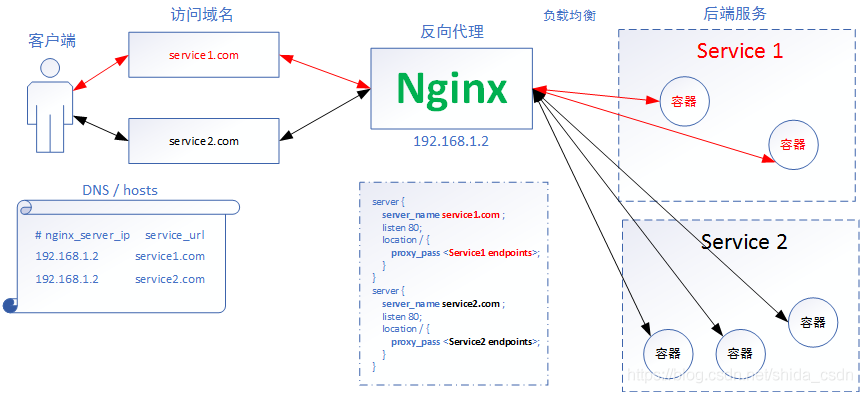
nginx-ingress主要负责向外暴露服务,同时提供负载均衡的功能。
Nginx 对后端运行的服务(Service1、Service2)提供反向代理,在配置文件中配置了域名与后端服务 Endpoints 的对应关系。客户端通过使用 DNS 服务或者直接配置本地的 hosts 文件,将域名都映射到 Nginx 代理服务器。当客户端访问 service1.com 时,浏览器会把包含域名的请求发送给 Nginx 服务器,Nginx 服务器根据传来的域名,选择对应的 Service,这里就是选择 Service1 后端服务,然后根据一定的负载均衡策略,选择 Service1 中的某个容器接收来自客户端的请求并作出响应。过程很简单,Nginx 在整个过程中仿佛是一台根据域名进行请求转发的“路由器”。
nginx-ingress工作过程
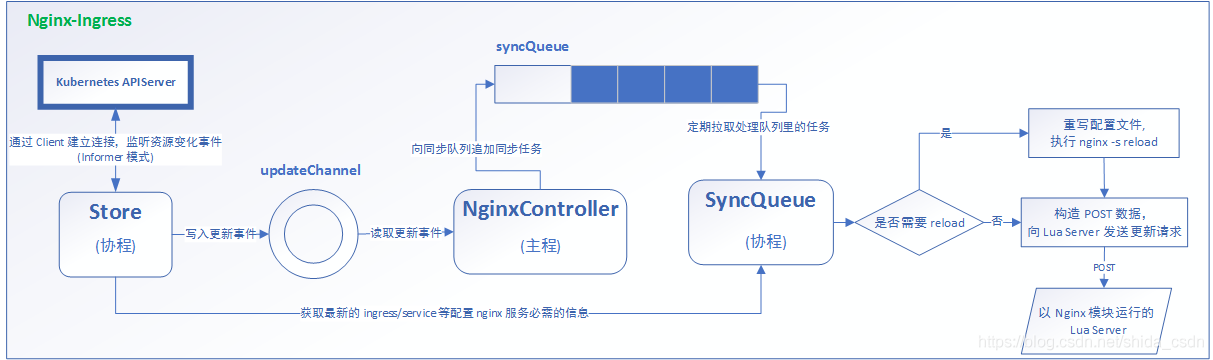
nginx-ingress模块在运行时主要分为三个主体:
Store:Store 会与 APIServer 以协程的 Pod 方式进行一个监听状态,发生新的事件会写入循环队列里。
NginxController:NginxController 会监听循环队列里的事件,发生一个循环就会更新一个事件,并写入 SyncQueue 里。
SyncQueue:SyncQueue 协程会定期拉取需要执行的任务(如果有必要的则直接从 Store 拉取过来进行修改),接着判断是否需要 reload nginx,最后会以 nginx 模块运行。
5.9.2 ingress规则 每个 HTTP 规则都包含以下信息:
可选的 host。在此示例中,未指定 host,因此该规则适用于通过指定 IP 地址的所有入站 HTTP 通信。 如果提供了 host(例如 www.cqm.com),则 rules 适用于该 host。
路径列表 paths(例如,/testpath),每个路径都有一个由 serviceName 和 servicePort 定义的关联后端。 在负载均衡器将流量定向到引用的服务之前,主机和路径都必须匹配传入请求的内容。
backend(后端)是 Service 文档 中所述的服务和端口名称的组合。 与规则的 host 和 path 匹配的对 Ingress 的 HTTP(和 HTTPS )请求将发送到列出的 backend。
路径类型
Ingress 中的每个路径都需要有对应的路径类型(Path Type)。未明确设置 pathType 的路径无法通过合法性检查。当前支持的路径类型有三种:
ImplementationSpecific:对于这种路径类型,匹配方法取决于 IngressClass。 具体实现可以将其作为单独的 pathType 处理或者与 Prefix 或 Exact 类型作相同处理。Exact:精确匹配 URL 路径,且区分大小写。Prefix:基于以 / 分隔的 URL 路径前缀匹配。匹配区分大小写,并且对路径中的元素逐个完成。 路径元素指的是由 / 分隔符分隔的路径中的标签列表。 如果每个 p 都是请求路径 p 的元素前缀,则请求与路径 p 匹配。
5.9.3 部署nginx-ingress
通过 Bare-metal(NodePort) 方式部署,先下载 yaml 文件
1 2 3 4 5 6 7 8 9 # 地址一 # https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.46.0/deploy/static/provider/baremetal/deploy.yaml # 地址二 # https://github.com/kubernetes/ingress-nginx/blob/master/deploy/static/provider/baremetal/deploy.yaml # 由于镜像地址也在国外,所以通过国内镜像源拉取 docker pull registry.aliyuncs.com/google_containers/nginx-ingress-controller:v0.46.0 docker tag registry.aliyuncs.com/google_containers/nginx-ingress-controller:v0.46.0 k8s.gcr.io/ingress-nginx/controller:v0.46.0
获取镜像地址,下载好需要的镜像,并导入镜像到其它 node 上
通过 deploy.yaml 文件生成 svc
1 kubectl create -f deploy.yaml
5.9.4 ingress HTTP代理访问
ingress-nginx会根据配置好的 yaml 文件,自动配置 nginx.conf 和虚拟主机文件。
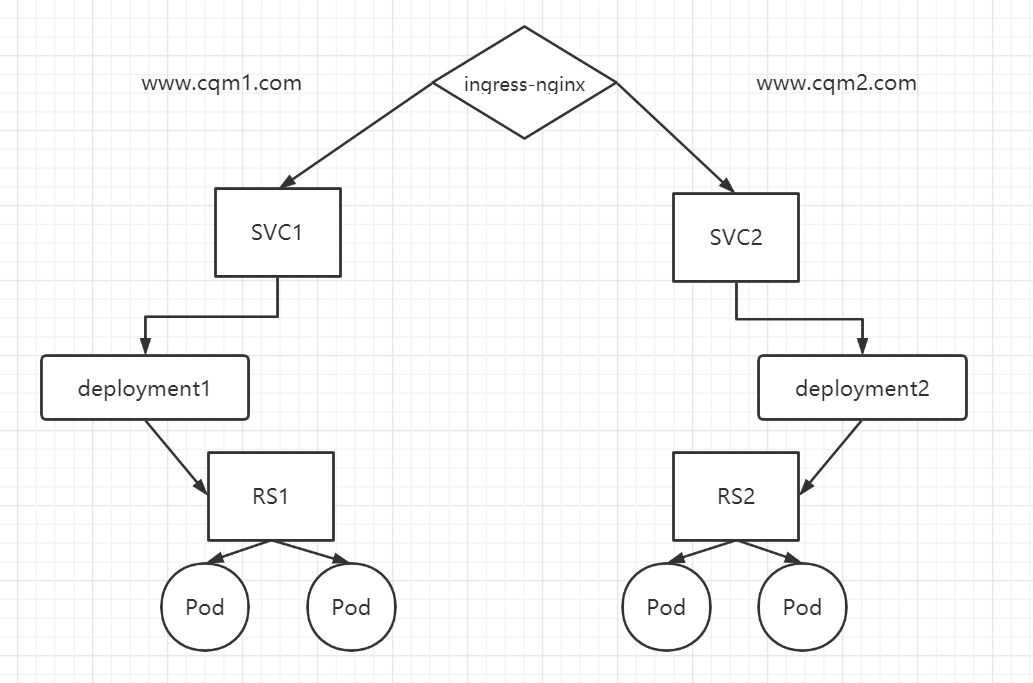
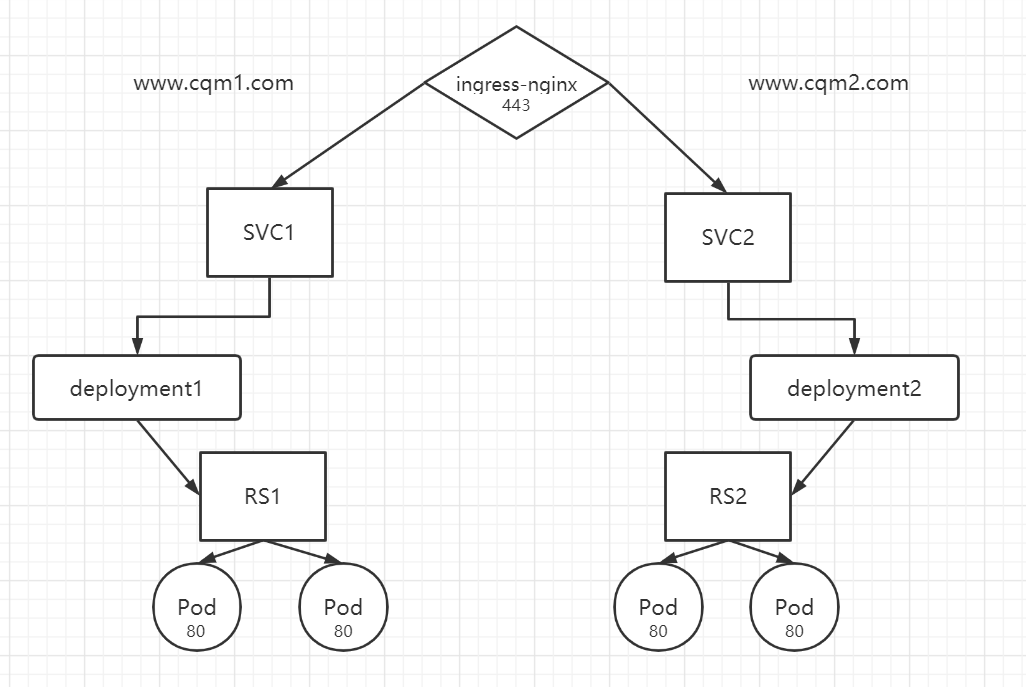
创建 deployment1、deployment2、service1、service2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 vim nginx_deployment_svc1.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment1 spec: replicas: 2 selector: matchLabels: name: nginx1 template: metadata: labels: name: nginx1 spec: containers: - name: nginx-pod image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-service1 spec: ports: - port: 80 targetPort: 80 protocol: TCP selector: name: nginx1
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 vim nginx_deployment_svc2.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment2 spec: replicas: 2 selector: matchLabels: name: nginx2 template: metadata: labels: name: nginx2 spec: containers: - name: nginx-pod image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-service2 spec: ports: - port: 80 targetPort: 80 protocol: TCP selector: name: nginx2
创建 nginx-ingress1、nginx-ingress2
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 vim nginx_ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: nginx-ingress1 spec: rules: - host: www.cqm1.com http: paths: - path: /pod.html pathType: ImplementationSpecific backend: serviceName: nginx-service1 servicePort: 80 --- apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: nginx-ingress2 spec: rules: - host: www.cqm2.com http: paths: - path: /pod.html pathType: ImplementationSpecific backend: service: name: nginx-service2 port: number: 80
创建
1 2 3 kubectl create -f nginx_deployment_svc1.yaml kubectl create -f nginx_deployment_svc2.yaml kubectl create -f nginx_ingress.yaml
给每个 Pod 写入信息,方便查看负载均衡
1 2 kubectl exec -it nginx-deployment-... -- /bin/bash echo 'this is nginx-pod-1' > /usr/share/nginx/html/pod.html
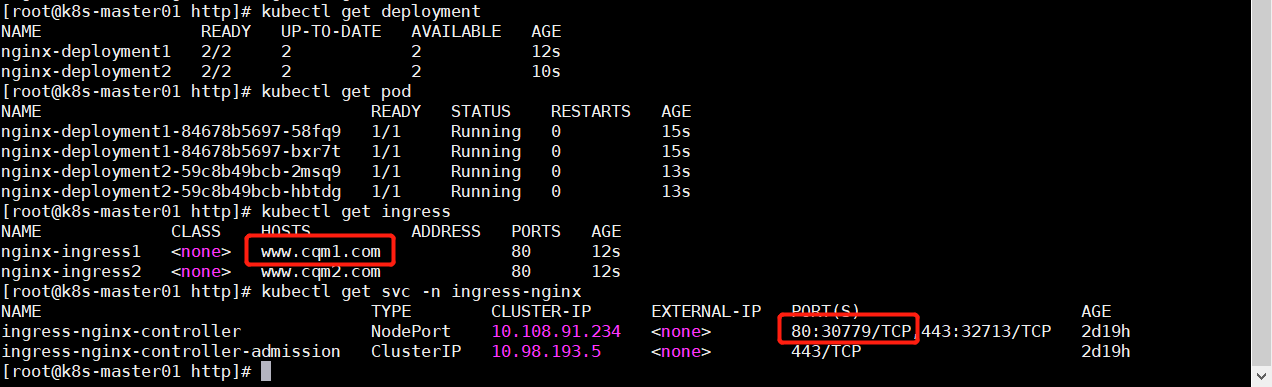
查看 ingress-nginx 所创建的 svc 暴露的端口,以及 service1、service2、nginx-ingress1、nginx-ingress2
1 2 3 kubectl get svc -n ingress-nginx kubectl get svc kubectl get ingress
在 /etc/hosts 文件下写入域名与 IP 绑定,访问测试,可以看到实现了负载均衡
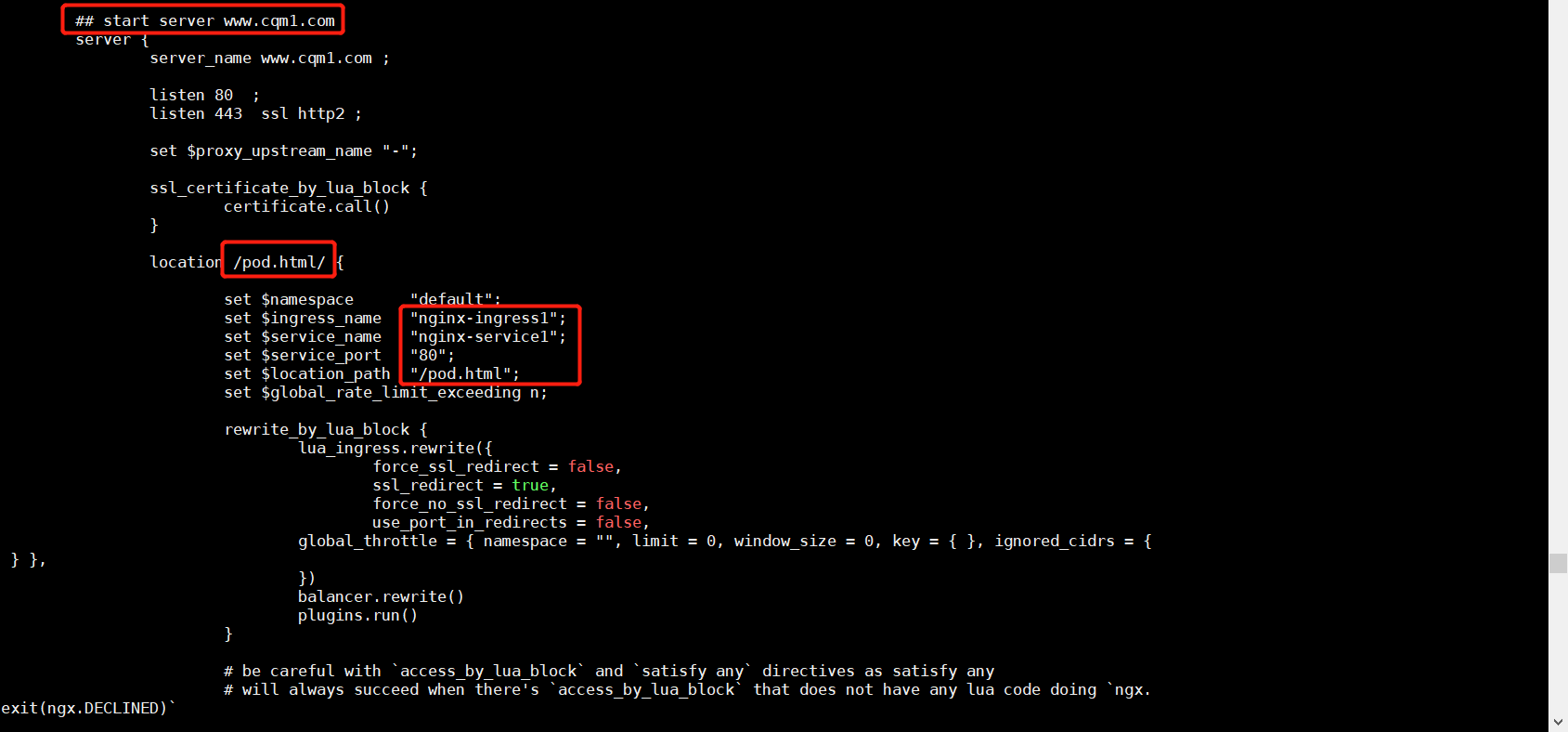
可以进入 ingress 控制器内部查看 nginx 配置,可以看到自动添加的代理配置
1 2 kubectl exec -it -n ingress-nginx ingress-nginx-controller-... -- /bin/bash cat nginx.conf
5.9.5 ingress HTTPS代理访问
创建私钥
1 2 openssl req -x509 -sha256 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=nginxsvc/O=nginxsvc" kubectl create secret tls tls-secret --key tls.key --cert tls.crt
创建 deployment3、service3、nginx-ingress3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 vim nginx_deployment_svc3.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment3 spec: replicas: 2 selector: matchLabels: name: nginx3 template: metadata: labels: name: nginx3 spec: containers: - name: nginx-pod image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent ports: - containerPort: 80 --- apiVersion: v1 kind: Service metadata: name: nginx-service3 spec: ports: - port: 80 targetPort: 80 protocol: TCP selector: name: nginx3
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vim nginx_ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: nginx-ingress3 spec: tls: - hosts: - www.cqm3.com secretName: tls-secret rules: - host: www.cqm3.com http: paths: - path: /pod.html pathType: ImplementationSpecific backend: serviceName: nginx-service3 servicePort: 80
创建
1 kubectl create -f nginx_deployment_svc3.yaml nginx_ingress.yaml
在每个 Pod 写入 pod.html,便于查看负载均衡效果,并测试
1 2 kubectl exec -it ingress-nginx-... -- /bin/bash echo 'this is node01-pod' > /usr/share/nginx/html/pod.html
5.9.5 Nginx进行基础认证(BasicAuth)
通过 Apache 创建用户认证文件
1 2 3 yum -y install httpd htpasswd -c auth cqm kubectl create secret generic basic-auth --from-file=auth
创建 ingress
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 vim nginx_ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: ingress-nginx-auth annotations: nginx.ingress.kubernetes.io/auth-type: basic nginx.ingress.kubernetes.io/auth-secret: basic-auth nginx.ingress.kubernetes.io/auth-realm: 'Authentication Required - cqm' spec: rules: - host: auth.cqm.com http: paths: - path: /pod.html pathType: ImplementationSpecific backend: service: name: nginx-service1 port: number: 80
创建 ingress 后测试
5.9.6 Nginx重写
名称
描述
类型
nginx.ingress.kubernetes.io/rewrite-target
必须重定向流量的目标 URI
string
nginx.ingress.kubernetes.io/ssl-redirect
指示位置部分是否仅可访问 SSL(当 Ingress 包含证书时默认为 True)
bool
nginx.ingress.kubernetes.io/force-ssl-redirect
即使 Ingress 未启用 TLS,也强制重定向到 HTTPS
bool
nginx.ingress.kubernetes.io/app-root
定义控制器必须重定向的应用程序根,如果它在“/”上下文中
string
nginx.ingress.kubernetes.io/use-regex
指示 Ingress 上定义的路径是否使用正则表达式
bool
先准备好转发后的 deployment、ingress等,这里用上边的 ingress1,用户访问 www.rewritecqm.com 时就跳转到 www.cqm1.com
编写重写 ingress
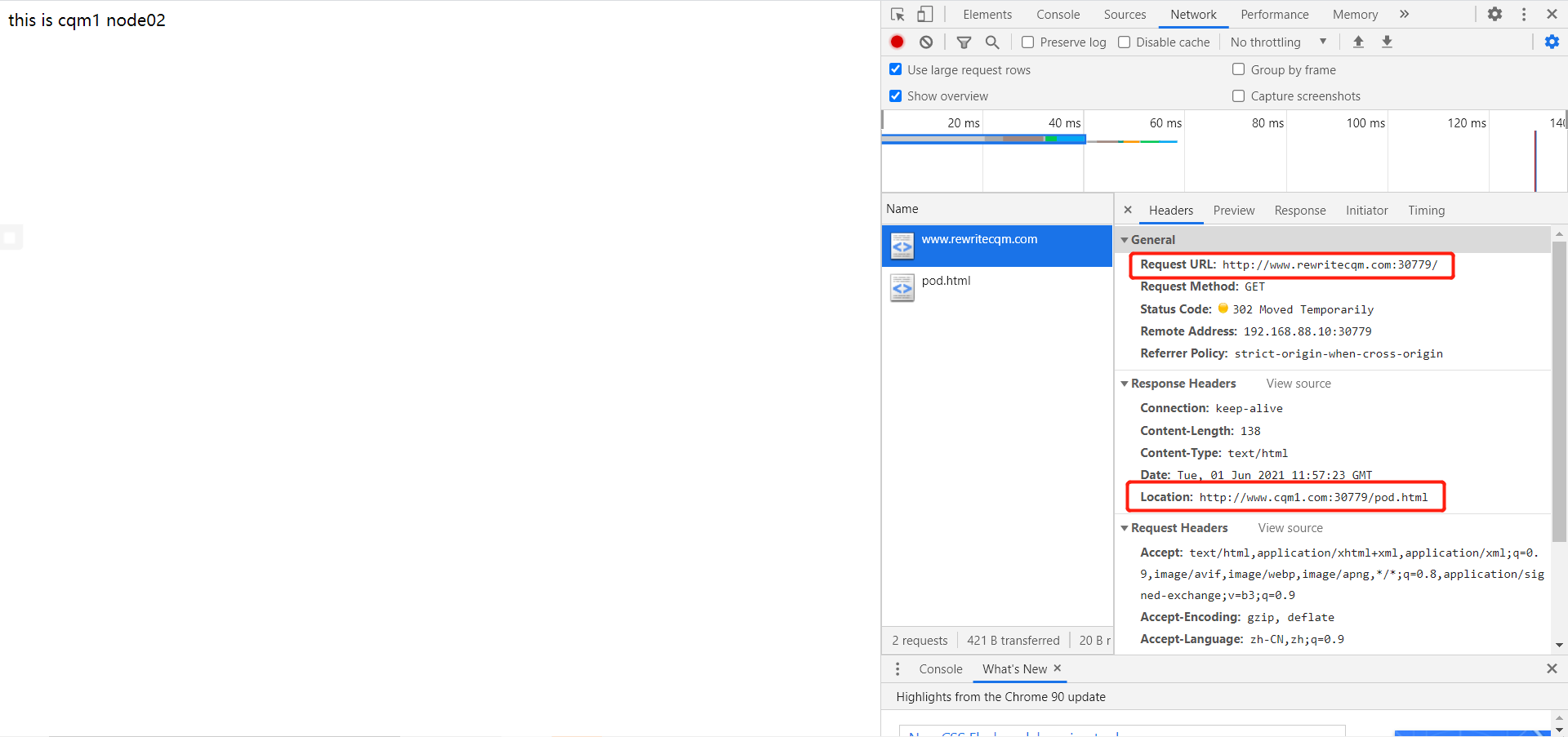
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 vim rewrite_ingress.yaml apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: rewrite-ingress annotations: nginx.ingress.kubernetes.io/rewrite-target: http://www.cqm1.com:30779/pod.html spec: rules: - host: www.rewritecqm.com http: paths: - path: /pod.html pathType: Prefix backend: service: name: nginx-service1 port: number: 80
测试
六、k8s存储 6.1 配置存储卷 配置存储卷并不是用来进行容器间相互交互或 Pod 间数据共享的,而是用于向各个 Pod 注入配置信息的,主要分为以下三种:
ConfigMap:可传递普通信息
Secret:可传递密码等敏感的配置信息
DownwardAPI:可传递 Pod 和容器自身的运行信息
6.1.1 ConfigMap 许多应用程序都会从配置文件、命令行参数或环境变量中读取配置信息。
ConfigMap API 给我们提供了向容器内部注入信息的机制,ConfigMap 可以被用来保存单个属性,也可以用来保存整个配置文件或者 JSON 二进制对象。
ConfigMap 的创建方式有三种,分别为基于目录、文件和字面值来创建。
基于目录创建 ConfigMap
创建指定目录,下载官方测试文件
1 2 3 4 mkdir -p /root/k8s/plugin/configmap/dir || cd /root/k8s/plugin/configmap/dir wget https://kubernetes.io/examples/configmap/game.properties wget https://kubernetes.io/examples/configmap/ui.properties kubectl create configmap configmap1 --from-file=./
查看命令
1 2 kubectl describe cm configmap1 kubectl get cm configmap1 -o yaml
基于文件创建 ConfigMap
通过 game.properties 和 ui.properties 创建
1 kubectl create configmap configmap2 --from-file=game.properties --from-file=ui.properties
基于字面值创建 ConfigMap
通过--from-literal=键名=键值来创建
1 kubectl create configmap configmap3 --from-literal=special.how=very
6.1.1.1 Pod中使用ConfigMap 使用 ConfigMap 代替环境变量
创建两个 ConfigMap
1 2 3 4 5 6 7 8 9 vim special_cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: special-cm namespace: default data: special.how: very special.type: charm
1 2 3 4 5 6 7 8 vim env_cm.yaml apiVersion: v1 kind: ConfigMap metadata: name: env-cm namespace: default data: log_level: INFO
将这两个 ConfigMap 注入到 Pod中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 vim pod1.yaml apiVersion: v1 kind: Pod metadata: name: pod1 spec: containers: - name: pod1-container image: busybox imagePullPolicy: IfNotPresent command: ["/bin/bash" , "-c" , "env" ] env: - name: SPECIAL_HOW_KEY valueFrom: configMapKeyRef: name: special-cm key: special.how - name: SPECIAL_TYPE_KEY valueFrom: configMapKeyRef: name: special-cm key: special.type envFrom: - configMapRef: name: env-cm restartPolicy: Never
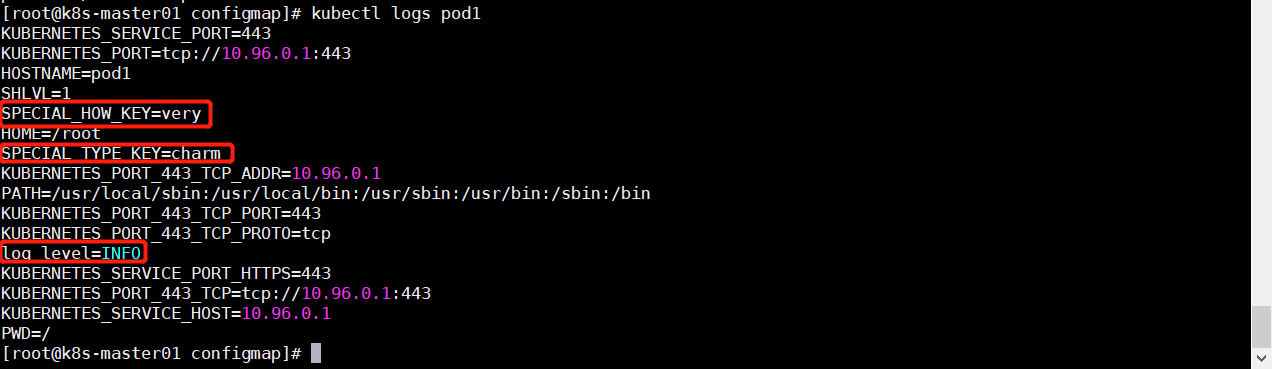
生成 Pod 后查看日志,可以看到注入成功
使用 ConfigMap 设置命令行参数
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vim pod2.yaml apiVersion: v1 kind: Pod metadata: name: pod2 spec: containers: - name: pod2-container image: busybox imagePullPolicy: IfNotPresent command: ["sh" , "-c" , "echo $(SPECIAL_HOW_KEY) $(SPECIAL_TYPE_KEY)" ] env: - name: SPECIAL_HOW_KEY valueFrom: configMapKeyRef: name: special-cm key: special.how - name: SPECIAL_TYPE_KEY valueFrom: configMapKeyRef: name: special-cm key: special.type envFrom: - configMapRef: name: env-cm restartPolicy: Never
将 ConfigMap 数据添加到一个卷中
创建 Pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vim pod3.yaml apiVersion: v1 kind: Pod metadata: name: pod3 spec: containers: - name: pod3-container image: busybox imagePullPolicy: IfNotPresent command: [ "/bin/sh" , "-c" , "sleep 1200" ] volumeMounts: - name: config-volume mountPath: /etc/config volumes: - name: config-volume configMap: name: special-cm restartPolicy: Never
进入 Pod,在挂载目录下查看是否写入到 config 文件里
6.1.1.2 ConfigMap热更新 本例子通过 ConfigMap 来实现热更新,可以实现热更新 nginx.conf,但需进入容器内部重载配置文件,所以通过热更新一个 html 来展示效果。
编写 yaml 文件,并创建
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 vim hotupdate.yaml apiVersion: v1 kind: ConfigMap metadata: name: nginx-hotupdate-cm namespace: default data: test.html: 'this is the fist test' --- apiVersion: apps/v1 kind: Deployment metadata: name: nginx-deployment namespace: default spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nginx-pod image: daocloud.io/library/nginx:latest ports: - containerPort: 80 volumeMounts: - name: test-html-volume mountPath: /usr/share/nginx/html volumes: - name: test-html-volume configMap: name: nginx-hotupdate-cm
1 kubectl apply -f hotupdate.yaml
测试是否能够访问到
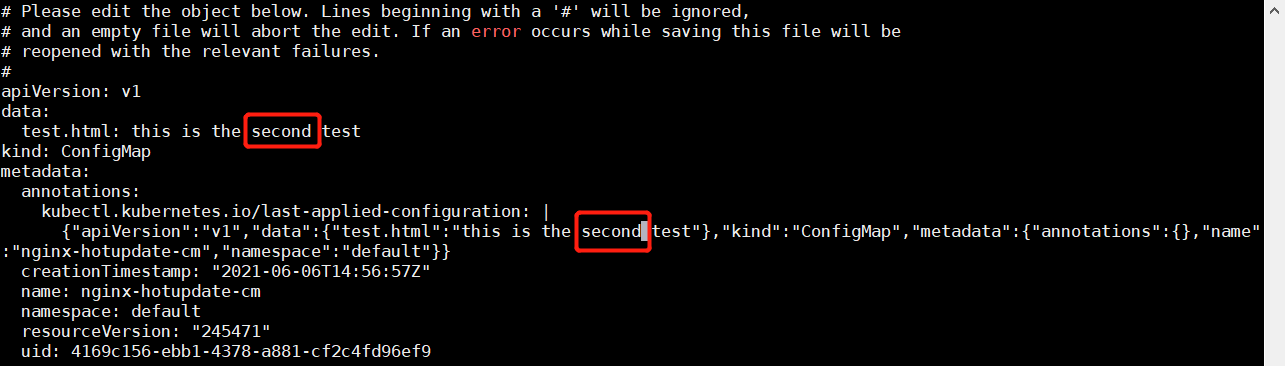
修改 ConfigMap,并再次访问
1 kubectl edit cm nginx-hotupdate-cm
6.1.2 Secret Secret 对象类型用来保存敏感信息,例如密码、OAuth 令牌和 SSH 密钥。 将这些信息放在 secret 中比放在 Pod 的定义或者 容器镜像 中来说更加安全和灵活。
Secret 的类型
内置类型
用法
Opaque用户定义的任意数据
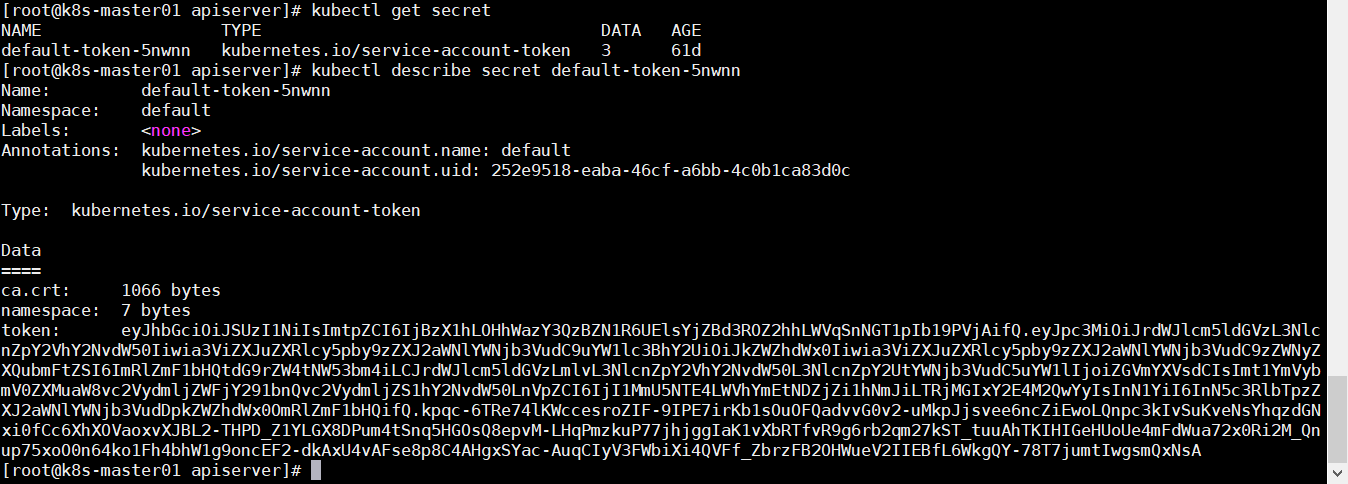
kubernetes.io/service-account-token服务账号令牌
kubernetes.io/dockercfg~/.dockercfg 文件的序列化形式
kubernetes.io/dockerconfigjson~/.docker/config.json 文件的序列化形式
kubernetes.io/basic-auth用于基本身份认证的凭据
kubernetes.io/ssh-auth用于 SSH 身份认证的凭据
kubernetes.io/tls用于 TLS 客户端或者服务器端的数据
bootstrap.kubernetes.io/token启动引导令牌数据
6.1.2.1 Opaque Opaque 使用base64编码存储信息,可以通过 base64 --decode 解码获得原始数据,因此安全性弱。
使用示例
生成 base64 编码
1 2 3 4 echo 'admin' | base64 YWRtaW4K echo '12345' | base64 MTIzNDUK
编写 yaml 文件
1 2 3 4 5 6 7 8 9 vim opaque.yaml apiVersion: v1 kind: Secret metadata: name: secret-opaque type: Opaque data: username: YWRtaW4K password: MTIzNDUK
1 kubectl apply -f opaque.yaml
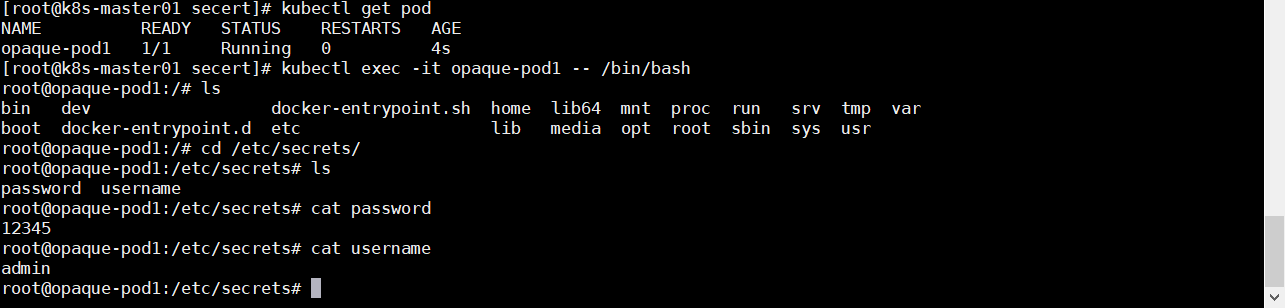
挂载到 volume 中使用,查看测试可以看到挂载后的信息被解码了
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vim opaque-pod1.yaml apiVersion: v1 kind: Pod metadata: name: opaque-pod1 spec: containers: - name: opaque-pod1-nginx image: daocloud.io/library/nginx:latest volumeMounts: - name: volume-opaque mountPath: /etc/secrets readOnly: yes volumes: - name: volume-opaque secret: secretName: secret-opaque
导入到环境变量中并测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 vim opaque-pod2.yaml apiVersion: apps/v1 kind: Deployment metadata: name: opaque-deployment spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: name: opaque-pod2 labels: app: nginx spec: containers: - name: opaque-pod2-nginx image: daocloud.io/library/nginx:latest ports: - containerPort: 80 env: - name: USER valueFrom: secretKeyRef: name: secret-opaque key: username - name: PASSWORD valueFrom: secretKeyRef: name: secret-opaque key: password
6.1.2.2 ImagePullSecret 可以使用下面两种 type 值之一来创建 Secret,用以存放访问 Docker 仓库来下载镜像的凭据。
kubernetes.io/dockercfgkubernetes.io/dockerconfigjson
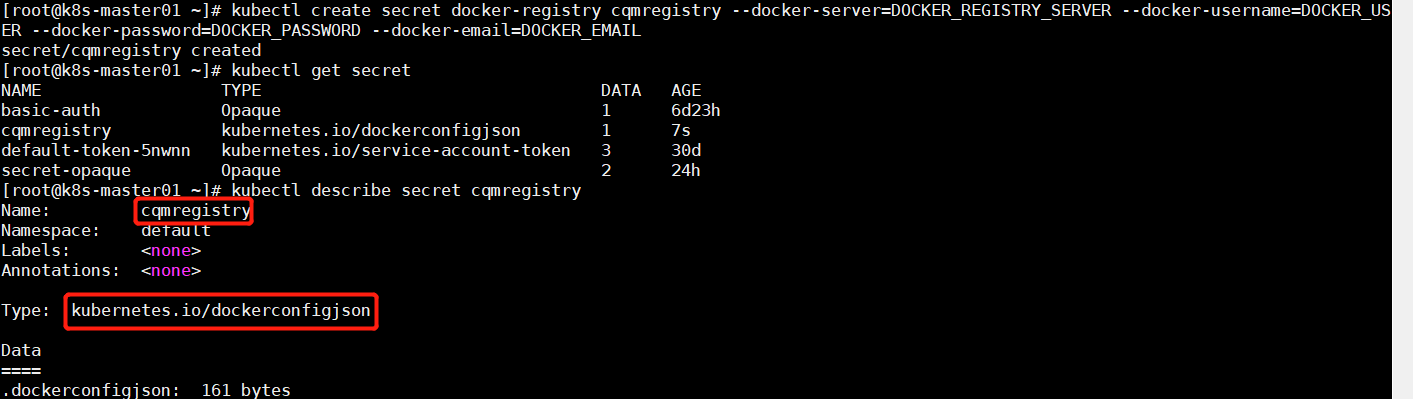
kubernetes.io/dockerconfigjson 创建 Secret 示例
创建 Secret
1 kubectl create secret docker-registry cqmregistry --docker-server=DOCKER_REGISTRY_SERVER --docker-username=DOCKER_USER --docker-password=DOCKER_PASSWORD --docker-email=DOCKER_EMAIL
在 Pod 中运用
1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: Pod metadata: name: nginx spec: containers: - name: nginx-pod image: daocloud.io/library/nginx:latest imagePullSecrets: - name: cqmregistry
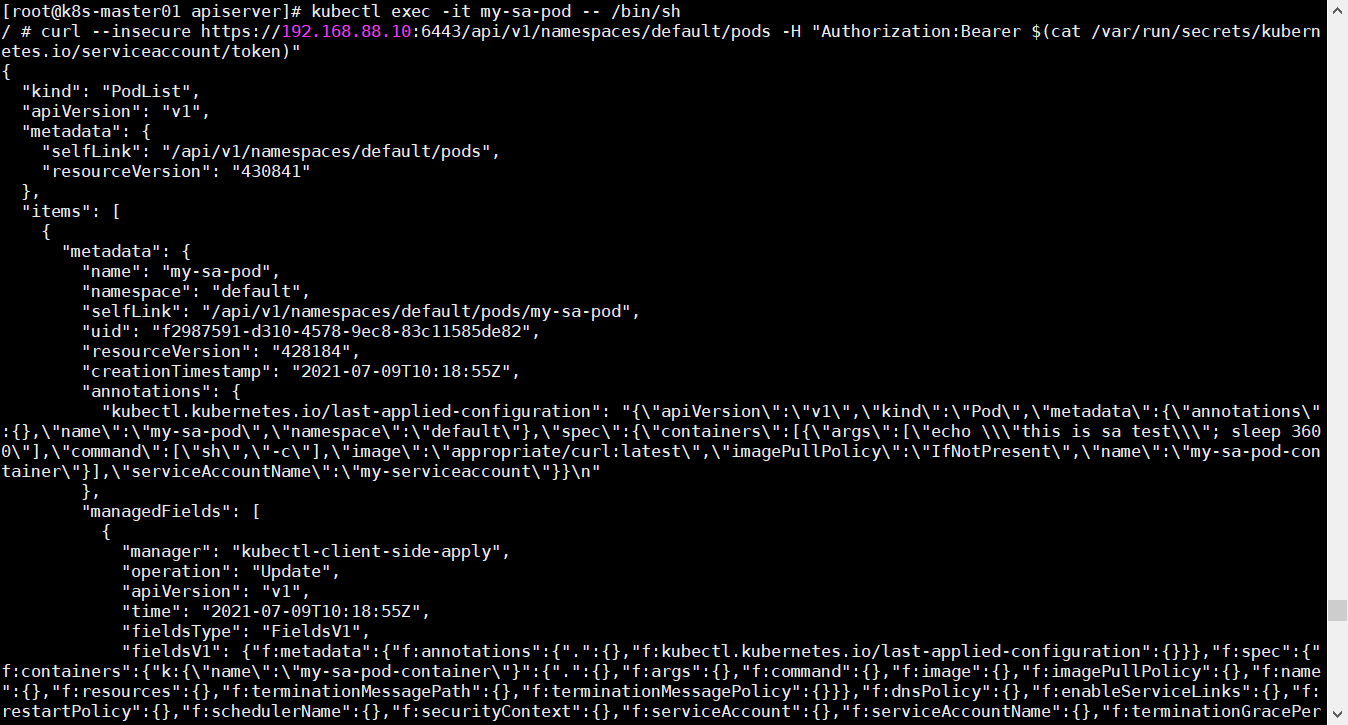
6.1.2.3 Downward API 有时候 Pod 需要获取自身的信息,这时候 Downward API 就派上用场了。
Downward API 是通过 fieldRef 参数获取信息的。
示例一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 apiVersion: v1 kind: Pod metadata: name: test-pod1 spec: containers: - name: test-pod1-container image: busybox imagePullPolicy: IfNotPresent command: [ 'sh' , '-c' ] args: [ 'echo "EnvPodName:${EnvPodName} EnvNodeName:${EnvNodeName}", sleep 3600' ] env: - name: EnvPodName valueFrom: fieldRef: fieldPath: metadata.name - name: EnvNodeName valueFrom: fieldRef: fieldPath: spec.nodeName
示例二
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 apiVersion: v1 kind: Pod metadata: name: test-pod2 spec: containers: - name: test-pod2-container image: busybox imagePullPolicy: IfNotPresent command: [ 'sh' , '-c' ] args: [ 'echo "EnvPodName:${EnvPodName} EnvNodeName:${EnvNodeName}", sleep 3600' ] volumeMounts: - name: test-volume mountPath: /test volumes: - name: test-volume downwardAPI: items: - path: 'PodName' fieldRef: fieldPath: metadata.name - path: 'NodeName' fieldRef: fieldPath: spec.nodeName
6.2 本地存储卷 Container 中的文件在磁盘上是临时存放的,这给 Container 中运行的较重要的应用程序带来一些问题。问题之一是当容器崩溃时文件丢失。kubelet 会重新启动容器, 但容器会以干净的状态重启。 第二个问题会在同一 Pod 中运行多个容器并共享文件时出现。 Kubernetes Volume 这一抽象概念能够解决这两个问题。
Kubernetes 支持很多类型的卷。 Pod 可以同时使用任意数目的卷类型。 临时卷类型的生命周期与 Pod 相同,但持久卷可以比 Pod 的存活期长。 当 Pod 不再存在时,Kubernetes 也会销毁临时卷;不过 Kubernetes 不会销毁持久卷。对于给定 Pod 中任何类型的卷,在容器重启期间数据都不会丢失。
卷的类型分为很多种,可通过官方文档查看:https://kubernetes.io/zh/docs/concepts/storage/volumes/
6.2.1 emptyDir 当 Pod 分派到某个 Node 上时,emptyDir 卷会被创建,并且在 Pod 在该节点上运行期间,卷一直存在。 就像其名称表示的那样,卷最初是空的。 尽管 Pod 中的容器挂载 emptyDir 卷的路径可能相同也可能不同,这些容器都可以读写 emptyDir 卷中相同的文件。 当 Pod 因为某些原因被从节点上删除时,emptyDir 卷中的数据也会被永久删除。
需要注意的是,容器崩溃并不会导致 Pod 被从节点上移除,因此容器崩溃期间 emptyDir 卷中的数据是安全的。
emptyDir 的一些用途:
缓存空间,例如基于磁盘的归并排序。
为耗时较长的计算任务提供检查点,以便任务能方便地从崩溃前状态恢复执行。
在 Web 服务器容器服务数据时,保存内容管理器容器获取的文件。
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 apiVersion: v1 kind: Pod metadata: name: emptydir-pod spec: containers: - name: emptydir-container1 image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent volumeMounts: - mountPath: /empty1 name: emptydir-volume - name: emptydir-container2 image: busybox imagePullPolicy: IfNotPresent command: ['/bin/sh' ,'-c' ,'sleep 6000' ] volumeMounts: - mountPath: /empty2 name: emptydir-volume volumes: - name: emptydir-volume emptyDir: {}
进入 Pod 中的不同容器查看是否共享同一个 volume,
6.2.2 hostPath hostPath 卷能将主机节点文件系统上的文件或目录挂载到你的 Pod 中,类似 docker 中的 volume 挂载。
hostPath 的一些用法有:
运行一个需要访问 Docker 内部机制的容器;可使用 hostPath 挂载 /var/lib/docker 路径。
在容器中运行 cAdvisor(容器监控工具) 时,以 hostPath 方式挂载 /sys。
允许 Pod 指定给定的 hostPath 在运行 Pod 之前是否应该存在,是否应该创建以及应该以什么方式存在。
除了必需的 path 属性之外,用户可以选择性地为 hostPath 卷指定 type。
支持的 type 值如下:
取值
行为
空字符串(默认)用于向后兼容,这意味着在安装 hostPath 卷之前不会执行任何检查。
DirectoryOrCreate如果在给定路径上什么都不存在,那么将根据需要创建空目录,权限设置为 0755,具有与 kubelet 相同的组和属主信息。
Directory在给定路径上必须存在的目录。
FileOrCreate如果在给定路径上什么都不存在,那么将在那里根据需要创建空文件,权限设置为 0644,具有与 kubelet 相同的组和所有权。
File在给定路径上必须存在的文件。
Socket在给定路径上必须存在的 UNIX 套接字。
CharDevice在给定路径上必须存在的字符设备。
BlockDevice在给定路径上必须存在的块设备。
注意:具有相同配置(例如基于同一 PodTemplate 创建)的多个 Pod 会由于节点上文件的不同而在不同节点上有不同的行为,即假如同一个 template 创建出来的 Pod 分配在了不同的 Node 上时,会因为节点的不同而产生不同的行为。
编写 yaml 文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: v1 kind: Pod metadata: name: hostpath-pod spec: containers: - name: hostpath-pod-container image: daocloud.io/library/nginx:latest volumeMounts: - mountPath: /test name: hostpath-volume volumes: - name: hostpath-volume hostPath: path: /data type: DirectoryOrCreate
查看是否挂载成功
需要注意的是,在FileOrCreate下,如果被挂载的目录不存在,那么不会自动创建该目录, 为了确保这种模式能够工作,可以尝试把文件和它对应的目录分开挂载。
hostPath FileOrCreate 配置示例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 apiVersion: v1 kind: Pod metadata: name: hostpath-fileorcreate-pod spec: containers: - name: hostpath-fileorcreate-pod-container image: daocloud.io/library/nginx:latest volumeMounts: - mountPath: /test name: mydir - mountPath: /test/test.txt name: myfile volumes: - name: mydir hostPath: path: /data type: DirectoryOrCreate - name: myfile hostPath: path: /data/test.txt type: FileOrCreate
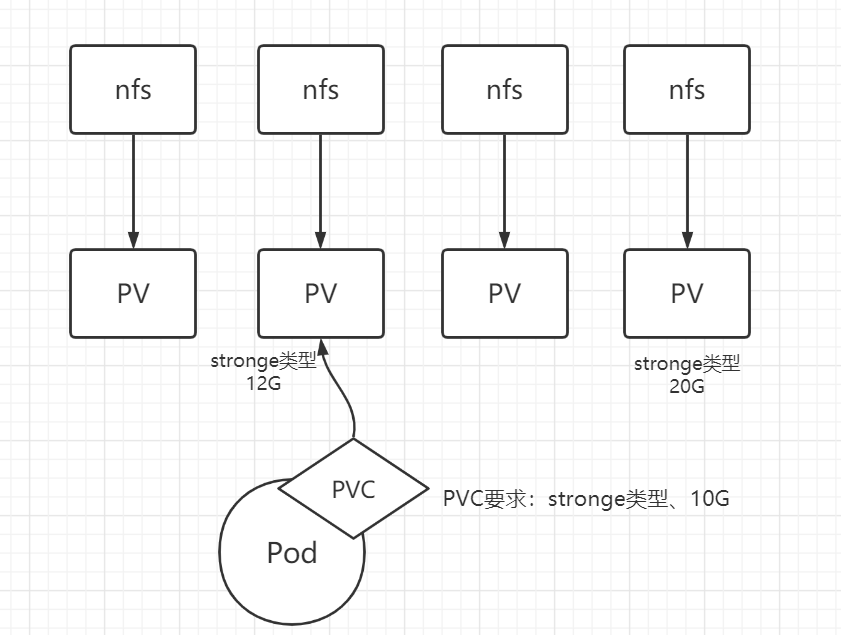
6.3 持久存储卷 6.3.1 PV和PVC PV 和 PVC 是 k8s 提供的两个 api 资源。
PV
持久卷(PersistentVolume,PV)是集群中的一块存储,可以由管理员事先供应,或者使用存储类 来动态供应,PV 是集群资源,和普通的 Volume 一样,也是使用卷插件来实现的,只是它们拥有独立于任何使用 PV 的 Pod 的生命周期。
PVC
持久卷申领(PersistentVolumeClaim,PVC)表达的是用户对存储的请求。概念上与 Pod 类似。Pod 会耗用 Node 资源,而 PVC 申领会耗用 PV 资源。Pod 可以请求特定数量的资源(CPU 和内存),同样 PVC 申领也可以请求特定的大小和访问模式。
PV 的供应方式有两种:
静态供应
集群管理员创建若干 PV 卷。这些卷对象带有真实存储的细节信息,并且对集群用户可用(可见)。PV 卷对象存在于 Kubernetes API 中,可供用户消费(使用)。
动态供应
如果管理员所创建的所有静态 PV 卷都无法与用户的 PersistentVolumeClaim 匹配, 集群可以尝试为该 PVC 申领动态供应一个存储卷。 这一供应操作是基于 StorageClass 来实现的:PVC 申领必须请求某个 存储类 ,同时集群管理员必须 已经创建并配置了该类,这样动态供应卷的动作才会发生。 如果 PVC 申领指定存储类为 "",则相当于为自身禁止使用动态供应的卷。
为了基于存储类完成动态的存储供应,集群管理员需要在 API 服务器上启用 DefaultStorageClass 准入控制器 。 举例而言,可以通过保证 DefaultStorageClass 出现在 API 服务器组件的 --enable-admission-plugins 标志值中实现这点;该标志的值可以是逗号 分隔的有序列表。关于 API 服务器标志的更多信息,可以参考 kube-apiserver 文档。
绑定
通俗理解就是一旦 PV 与 PVC 进行了绑定,那么该 PV 就无法与其它 PVC 进行绑定了。
保护
当一个 PV 与 PVC 绑定之后,假设 Pod 被删除,那么该 PV 与 PVC 依旧会是一个绑定的关系。
持久卷的类型
PV 持久卷是用插件的形式来实现的。Kubernetes 目前支持以下插件:
访问模式
PV 卷可以用资源提供者所支持的任何方式挂载到宿主系统上。 如下表所示,提供者(驱动)的能力不同,每个 PV 卷的访问模式都会设置为 对应卷所支持的模式值。 例如,NFS 可以支持多个读写客户,但是某个特定的 NFS PV 卷可能在服务器 上以只读的方式导出。每个 PV 卷都会获得自身的访问模式集合,描述的是 特定 PV 卷的能力。
访问模式有:
ReadWriteOnce:卷可以被一个节点以读写方式挂载;
ReadOnlyMany:卷可以被多个节点以只读方式挂载;
ReadWriteMany:卷可以被多个节点以读写方式挂载。
对于不同类型的存储卷访问模式也有不同,如下表
卷插件
ReadWriteOnce
ReadOnlyMany
ReadWriteMany
AWSElasticBlockStore
✓
-
-
AzureFile
✓
✓
✓
AzureDisk
✓
-
-
CephFS
✓
✓
✓
Cinder
✓
-
-
CSI
取决于驱动
取决于驱动
取决于驱动
FC
✓
✓
-
FlexVolume
✓
✓
取决于驱动
Flocker
✓
-
-
GCEPersistentDisk
✓
✓
-
Glusterfs
✓
✓
✓
HostPath
✓
-
-
iSCSI
✓
✓
-
Quobyte
✓
✓
✓
NFS
✓
✓
✓
RBD
✓
✓
-
VsphereVolume
✓
-
- (Pod 运行于同一节点上时可行)
PortworxVolume
✓
-
✓
ScaleIO
✓
✓
-
StorageOS
✓
-
-
类
每个 PV 可以属于某个类(Class),通过将其 storageClassName 属性设置为某个 StorageClass 的名称来指定。 特定类的 PV 卷只能绑定到请求该类存储卷的 PVC 申领。 未设置 storageClassName 的 PV 卷没有类设定,只能绑定到那些没有指定特定存储类的 PVC 申领。
回收策略
目前的回收策略有:
Retain(保留) – 手动回收
Recycle(回收)– 基本擦除 (rm -rf /thevolume/*)
Delete(删除)– 诸如 AWS EBS、GCE PD、Azure Disk 或 OpenStack Cinder 卷这类关联存储资产也被删除
目前,仅 NFS 和 HostPath 支持回收(Recycle)。 AWS EBS、GCE PD、Azure Disk 和 Cinder 卷都支持删除(Delete)。
阶段(状态)
每个卷会处于以下阶段(Phase)之一:
Available(可用)– 卷是一个空闲资源,尚未绑定到任何申领;
Bound(已绑定)– 该卷已经绑定到某申领;
Released(已释放)– 所绑定的申领已被删除,但是资源尚未被集群回收;
Failed(失败)– 卷的自动回收操作失败。
示例一
这个实例是先后创建 PV、PVC、Deployment
创建 PV
1 2 3 4 5 6 7 8 9 10 11 12 13 14 apiVersion: v1 kind: PersistentVolume metadata: name: test-pv spec: capacity: storage: 1Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Recycle storageClassName: nfs nfs: path: /nfs server: 192.168 .88 .100
创建 PVC
1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: PersistentVolumeClaim metadata: name: test-pvc spec: accessModes: - ReadWriteMany storageClassName: nfs resources: requests: storage: 1Gi
创建 Deployment
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 apiVersion: apps/v1 kind: Deployment metadata: name: test-deployment spec: replicas: 2 selector: matchLabels: app: nginx template: metadata: name: test-deployment-pod labels: app: nginx spec: containers: - name: test-deployment-pod-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent volumeMounts: - name: test-volume mountPath: /usr/share/nginx/html volumes: - name: test-volume persistentVolumeClaim: claimName: test-pvc
示例二
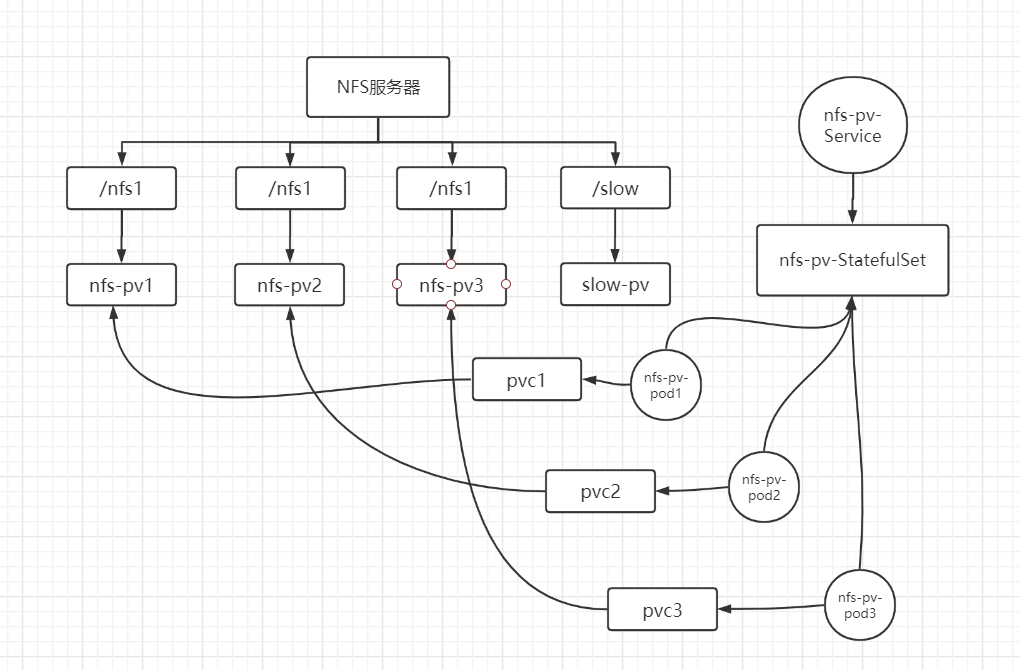
这个实例会由 StatefulSet 自动创建 PVC
部署 NFS 服务器,并在每个节点安装nfs-utils
部署 PV,这里创建了四个 PV
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv1 spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: nfs nfs: path: /nfs1 server: 192.168 .88 .100 --- apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv2 spec: capacity: storage: 2Gi accessModes: - ReadOnlyMany persistentVolumeReclaimPolicy: Retain storageClassName: nfs nfs: path: /nfs2 server: 192.168 .88 .100 --- apiVersion: v1 kind: PersistentVolume metadata: name: nfs-pv3 spec: capacity: storage: 3Gi accessModes: - ReadWriteMany persistentVolumeReclaimPolicy: Retain storageClassName: nfs nfs: path: /nfs3 server: 192.168 .88 .100 --- apiVersion: v1 kind: PersistentVolume metadata: name: slow-pv spec: capacity: storage: 1Gi accessModes: - ReadWriteOnce persistentVolumeReclaimPolicy: Retain storageClassName: slow nfs: path: /slow server: 192.168 .88 .100
创建无头 SVC、StatefulSet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 apiVersion: v1 kind: Service metadata: name: nfs-pv-svc labels: app: nginx spec: ports: - port: 80 targetPort: 80 clusterIP: None selector: app: nginx --- apiVersion: apps/v1 kind: StatefulSet metadata: name: nfs-pv-statefulset spec: selector: matchLabels: app: nginx serviceName: nfs-pv-svc replicas: 3 template: metadata: name: nfs-pv-pod labels: app: nginx spec: containers: - name: nfs-pv-pod-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent ports: - containerPort: 80 volumeMounts: - name: nfs-pv-volume mountPath: /usr/share/nginx/html volumeClaimTemplates: - metadata: name: nfs-pv-volume spec: accessModes: [ 'ReadWriteOnce' ] storageClassName: 'nfs' resources: requests: storage: 1Gi
先后创建后查看 Pod 创建情况,可以看到只创建了一个 Pod,因为现有的 PV 只有一个符合匹配条件,而 StatefulSet 是前一个 Pod 创建成功才会创建下一个,因为第二个 Pod 创建不成功,所以第三个 Pod 不会被创建
进入容器内部可以看到挂载成功,去到 NFS 服务器的/nfs1目录下创建test.html文件测试成功
删除创建失败的 Pod 以及对应的 PVC,创建新的两个 PV,以满足 StatefulSet 的挂载要求,剩下的 Pod 就会逐一创建成功
删除上面测试的 Pod,StatefulSet 会重新创建一个 Pod,且数据不会丢失
这里会有个问题,如果删除了 StatefulSet,那么对应的 Pod 也会被删除,可是已经绑定的 PV 并不会删除,这里就需要手动回收了。
手动回收
删除 StatefulSet
删除 PVC
修改 PV
1 2 3 4 kubectl edit pv pv名称 # 删除ClaimRef的信息 ClainRef: ...
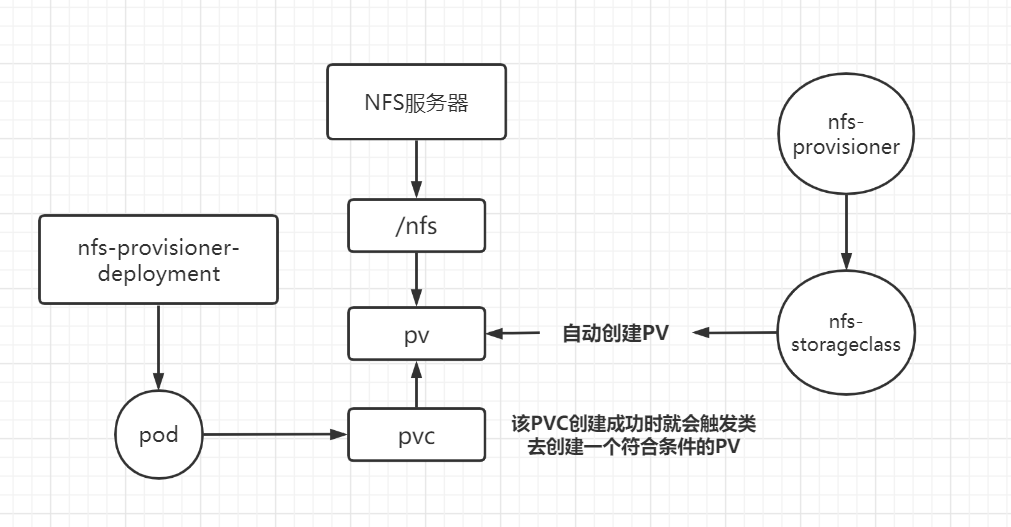
6.3.2 StorageClass 以上的方法都是静态创建的 PV,会出现 PVC 找不到条件符合的 PV 进行绑定。
而 StorageClass 的作用是根据 PVC 的需求动态创建 PV。
示例一
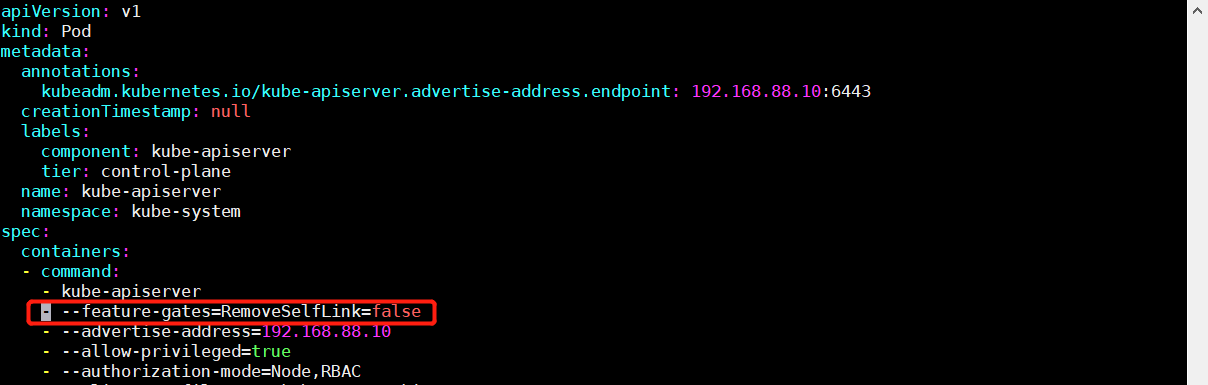
k8s 在 1.20 版本开始就禁用了 selfLink,所以需在配置文件添加以下内容
StorageClass 是通过存储分配器来动态创建 PV 的,但 k8s 内部的存储分配器不支持 NFS,所以首先要安装 NFS 存储分配器
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 vim nfs_provisioner.yaml kind: Deployment apiVersion: apps/v1 metadata: name: nfs-client-provisioner spec: replicas: 1 selector: matchLabels: app: nfs-client-provisioner strategy: type: Recreate template: metadata: labels: app: nfs-client-provisioner spec: serviceAccountName: nfs-client-provisioner containers: - name: nfs-client-provisioner image: registry.cn-hangzhou.aliyuncs.com/open-ali/nfs-client-provisioner:latest volumeMounts: - name: nfs-client-root mountPath: /nfs-provision env: - name: PROVISIONER_NAME value: nfs-client - name: NFS_SERVER value: 192.168 .88 .100 - name: NFS_PATH value: /nfs volumes: - name: nfs-client-root nfs: server: 192.168 .88 .100 path: /nfs
给 NFS 存储分配器授权
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 vim nfs_provisioner_rbac.yaml apiVersion: v1 kind: ServiceAccount metadata: name: nfs-client-provisioner namespace: default --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: name: nfs-client-provisioner-runner rules: - apiGroups: ["" ] resources: ["persistentvolumes" ] verbs: ["get" , "list" , "watch" , "create" , "delete" ] - apiGroups: ["" ] resources: ["persistentvolumeclaims" ] verbs: ["get" , "list" , "watch" , "update" ] - apiGroups: ["storage.k8s.io" ] resources: ["storageclasses" ] verbs: ["get" , "list" , "watch" ] - apiGroups: ["" ] resources: ["events" ] verbs: ["create" , "update" , "patch" ] --- kind: ClusterRoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: run-nfs-client-provisioner subjects: - kind: ServiceAccount name: nfs-client-provisioner namespace: default roleRef: kind: ClusterRole name: nfs-client-provisioner-runner apiGroup: rbac.authorization.k8s.io --- kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner namespace: default rules: - apiGroups: ["" ] resources: ["endpoints" ] verbs: ["get" , "list" , "watch" , "create" , "update" , "patch" ] --- kind: RoleBinding apiVersion: rbac.authorization.k8s.io/v1 metadata: name: leader-locking-nfs-client-provisioner namespace: default subjects: - kind: ServiceAccount name: nfs-client-provisioner namespace: default roleRef: kind: Role name: leader-locking-nfs-client-provisioner apiGroup: rbac.authorization.k8s.io
创建 StorageClass
1 2 3 4 5 6 7 8 9 10 11 vim nfs_storageclass.yaml apiVersion: storage.k8s.io/v1 kind: StorageClass metadata: name: nfs-storageclass provisioner: nfs-client parameters: archieveOnDelete: 'false'
创建 PVC,可以看到 NFS 存储分配器已经自动创建了 PV 与之绑定
1 2 3 4 5 6 7 8 9 10 11 12 13 vim nfs_storageclass_pvc.yaml apiVersion: v1 kind: PersistentVolumeClaim metadata: name: nfs-storageclass-pvc spec: accessModes: - ReadWriteMany storageClassName: 'nfs-client' resources: requests: storage: 500Mi
创建一个 Deployment 测试是否能用这个 PVC
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 vim nfs_provisioner_deployment.yaml apiVersion: apps/v1 kind: Deployment metadata: name: nfs-provisioner-deployment spec: replicas: 1 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: nfs-provisioner-deployment-nginx image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent volumeMounts: - name: nfs-storageclass-pvc mountPath: /usr/share/nginx/html/test volumes: - name: nfs-storageclass-pvc persistentVolumeClaim: claimName: nfs-storageclass-pvc
在 NFS 服务器的共享目录下创建一个 test.html
访问 Deployment 创建出来的 Pod,可以看到是可以访问的
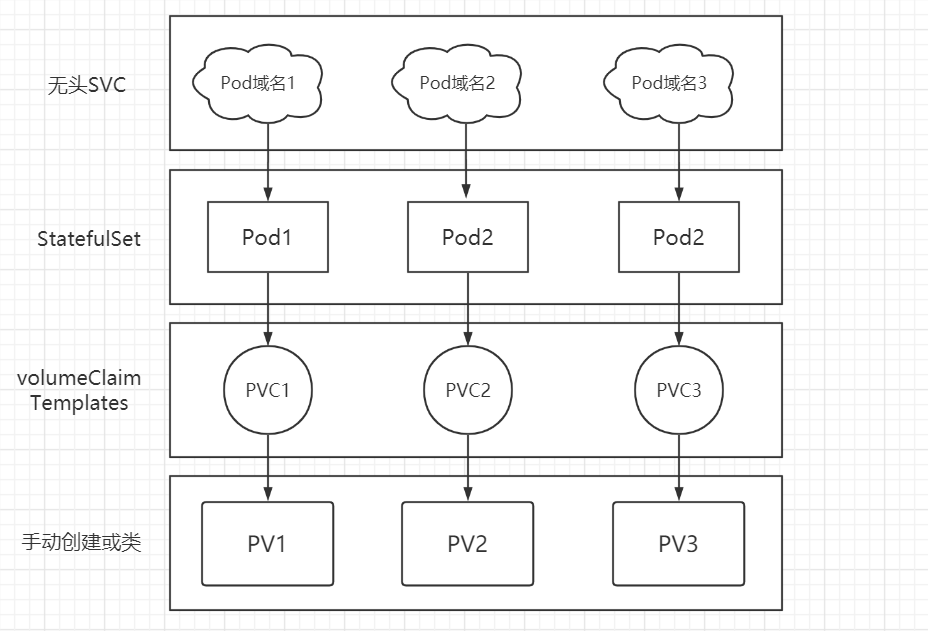
6.4 StatefulSet StatefulSet 是一种提供排序和唯一性保证的特殊 Pod 控制器,当有部署顺序、持久数据或固定网络等相关的特殊需求时,可以用 StatefulSet 控制器来进行控制。
StatefulSet 提供有状态服务,主要功能如下:
实现稳定的持久化存储:通过 PVC 来实现,Pod 之间不能共用一个存储卷,每个 Pod 都要有一个自己专用的存储卷。
实现稳定的网络标识:Pod 重新调度后其 PodName 和 HostName 不变,通过无头 SVC 来实现。
实现有序部署、有序伸缩:Pod 是有顺序的,只有前一个 Pod 创建成功才会创建下一个,直到最后。
实现有序收缩、有序删除:从最后一个开始,依次删除到第一个。
无头 SVC :为 Pod 生成可以解析的 DNS 记录。
示例一
创建无头 SVC
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vim statefulset_nginx_svc.yaml apiVersion: v1 kind: Service metadata: name: statefulset-nginx-svc spec: selector: app: nginx clusterIP: None ports: - protocol: TCP port: 8080 targetPort: 80 type: ClusterIP
创建 StatefulSet
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 vim statefulset_nginx.yaml apiVersion: apps/v1 kind: StatefulSet metadata: name: statefulset-nginx spec: serviceName: statefulset-nginx-svc replicas: 4 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: statefulset-nginx-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent ports: - name: http containerPort: 80 volumeClaimTemplates: - metadata: name: statefulset-nginx-pvc spec: accessModes: [ 'ReadWriteOnce' ] storageClassName: 'nfs-storageclass' resources: requests: storage: 50Mi
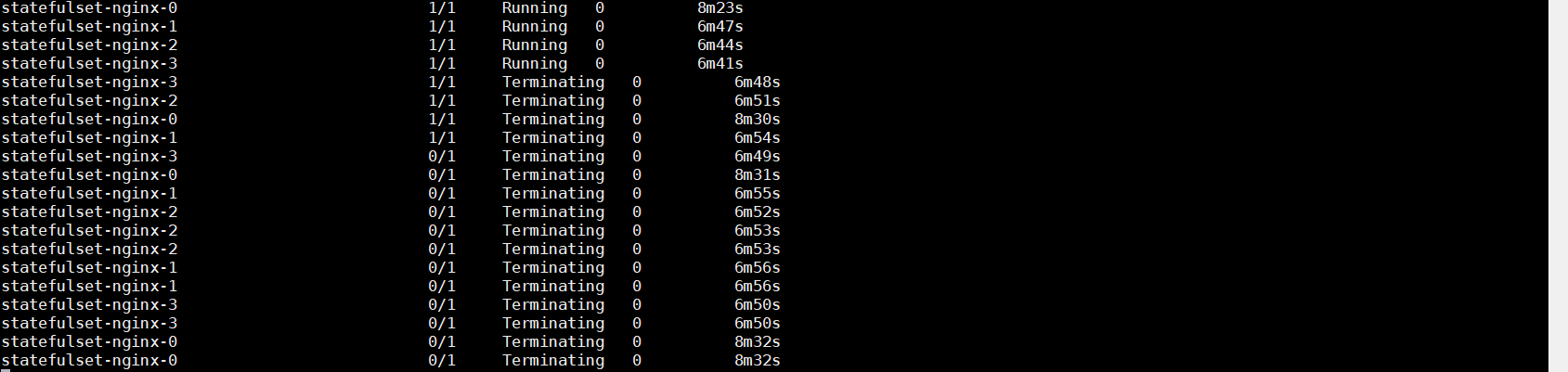
可以看到 Pod 是有序创建的,且每个 Pod 都是单独使用一个 PVC 和 PV,删除 StatefulSet 也可以看到 Pod 是有序删除的,且删除后 PVC 与 PV 依旧存在,重新生成 StatefulSet 可以继续使用这些 PVC 和 PV
有序创建
PVC 与 PV
有序删除
创建一个 Pod 用来测试无头 SVC 提供的 DNS 服务
1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: Pod metadata: name: test-pod spec: containers: - name: test-pod-container image: appropriate/curl:latest imagePullPolicy: IfNotPresent command: [ 'sh' , '-c' ] args: [ 'echo "this is test"; sleep 36000' ]
进入 Pod 后可以通过nslookup测试,形式为{ServiceName}.{NameSpace}.svc.{ClusterDomain}
通过域名也可以访问各个 Pod,形式为{PodName}{ServiceName}.{NameSpace}.svc.{ClusterDomain}
七、k8s调度器 scheduler 是 k8s 集群的调度器,对每一个新创建的 Pod 或者是未被调度的 Pod,scheduler 会选择一个最优的 Node 去运行这个 Pod。然而,Pod 内的每一个容器对资源都有不同的需求,而且 Pod 本身也有不同的资源需求。因此,Pod 在被调度到 Node 上之前, 根据这些特定的资源调度需求,需要对集群中的 Node 进行一次过滤。
在做调度决定时需要考虑的因素包括:单独和整体的资源请求、硬件/软件/策略限制、 亲和以及反亲和要求、数据局域性、负载间的干扰等等。
调度流程:
过滤:调度器会将所有满足 Pod 调度需求的 Node 选出来。
打分:调度器会为 Pod 从所有可调度节点中选取一个最合适的 Node。
7.1 亲和性与反亲和性 7.1.1 Node亲和性 节点亲和性是通过pod.spec.nodeAffinity来实现的,包括以下两种:
preferredDuringSchedulingIgnoredDuringExecution:软策略
requiredDuringSchedulingIgnoredDuringExecution:硬策略
requiredDuringSchedulingIgnoredDuringExecution硬策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 apiVersion: v1 kind: Pod metadata: name: node-required-pod spec: containers: - name: node-required-pod-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: NotIn values: - k8s-node01
创建后可以看到 Pod 不会被创建在 k8s-node01 节点上
preferredDuringSchedulingIgnoredDuringExecution软策略
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 apiVersion: v1 kind: Pod metadata: name: node-preferred-pod spec: containers: - name: node-preferred-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent affinity: nodeAffinity: preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - key: kubernetes.io/hostname operator: In values: - k8s-node03
可以看到虽然要求部署到 k8s-node03 节点上,但由于本环境没有该节点,所以就被分配到其它的节点了
软硬合体版
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 apiVersion: v1 kind: Pod metadata: name: node-preandreq-pod spec: containers: - name: node-preandreq-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - { key: cpu , operator: In , values: [4core ] } preferredDuringSchedulingIgnoredDuringExecution: - weight: 1 preference: matchExpressions: - { key: disktype , operator: In , values: [ssd ] }
软策略和硬策略一起使用就会先满足硬策略再分析软策略,可以看到现有的节点没有可以满足以上条件的,所以 Pod 一直处于 Pending 状态
7.1.2 Pod亲和性 有时候需要将某些 Pod 与正在运行的已具有某些特质的 Pod 调度到一起,因此就需要 Pod 亲和性调度方式。
Pod 亲和性是通过spec.affinity.podAffinity/podAntiAffinity来实现的,前者为亲和性 ,后者为反亲和性 ,包括以下两种:
preferredDuringSchedulingIgnoredDuringExecution:软策略
requiredDuringSchedulingIgnoredDuringExecution:硬策略
requiredDuringSchedulingIgnoredDuringExecution硬策略
首先创建一个标签为app:nginx的 Pod
1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: Pod metadata: name: test-pod labels: app: nginx spec: containers: - name: test-pod-container-nginx image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent
创建硬策略亲和性 Pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 apiVersion: v1 kind: Pod metadata: name: pod-required spec: containers: - name: pod-required-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent affinity: podAffinity: requiredDuringSchedulingIgnoredDuringExecution: - labelSelector: matchExpressions: - key: app operator: In values: - nginx topologyKey: kubernetes.io/hostname
可以看到会分配在同一节点上
删除该 Pod,将podAffinity改为podAntiAffinity,将不会分配到一起
7.2 污点和容忍度 污点(taint)表示一个节点上存在不良状况,污点会影响 Pod 的调度,其定义方式如下
1 kubectl taint node {节点名称} {污点名称}={污点值}:{污点的影响}
污点的影响有三种:
NoExecute:不将 Pod 调度到具备该污点的节点上,如果 Pod 已经在该节点运行,则会被驱逐。
NoSchedule:不将 Pod 调度到具备该污点的节点上,如果 Pod 已经在该节点运行,不会被驱逐。
PreferNoSchedule:不推荐将 Pod 调度到具备该污点的节点上。
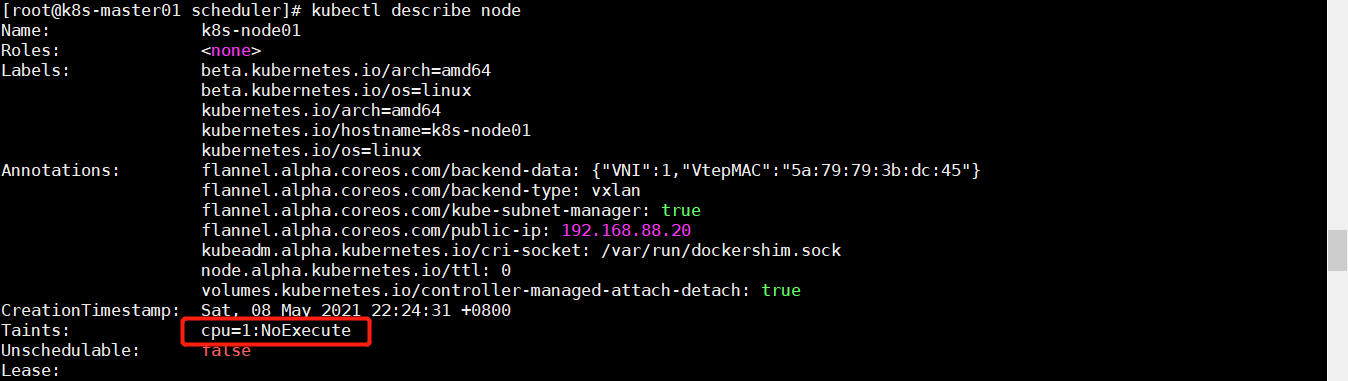
添加污点
1 kubectl taint node k8s-node01 cpu=1:NoExecute
删除污点
1 kubectl taint node k8s-node01 cpu=1:NoExecute-
示例一
给 k8s-node01 打上污点
1 kubectl taint node k8s-node01 cpu=1:NoExecute
创建 Pod
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 apiVersion: v1 kind: Pod metadata: name: toleration-pod spec: containers: - name: toleration-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent affinity: nodeAffinity: requiredDuringSchedulingIgnoredDuringExecution: nodeSelectorTerms: - matchExpressions: - key: kubernetes.io/hostname operator: In values: - k8s-node01 tolerations: - key: "cpu" operator: "Equal" value: "1" effect: "NoExecute" tolerationSeconds: 36
可以看到该 Pod 依旧可以调度到 k8s-node01 节点上,但超过 3600 秒后就被驱除了
容忍度设置一般用于 DaemonSet 控制器,因为 DaemonSet 控制器下的应用一般是为节点本身提供服务的。
7.3 优先级和抢占式调度 当集群的资源(CPU、内存、磁盘等)不足时,新 Pod 的创建会一直处于 Pending 的状态,默认情况下,除了系统外的 Pod,其它 Pod 的优先级都是相同的,如果调高了 Pod 的优先级,那么节点就会将低优先级的 Pod 驱逐,腾出空间给优先级高的 Pod,这就被称为抢占式调度 。
示例一
要调整优先级,需要先创建 PriorityClass
1 2 3 4 5 6 7 8 9 10 apiVersion: scheduling.k8s.io/v1 kind: PriorityClass metadata: name: test-priorityclass value: 1000000 globalDefault: false description: "this priorityclass is test"
在 Pod 中调用
1 2 3 4 5 6 7 8 9 10 apiVersion: v1 kind: Pod metadata: name: priorityclass-pod spec: containers: - name: priorityclass-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent priorityClassName: test-priorityclass
7.4 为Pod设置计算资源 容器运行时会提供一些机制来限制容器可以使用的计算资源(CPU、内存和磁盘等),Pod 模板中也提供了这个功能,主要如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 resources: limits: cpu: memory: requests: cpu: memory:
示例一
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 apiVersion: v1 kind: Pod metadata: name: resources-pod spec: containers: - name: resources-container image: vish/stress imagePullPolicy: IfNotPresent args: [ '-mem-total' ,'150Mi' ,'-mem-alloc-size' ,'5Mi' ,'-mem-alloc-sleep' ,'1s' ] resources: limits: cpu: '1' memory: '100Mi' requests: cpu: '200m' memory: '50Mi'
可以看到 Pod 最初可以运行,但20秒后就不行了
7.5 命名空间管理 命名空间的主要作用是对 k8s 集群的资源进行划分,这种划分是一种逻辑划分,用于实现多租户的资源隔离。
命名空间的创建
1 kubectl create namespace 命名空间名称
命名空间的资源配额
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 apiVersion: v1 kind: ResourceQuota metadata: name: namespace: spec: hard: limits.cpu: limits.memory: requests.cpu: requests.memory: requests.storage: persistentvolumeclaims: {storage-class-name }.storageclass.storage.k8s.io/requests.storage: configmaps: pods: replicationcontrollers: resourcequotas: services: services.loadbalancers: services.nodeports: secrets:
7.5.1 命名空间的资源配额 示例一
先创建一个命名空间
1 kubectl create namespace test-ns
创建资源配额
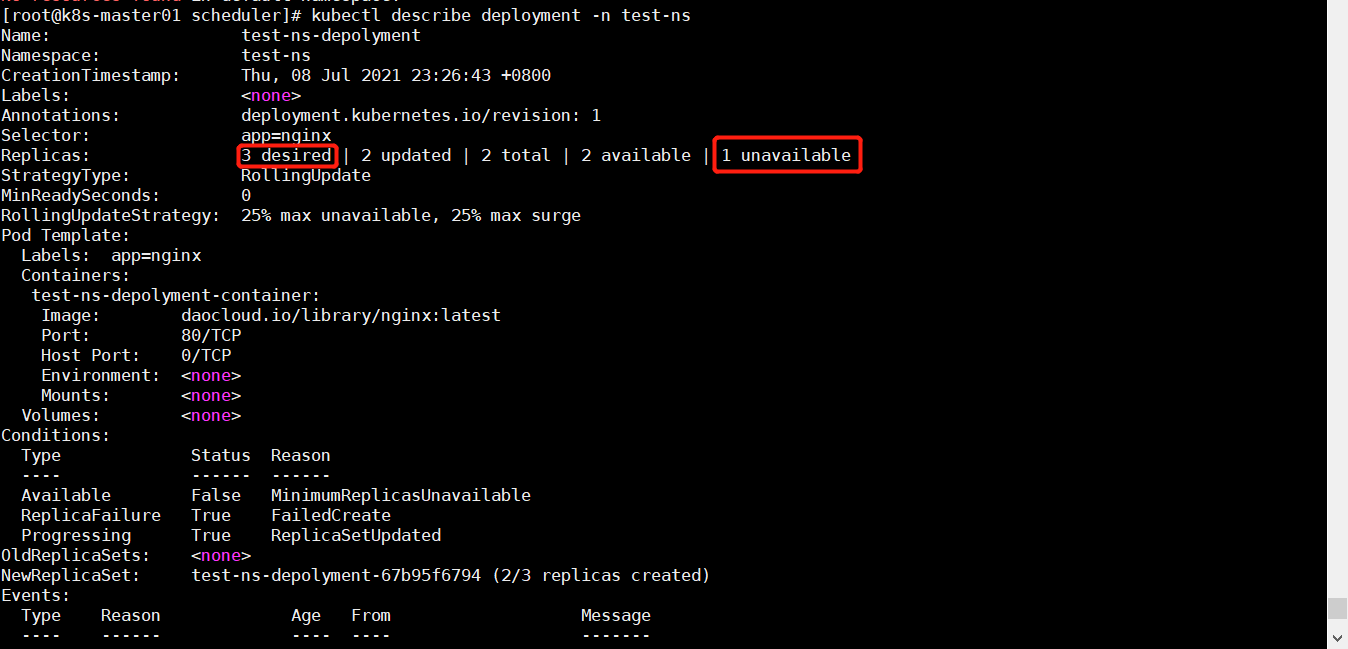
1 2 3 4 5 6 7 8 9 10 apiVersion: v1 kind: ResourceQuota metadata: name: test-rq namespace: test-ns spec: hard: pods: '2' services: '1' persistentvolumeclaims: '4'
创建一个 Deployment
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 apiVersion: apps/v1 kind: Deployment metadata: name: test-ns-depolyment namespace: test-ns spec: replicas: 3 selector: matchLabels: app: nginx template: metadata: labels: app: nginx spec: containers: - name: test-ns-depolyment-container image: daocloud.io/library/nginx:latest imagePullPolicy: IfNotPresent ports: - containerPort: 80
配额限制的 Pod 数量是2,但 Deployment 设置的副本数是3,可以看到是创建不了第三个 Pod 的
7.5.2 命名空间单个资源的资源配额 通过设置资源配额,可以限定一个命名空间下使用的资源总量,但这只是总量限制,对于单个资源没有限制,有时候一个 Pod 就可能用完整个命名空间所指定的资源,为了避免,可以通过LimitRange来对单个资源进行限定。
设置容器的限额范围
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 apiVersion: v1 kind: LimitRange metadata: name: limitrange-container namespace: test-ns spec: limits: - max: cpu: '200m' memory: '300Mi' min: cpu: '100m' memory: '150Mi' default: cpu: '180m' memory: '250Mi' defaultRequest: cpu: '110m' memory: '160Mi' type: Container
当 LimitRange 创建成功后,创建该命名空间下的 Pod 时,各个容器的resource.limits和resource.requests必须满足 Max 和 Min 之间的范围。
而default和defaultRequest是指,当创建 Pod 时没用设置限额,则根据此属性来设置限额。
设置 Pod 的限额范围
1 2 3 4 5 6 7 8 9 10 11 12 13 14 apiVersion: v1 kind: LimitRange metadata: name: limitrange-pod namespace: test-ns spec: limits: - max: cpu: '1' memory: '600Mi' min: cpu: '500m' memory: '300Mi' type: Pod
当 LimitRange 创建成功后,创建该命名空间下的 Pod 时,各个 Pod 的resource.limits和resource.requests必须满足 Max 和 Min 之间的范围。
设置 PVC 的限额范围
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: v1 kind: LimitRange metadata: name: limitrange-pvc namespace: test-ns spec: limits: - max: storage: 1Gi min: storage: 200Mi type: PersistentVolumeClaim
设置 Pod 或容器的比例限额范围
1 2 3 4 5 6 7 8 9 10 apiVersion: v1 kind: LimitRange metadata: name: limitrange-ratio namespace: test-ns spec: limits: - maxLimitRequestRatio: memory: 2 type: Pod
设置比例限额可以限制 Pod 或容器设置的请求资源和上限资源的比值,在该示例中,Pod 所有容器的resources.limits.memory的总和要 = Pod 所有容器的resources.requests.memory的总和的两倍,即上限必须是需求的两倍 ,Pod 才能够创建成功。
7.6 标签、选择器、注解 7.6.1 标签 k8s 的标签(label)是一种语义化标记标签,可以附加到 k8s 对象上,对它们进行标记和划分。
标签的形式是键值对,每个资源对象都可以拥有多个标签,但每个键都只能有一个值。
对于标签的设置,是通过metadata属性中实现的,如下
1 2 3 4 5 6 metadata: name: labels: key1: value1 key2: value2 ...
而对于已有的资源,可以通过以下命令添加或删除标签
1 2 kubectl label 资源类型 资源名称 标签名=标签值 kubectl label 资源类型 资源名称 标签名=标签值-
7.6.2 选择器 通过标签选择器(selector)就可以快速查找到指定标签的资源。
通过-l查找方式如下
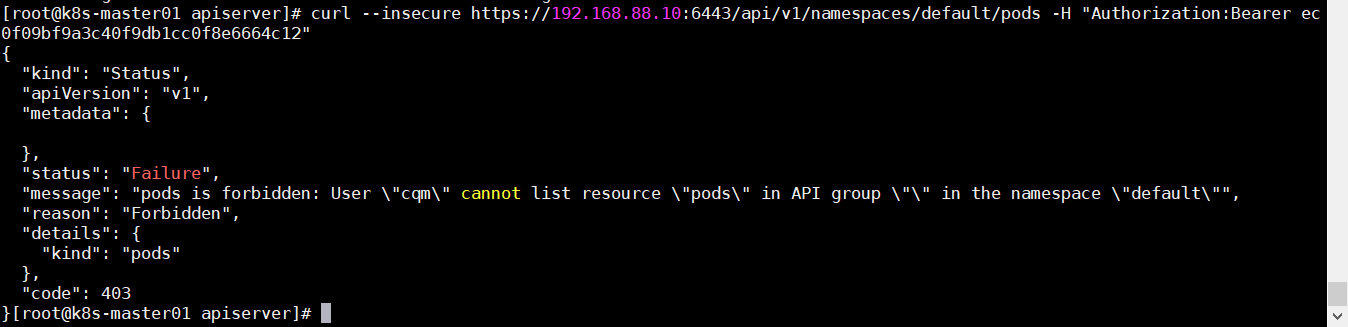
1 kubectl get pod -l 标签名=/!=标签值
通过in notin查找
1 kubectl get pod -l '标签名1 in/notin (标签值1,标签值2)'
每种基于控制器的对象也可以使用标签来选择需要操作的 Pod,如 Job、Deployment、DaemonSet 等都可以在spec中指定选择器,以查找到符合条件的 Pod,如下
1 2 3 4 5 6 7 8 spec: selector: matchLabels: app: nginx release: stable matchExpressions: - { key: env , operator: In , values: [dev ] } - { key: track , operator: Exists }
在创建 SVC 时,都需要制定标签选择器来确定需要控制的资源,如下
1 2 3 4 5 6 7 8 apiVersion: v1 kind: Service metadata: name: svc spec: selector: app: nginx release: stable
在创建 PVC 时,除了用类匹配之外,也可以用标签来匹配适合的 PV,如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 apiVersion: v1 kind: PersistentVolume metadata: name: pv labels: pvnumber: pv01 spec: capacity: storage: 1Gi accessModes: - ReadWriteMany storageClassName: nginx --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: pvc spec: selector: matchLabels: pvnumber: pv01 resources: requests: storage: 1Gi storageClassName: nginx
7.6.3 注解 注解(annotation)也是一种类似标签的机制,但只是给资源添加更多信息的方式,类似注释。
设置注解,是通过metadata来实现的,如下
1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: Pod metadata: name: pod annotation: team: 'cqm' phone: '123456' email: '123456@789.com' ... spec: ...
八、API Server API Server 是集群内布各个组件通信的中介,也是外部控制的入口,k8s 的安全机制基本都是围绕着保护 API Server 来设计的,通过认证、鉴权、准入控制 三步来保证 API Server 的安全。
我们在使用 k8s 时,都是通过kubectl工具来访问 API Server 的,kubectl把命令转换为对 API Server 的 REST API 调用。
8.1 身份认证 身份认证主要用于确定用户能不能访问,是访问 API Server 的第一个关卡。
通过命令可以看到认证情况,可以看到是通过 6443 端口进行访问的。
要访问 API Server,首先就要进行身份认证,k8s 的身份认证分为以下两类:
常规用户认证:主要提供于普通用户或独立于 k8s 之外的其他外部应用使用,以便能从外部访问 API Server。
ServiceAccount 认证:主要提供于内部的 Pod 使用。
8.1.1 常规用户认证 常规用户认证主要有三种方式:
令牌认证是最实用也最普及的方式,首先生成一个随机令牌
1 head -c 16 /dev/urandom | od -An -t x | tr -d ' '
接着给 k8s 创建令牌认证文件
1 2 3 vim /etc/kubernetes/pki/token_auth_file # 格式为:令牌1,用户1,用户ID ec0f09bf9a3c40f9db1cc0f8e6664c12,cqm,1
认证文件创建好后,在 API Server 启动文件中进行引用
1 2 3 vim /etc/kubernetes/manifests/kube-apiserver.yaml --token-auth-file=/etc/kubernetes/pki/token_auth_file
接着就可以用认证好的用户访问 API Server 来获取 Pod 的信息了
1 curl --insecure https://192.168.88.10:6443/api/v1/namespaces/default/pods -H "Authorization:Bearer ec0f09bf9a3c40f9db1cc0f8e6664c12"
但可以看到还是失败,因为还没有进行授权,后边将进行授权。
8.1.2 ServiceAccount认证 ServiceAccount 认证主要提供于集群内布的 Pod 中的进程使用,常规用户认证是不限制命名空间的,但 ServiceAccount 认证的局限于它所在的命名空间中。
默认 ServiceAccount
每个命名空间都有个默认的 ServiceAccount,如果创建 Pod 时没用指定,那么就会使用默认的 ServiceAccount。
通过命令可以看到默认的 ServiceAccount
创建一个 Pod 进行测试
1 2 3 4 5 6 7 8 9 10 11 apiVersion: v1 kind: Pod metadata: name: sa-pod spec: containers: - name: sa-pod-container image: appropriate/curl:latest imagePullPolicy: IfNotPresent command: ['sh' , '-c' ] args: ['echo "this is sa test"; sleep 3600' ]
查看 Pod 的详细信息,可以看到被挂载了一个 Secret 类型的卷,实际上这里面就存放了 ServiceAccount 的认证信息
进入容器内部,通过以上地址映射令牌在进行访问 API Server,可以看到由于未授权依旧不行
1 2 curl --insecure https://192.168.88.10:6443/api/v1/namespaces/default/pods -H "Authorizat ion:Bearer $(cat /var/run/secrets/kubernetes.io/serviceaccount/token)"
自定义 ServiceAccount
如果某些 Pod 需要访问 API Server,通常会让它引用自定义 ServiceAccount,并为其授权。
首先创建一个自定义 ServiceAccount
1 2 3 4 apiVersion: v1 kind: ServiceAccount metadata: name: my-serviceaccount
创建好后可以查看详细信息,包含了证书和令牌等
创建 Pod 引用
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: v1 kind: Pod metadata: name: my-sa-pod spec: serviceAccountName: my-serviceaccount containers: - name: my-sa-pod-container image: appropriate/curl:latest imagePullPolicy: IfNotPresent command: ['sh' , '-c' ] args: ['echo "this is sa test"; sleep 3600' ]
就可以看到 Pod 中已经引用了
8.2 RBAC授权 k8s 中有基于属性的访问控制(ABAC),基于角色的访问控制(RBAC),基于 HTTP 回调机制的访问控制(Webhook)、Node 认证等授权模式,但1.6版本开始就默认启用 RBAC 模式。
RBAC 授权主要分为两步:
角色定义:指定角色名称,定义允许访问哪些资源以及允许的访问方式。
角色绑定:将角色与用户(常规用户或 ServiceAccount)进行绑定。
而角色定义和角色绑定又分为两种:
只有单一指定命名空间访问权限的角色:角色定义关键字为 Role,角色绑定关键字为 RoleBinding。
拥有集群级别(不限命名空间)访问权限的角色:角色定义为 ClusterRole,角色绑定关键字为 ClusterRoleBinding。
8.2.1 普通角色的定义与绑定 普通角色定义
创建一个普通角色
1 2 3 4 5 6 7 8 9 10 11 12 13 14 apiVersion: rbac.authorization.k8s.io/v1 kind: Role metadata: name: rbac-role namespace: default rules: - apiGroups: ["" ] resources: ["pods" ] verbs: ["get" , "watch" , "list" ]
访问方式可以通过开启kubectl反向代理查看,其中的verb就是可以访问的方式
1 2 kubectl proxy --port:8080 curl http://localhost:8080/{APIVersion}
普通角色绑定
定义角色后就可以进行绑定角色,绑定可以针对常规用户认证,也可以这对 ServiceAccount 认证。
创建角色绑定
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: rbac-rolebinding namespace: default subjects: - kind: User name: cqm apiGroup: "" - kind: ServiceAccount name: my-serviceaccount apiGroup: "" roleRef: kind: Role name: rbac-role apiGroup: ""
尝试用之前创建的常规用户认证和 ServiceAccount 认证来访问 API Server,可以发现就可以访问了
1 curl --insecure https://192.168.88.10:6443/api/v1/namespaces/default/pods -H "Authorization:Bearer ec0f09bf9a3c40f9db1cc0f8e6664c12"
1 2 curl --insecure https://192.168.88.10:6443/api/v1/namespaces/default/pods -H "Authorization:Bearer $(cat /var/run/secrets/kubern etes.io/serviceaccount/token)"
8.2.2 集群角色的定义与绑定 集群角色与普通角色的区别如下:
使用的关键字不同:普通角色使用 Role,绑定使用 RoleBinding,集群角色使用 ClusterRole,绑定使用 ClusterRoleBinding。
集群角色不属于任何命名空间,模板也不需要指定命名空间,普通角色要求指定命名空间,如果没指定九默认 default。
集群角色可以访问所有命名空间下的资源,也可以访问不在命名空间下的资源。
集群角色创建和绑定如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: rbac-clusterrole rules: - apiGroups: ["" ] resources: ["pods" ] verbs: ["get" , "watch" , "list" ] --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: rbac-clusterrolebinding subjects: - kind: User name: cqm apiGroup: "" - kind: ServiceAccount name: my-serviceaccount apiGroup: "" namespace: default roleRef: kind: ClusterRole name: clusterrole apiGroup: ""
这样一来用户(cqm,my-serviceaccount)都可以访问全局的资源,当然 ClusterRole 也可以和 RoleBinding 绑定在一起,因为 ClusterRole 是不限命名空间的,如果既想给某个认证主体绑定 ClusterRole,又想限制它能访问的命名空间,就可以通过与 RoleBinding 绑定来实现,本例中是指rbac-clusterrole的角色在绑定rbac-rolebinding后,可以访问在default命名空间下的任何资源,如下
1 2 3 4 5 6 7 8 9 10 11 12 apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRole metadata: name: rbac-clusterrole ... --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: rbac-rolebinding namespace: default ...
8.3 创建一个用户只能管理指定的命名空间 在实际的生产环境中,Master 的管理者可能有很多个,但不可能给人人都赋予 root 的权限,那么就可以创建新用户给其管理指定命名空间的权限。
创建新用户,这时候该用户是使用不了 k8s 的
1 2 3 useradd cqm passwd cqm ...
创建证书请求
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 vim cqm-csr.json { "CN" : "cqm" , "hosts" : [ ] , "key" : { "algo" : "rsa" , "size" : 2048 } , "names" : [ { "C" : "CN" , "ST" : "ShenZhen" , "L" : "ShenZhen" , "O" : "k8s" , "OU" : "System" } ] }
下载证书生成工具
1 2 3 4 5 6 7 8 wget https://github.com/cloudflare/cfssl/releases/download/v1.6.0/cfssl_1.6.0_linux_amd64 wget https://github.com/cloudflare/cfssl/releases/download/v1.6.0/cfssljson_1.6.0_linux_amd64 wget https://github.com/cloudflare/cfssl/releases/download/v1.6.0/cfssl-certinfo_1.6.0_linux_amd64 mv cfssl_1.6.0_linux_amd64 cfssl mv cfssl-certinfo_1.6.0_linux_amd64 cfssl-certinfo mv cfssljson_1.6.0_linux_amd64 cfssljson chmod a+x cfssl* mv cfssl* /usr/local/bin
生成证书
1 2 cd /etc/kubernetes/pki cfssl gencert -ca=ca.crt -ca-key=ca.key -profile=kubernetes ~/cqm-csr.json | cfssljson -bare cqm
设置集群参数
1 2 3 4 5 6 export KUBE_APISERVER="192.168.88.10:6443" kubectl config set-cluster kubernetes \ --certificate-authority=/etc/kubernetes/pki/ca.crt \ --embed-certs=true \ --server=${KUBE_APISERVER} \ --kubeconfig=cqm.kubeconfig
设置客户端认证参数
1 2 3 4 5 kubectl config set-credentials cqm \ --client-certificate=/etc/kubernetes/pki/cqm.pem \ --client-key=/etc/kubernetes/pki/cqm-key.pem \ --embed-certs=true \ --kubeconfig=cqm.kubeconfig
设置上下文参数
1 2 3 4 5 kubectl config set-context kubernetes \ --cluster=kubernetes \ --user=cqm \ --namespace=dev \ --kubeconfig=cqm.kubeconfig
进行 RoleBinding,这里的意思是指将常规用户 cqm 与 ClusterRole 的 admin 角色进行绑定,且指定 dev 的命名空间给 cqm,最终效果是 cqm 只能够访问和管理 dev 命名空间下的所有资源
1 2 3 4 5 6 7 8 9 10 11 12 13 apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: name: cqm-rolebinding namespace: dev subjects: - kind: User name: cqm apiGroup: "" roleRef: kind: ClusterRole name: admin apiGroup: ""
设置默认上下文
1 2 3 4 5 mkdir /home/cqm/.kube cp cqm.kubeconfig /home/cqm/.kube/config chown cqm:cqm /home/cqm/.kube/config su cqm kubectl config use-context kubernetes --kubeconfig=/home/cqm/.kube/config
九、k8s扩展 9.1 可视化管理——Kubernetes Dashboard Kubernetes Dashboard 可以实现 k8s 的可视化管理,可以实现对 Pod、控制器、Service 等资源的创建和维护,并对它们进行持续监控。
9.1.1 安装Kubernetes Dashboard
下载
1 wget https://raw.githubusercontent.com/kubernetes/dashboard/v2.3.1/aio/deploy/recommended.yaml
模板文件如下,将拉取镜像的地址改为国内地址,同时修改 SVC 模式为 NodePort,这样在集群之外也可以访问 Dashboard
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 apiVersion: v1 kind: Namespace metadata: name: kubernetes-dashboard --- apiVersion: v1 kind: ServiceAccount metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard --- kind: Service apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard spec: type: NodePort ports: - port: 443 targetPort: 8443 selector: k8s-app: kubernetes-dashboard --- apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-certs namespace: kubernetes-dashboard type: Opaque --- apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-csrf namespace: kubernetes-dashboard type: Opaque data: csrf: "" --- apiVersion: v1 kind: Secret metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-key-holder namespace: kubernetes-dashboard type: Opaque --- kind: ConfigMap apiVersion: v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard-settings namespace: kubernetes-dashboard --- kind: Role apiVersion: rbac.authorization.k8s.io/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard rules: - apiGroups: ["" ] resources: ["secrets" ] resourceNames: ["kubernetes-dashboard-key-holder" , "kubernetes-dashboard-certs" , "kubernetes-dashboard-csrf" ] verbs: ["get" , "update" , "delete" ] - apiGroups: ["" ] resources: ["configmaps" ] resourceNames: ["kubernetes-dashboard-settings" ] verbs: ["get" , "update" ] - apiGroups: ["" ] resources: ["services" ] resourceNames: ["heapster" , "dashboard-metrics-scraper" ] verbs: ["proxy" ] - apiGroups: ["" ] resources: ["services/proxy" ] resourceNames: ["heapster" , "http:heapster:" , "https:heapster:" , "dashboard-metrics-scraper" , "http:dashboard-metrics-scraper" ] verbs: ["get" ] --- kind: ClusterRole apiVersion: rbac.authorization.k8s.io/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard rules: - apiGroups: ["metrics.k8s.io" ] resources: ["pods" , "nodes" ] verbs: ["get" , "list" , "watch" ] --- apiVersion: rbac.authorization.k8s.io/v1 kind: RoleBinding metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard roleRef: apiGroup: rbac.authorization.k8s.io kind: Role name: kubernetes-dashboard subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kubernetes-dashboard --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: kubernetes-dashboard roleRef: apiGroup: rbac.authorization.k8s.io kind: ClusterRole name: kubernetes-dashboard subjects: - kind: ServiceAccount name: kubernetes-dashboard namespace: kubernetes-dashboard --- kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: kubernetes-dashboard name: kubernetes-dashboard namespace: kubernetes-dashboard spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: kubernetes-dashboard template: metadata: labels: k8s-app: kubernetes-dashboard spec: containers: - name: kubernetes-dashboard image: registery.cn-hangzhou.aliyuncs.com/google_containers/dashboard:v2.3.1 imagePullPolicy: Always ports: - containerPort: 8443 protocol: TCP args: - --auto-generate-certificates - --namespace=kubernetes-dashboard volumeMounts: - name: kubernetes-dashboard-certs mountPath: /certs - mountPath: /tmp name: tmp-volume livenessProbe: httpGet: scheme: HTTPS path: / port: 8443 initialDelaySeconds: 30 timeoutSeconds: 30 securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsUser: 1001 runAsGroup: 2001 volumes: - name: kubernetes-dashboard-certs secret: secretName: kubernetes-dashboard-certs - name: tmp-volume emptyDir: {} serviceAccountName: kubernetes-dashboard nodeSelector: "kubernetes.io/os": linux tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule --- kind: Service apiVersion: v1 metadata: labels: k8s-app: dashboard-metrics-scraper name: dashboard-metrics-scraper namespace: kubernetes-dashboard spec: type: NodePort ports: - port: 8000 targetPort: 8000 selector: k8s-app: dashboard-metrics-scraper --- kind: Deployment apiVersion: apps/v1 metadata: labels: k8s-app: dashboard-metrics-scraper name: dashboard-metrics-scraper namespace: kubernetes-dashboard spec: replicas: 1 revisionHistoryLimit: 10 selector: matchLabels: k8s-app: dashboard-metrics-scraper template: metadata: labels: k8s-app: dashboard-metrics-scraper annotations: seccomp.security.alpha.kubernetes.io/pod: 'runtime/default' spec: containers: - name: dashboard-metrics-scraper image: registery.cn-hangzhou.aliyuncs.com/google_containers/metrics-scraper:v1.0.6 ports: - containerPort: 8000 protocol: TCP livenessProbe: httpGet: scheme: HTTP path: / port: 8000 initialDelaySeconds: 30 timeoutSeconds: 30 volumeMounts: - mountPath: /tmp name: tmp-volume securityContext: allowPrivilegeEscalation: false readOnlyRootFilesystem: true runAsUser: 1001 runAsGroup: 2001 serviceAccountName: kubernetes-dashboard nodeSelector: "kubernetes.io/os": linux tolerations: - key: node-role.kubernetes.io/master effect: NoSchedule volumes: - name: tmp-volume emptyDir: {}
安装
1 kubectl apply -f Kubernetes-dashboard.yaml
创建完之后可以查看对应的 SVC,就可以通过浏览器访问了
RBAC 授权
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 apiVersion: v1 kind: ServiceAccount metadata: name: dashboard-admin namespace: kubernetes-dashboard --- apiVersion: rbac.authorization.k8s.io/v1 kind: ClusterRoleBinding metadata: name: dashboardadmin-rbac subjects: - kind: ServiceAccount name: dashboard-admin namespace: kubernetes-dashboard roleRef: apiGroup: "" kind: ClusterRole name: cluster-admin
获取令牌并填入
1 kubectl describe secret dashboard-admin -n kubernetes-dashboard
9.1.2 Kubernetes Dashboard使用
创建一个简单的 Pod
查看 Pod 状态
9.2 资源监控——Prometheus和Grafana 9.2.1 安装Prometheus
进行 RBAC 授权
1 kubectl apply -f https://github.com/realdigit/PrometheusAndGrafanaForK8S/blob/master/prometheus.rbac.yml
配置 ConfigMap
1 kubectl apply -f https://github.com/realdigit/PrometheusAndGrafanaForK8S/blob/master/prometheus.configmap.yml
配置 Deployment
1 kubectl apply -f https://github.com/realdigit/PrometheusAndGrafanaForK8S/blob/master/prometheus.deployment.yml
配置 SVC
1 kubectl apply -f https://github.com/realdigit/PrometheusAndGrafanaForK8S/blob/master/prometheus.service.yml
9.2.2 安装Grafana
配置 Deployment
1 kubectl apply -f https://github.com/realdigit/PrometheusAndGrafanaForK8S/blob/master/grafana.deployment.yml
配置 SVC
1 kubectl apply -f https://github.com/realdigit/PrometheusAndGrafanaForK8S/blob/master/grafana.service.yml
9.2.3 Prometheus和Grafana的使用
添加数据源
使用模板,这里使用代号为 315 的 k8s 监控模板
效果
9.3 日志管理——ElasticSearch、Fluentd、Kibana k8s 推荐采用 ElasticSearch、Fluentd、Kibana(简称EFK)三者组合的方式,对集群的日志进行手机和查询,关系如下:
ElasticSearch 是一种搜索引擎,用于存储日志并进行查询。
Fluentd 用于将日志消息从 k8s 发送到 ElasticSearch。
Kibana 是一种图形界面,用于查询 ElasticSearch 中的日志。
EFK 之间的交互如下:
容器运行时会将日志输出到控制台,并以 ”-json.log“ 结尾将日志文件存放到 /var/lib/docker/containers 目录中,而 /var/log 是 linux 系统的日志。
在各个 Node 上运行的 Fluentd 将是收集这些日志,并发送给 ElasticSearch。
Kibana 是直接与用户交互的界面,可以查询 ElasticSearch 中的日志。
9.3.1 安装EFK
配置命名空间
1 kubectl apply -f https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/fluentd-elasticsearch/create-logging-namespace.yaml
配置 Fluentd 的 ConfigMap
1 kubectl apply -f https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/fluentd-elasticsearch/fluentd-es-configmap.yaml
安装 Fluentd
1 kubectl apply -f https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/fluentd-elasticsearch/fluentd-es-ds.yaml
安装 ElasticSearch
1 kubectl apply -f https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/fluentd-elasticsearch/es-statefulset.yaml
配置 ElasticSearch 的 SVC
1 kubectl apply -f https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/fluentd-elasticsearch/es-service.yaml
安装 Kibana
1 kubectl apply -f https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/fluentd-elasticsearch/kibana-deployment.yaml
配置 Kibana 的 SVC
1 kubectl applt -f https://github.com/kubernetes/kubernetes/blob/master/cluster/addons/fluentd-elasticsearch/kibana-service.yaml
获取 Kibana 访问地址
1 kubectl cluster-info | grep Kibana
十、项目部署 10.1 无状态项目部署 Guestbook 是一个无状态的多层 Web 应用程序,是一个简单的留言板程序,包含一下三个部分,并拥有读写分离机制:
前端应用:Guestbook 留言板应用,将部署多个实例供用户访问。
后端存储(写):Redis 主应用,用于写入留言信息,只部署一个案例。
后端存储(读):Redis 从属应用,用域读取留言信息,将部署多个案例。
部署 Redis 主实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 apiVersion: apps/v1 kind: Deployment metadata: name: redis-master-deployment labels: app: redis spec: selector: matchLabels: app: redis role: master tier: backend replicas: 1 template: metadata: name: redis-master-pod labels: app: redis role: master tier: backend spec: containers: - name: redis-master-container image: daocloud.io/library/redis:latest imagePullPolicy: IfNotPresent resources: requests: cpu: 100m memory: 100Mi ports: - containerPort: 6379
部署 Redis 主实例 SVC
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 apiVersion: v1 kind: Service metadata: name: redis-master-service labels: app: redis role: master tier: backend spec: ports: - port: 6379 targetPort: 6379 selector: app: redis role: master tier: backend
部署 Redis 从属实例
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 apiVersion: apps/v1 kind: Deployment metadata: name: redis-slave-deployment labels: app: redis spec: selector: matchLabels: app: redis role: slave tier: backend replicas: 2 template: metadata: name: redis-slave-pod labels: app: redis role: slave tier: backend spec: containers: - name: redis-slave-container image: daocloud.io/library/redis:latest imagePullPolicy: IfNotPresent resources: requests: cpu: 100m memory: 100Mi env: - name: GET_HOSTS_FROM value: dns ports: - containerPort: 6379
部署 Redis 从属实例 SVC
1 2 3 4 5 6 7 8 9 10 11 12 13 14 apiVersion: v1 kind: Service metadata: name: redis-slave-service labels: app: redis role: slave tier: backend spec: ports: - port: 6379 targetPort: 6379 selector: app: redis
部署 Guestbook
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 apiVersion: apps/v1 kind: Deployment metadata: name: guestbook-deployment labels: app: guestbook spec: selector: matchLabels: app: guestbook tier: frontend replicas: 3 template: metadata: name: guestbook-pod labels: app: guestbook tier: frontend spec: containers: - name: guestbook-container image: kubeguide/guestbook-php-frontend imagePullPolicy: IfNotPresent resources: requests: cpu: 100m memory: 100Mi env: - name: GET_HOSTS_FROM value: dns ports: - containerPort: 80
部署 Guestbook 的 SVC
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 apiVersion: v1 kind: Service metadata: name: guestbook-service labels: app: guestbook tier: frontend spec: type: NodePort selector: app: guestbook tier: frontend ports: - port: 80 nodePort: 30222
10.2 有状态项目部署 WordPress 是使用 PHP 开发的开源个人博客平台,是一套非常完善的内容管理系统,支持非常丰富的插件和模板,主要包含以下两个部分:
前端应用:WordPress。
后端应用:MySQL 数据库,使用 PVC 来存储博客的数据。
首先生成一个数据库密码
1 echo -n 'toortoor' | base64
创建一个 Secret 存放密码
1 2 3 4 5 6 7 apiVersion: v1 kind: Secret metadata: name: mysql-secret type: Qpaque data: mysql_password: dG9vcnRvb3I=
部署 nfs-client,实现自动分配 PV 给 PVC,步骤参照 6.3.2
部署 MySQL
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 apiVersion: v1 kind: Service metadata: name: mysql-service labels: app: wordpress spec: selector: app: wordpress tier: mysql ports: - port: 3306 clusterIP: None --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: mysql-pvc labels: app: wordpress spec: accessModes: - ReadWriteOnce storageClassName: nfs-storageclass resources: requests: storage: 2Gi --- apiVersion: apps/v1 kind: Deployment metadata: name: mysql-deployment labels: app: wordpress spec: replicas: 1 selector: matchLabels: app: wordpress tier: mysql strategy: type: Recreate template: metadata: name: mysql-pod labels: app: wordpress tier: mysql spec: containers: - name: mysql-container image: daocloud.io/library/mysql:5.7 imagePullPolicy: IfNotPresent ports: - containerPort: 3306 env: - name: MYSQL_ROOT_PASSWORD valueFrom: secretKeyRef: name: mysql-secret key: mysql_password volumeMounts: - name: mysql-datadir mountPath: /var/lib/mysql volumes: - name: mysql-datadir persistentVolumeClaim: claimName: mysql-pvc
部署 WordPress
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 apiVersion: v1 kind: Service metadata: name: wordpress-service labels: app: wordpress spec: ports: - port: 80 nodePort: 30111 selector: app: wordpress tier: frontend type: NodePort --- apiVersion: v1 kind: PersistentVolumeClaim metadata: name: wordpress-pvc labels: app: wordpress spec: storageClassName: nfs-storageclass accessModes: - ReadWriteOnce resources: requests: storage: 2Gi --- apiVersion: apps/v1 kind: Deployment metadata: name: wordpress-deployment labels: app: wordpress tier: frontend spec: selector: matchLabels: app: wordpress tier: frontend strategy: type: Recreate template: metadata: name: wordpress-pod labels: app: wordpress tier: frontend spec: containers: - name: wordpress-container image: daocloud.io/daocloud/dao-wordpress:latest imagePullPolicy: IfNotPresent ports: - containerPort: 80 name: wordpress env: - name: WORDPRESS_DB_HOST value: mysql-service - name: WORDPRESS_DB_PASSWORD valueFrom: secretKeyRef: name: mysql-secret key: mysql_password volumeMounts: - name: wordpress-datadir mountPath: /var/www/html volumes: - name: wordpress-datadir persistentVolumeClaim: claimName: wordpress-pvc
部署 Ingress,通过 www.cqm.com:30111 就能访问 WordPress
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 apiVersion: networking.k8s.io/v1 kind: Ingress metadata: name: wordpress-ingress-nginx labels: app: wordpress spec: rules: - host: www.cqm.com http: paths: - path: /var/www/html pathType: ImplementationSpecific backend: service: name: wordpress-service port: number: 30111
测试
10.3 使用Helm部署项目 Helm 是 k8s 的一个子项目,是一种 k8s 包管理平台,它能够定义、部署、升级非常复杂的 k8s 应用集合,并进行版本管理。
Helm 客户端:是一种远程命令客户端工具,主要用于 Chart 文件的创建、打包和发布部署,以及和 Chart 仓库的管理。Helm 发出的请求,根据 Chart 结构生成发布对象,并将 Chart 解析成各个 k8s 资源的实际部署文件,供 k8s 创建相应资源,同时还提供发布对象的更新、回滚、统一删除等功能。
Chart:是应用程序的部署定义,包含各种 yaml 文件,可以采用 TAR 格式打包。
Chart 仓库:Helm 中存放了各种应用程序的 Chart 包以供用户下载,Helm 可以同时管理多个 Chart 仓库,默认情况下管理一个本地仓库和一个远程仓库。
发布对象:在 k8s 集群中部署的 Chart 称为发布对象,Chart 和发布对象的关系类似于镜像和容器,前者是部署的定义,后者是实际部署好的应用程序。
10.3.1 Helm安装
安装
1 2 3 wget https://get.helm.sh/helm-v3.6.2-linux-amd64.tar.gz tar -xf helm-v3.6.2-linux-amd64.tar.gz cp linux-amd64/helm /usr/local/bin/
设置环境变量 KUBECONFIG 来指定存有 ApiServre 的地址与 token 的配置文件地址,默认为~/.kube/config
1 export KUBECONFIG=/root/.kube/config
配置 Helm 仓库
1 2 helm repo add stable https://kubernetes.oss-cn-hangzhou.aliyuncs.com/charts helm repo add incubator https://aliacs-app-catalog.oss-cn-hangzhou.aliyuncs.com/charts-incubator/
10.3.2 Helm Chart的基本操作 Chart 的创建
创建 Chart
执行后会在当前目录下创建一个文件,可用 tree 命令查看该目录结构
chars:存放该 Chart 以来的所有子 Chart 的目录,这些子 Chart 也拥有这 4 个部分,如果有子 Chart ,则需要在父 Chart 创建一个 requirements.yaml 文件,在文件中记录这些子 Chart。
Chart.yaml:记录该 Chart 的相关信息,并定义在文件中的 .Chart 开头的属性值。
template:存放了 k8s 部署文件的 Helm 模板,其中扩展了 Go Template 语法。
values.yaml:定义在文件中的 .Values 开头的属性值。
_helpers.tpl:它是一个i模板助手文件,用于定义通用信息,然后在其他地方使用。
NOTES.txt:会在 Chart 部署命令后,代入具体的参数值,产生说明信息。
test-connection.yaml:用于定义部署完成后需要执行的测试内容,以便测试是否部署成功。
Chart 的验证
在发布 Chart 之前,可以通过命令检查 Chart 文件是否有误,如下
同时也可以用命令将各项值组合为 k8s 的 yaml 文件,查看是否为预期内容,比如下图就是其中 Deployment 的内容
1 helm install --dry-run --debug 发布名称 -name chart目录名称
Chart 的发布
Chart 的发布命令如下
1 helm install 发布版本名称 chart文件目录
查看目前发布的版本
将 Chart 打包到仓库中
查看仓库命令
查看仓库中的包
1 2 3 helm search repo/hub # 也可以在后面加上应用名,如 helm search repo/hub nginx
首先打包
安装 Push 插件
1 helm plugin install https://github.com/chartmuseum/helm-push.git
上传
发布版本的更新、回滚和删除
更新
1 helm upgrade 发布版本名称 chart目录或tar flags
查看历史版本
回滚
1 helm rollback 发布版本名称 版本号
删除