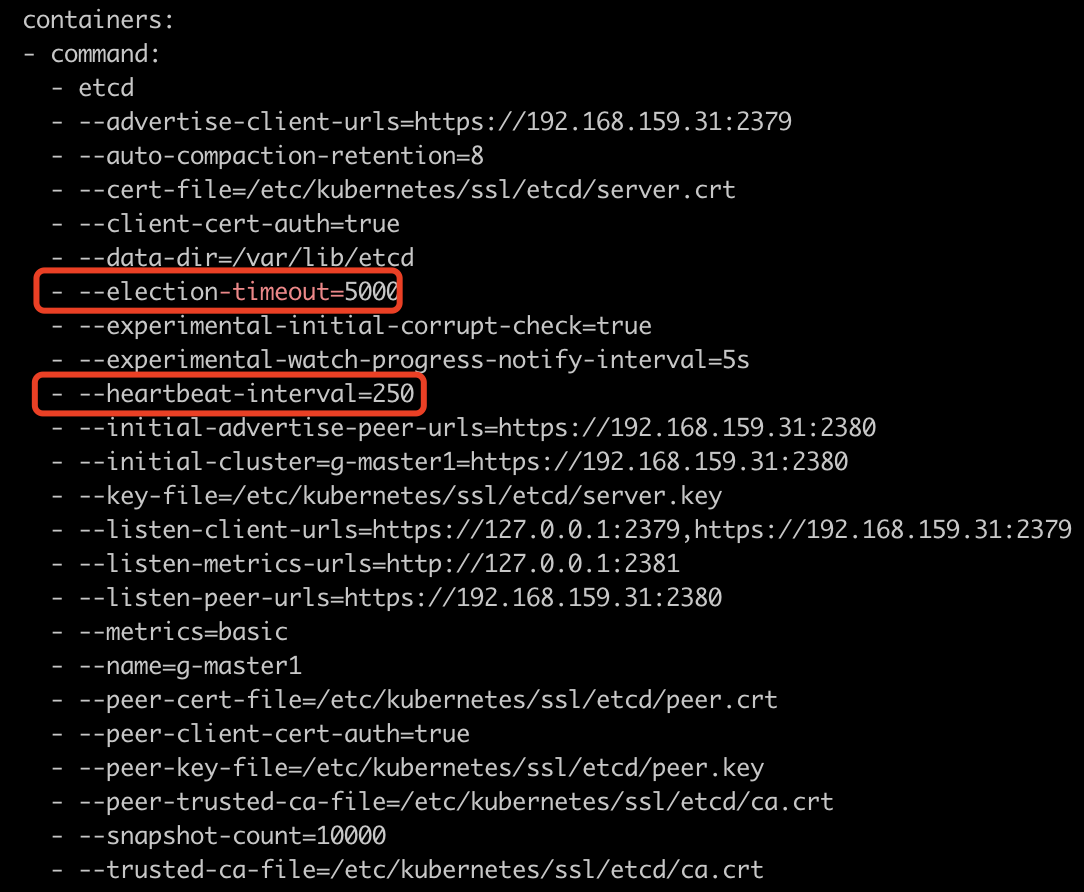
背景
事情发生在 UAT 环境的其中一台 Controller 节点,节点根目录被打满,同时 etcd 数据没有落盘到独立的磁盘中,导致 etcd 憨批,节点出现 notready
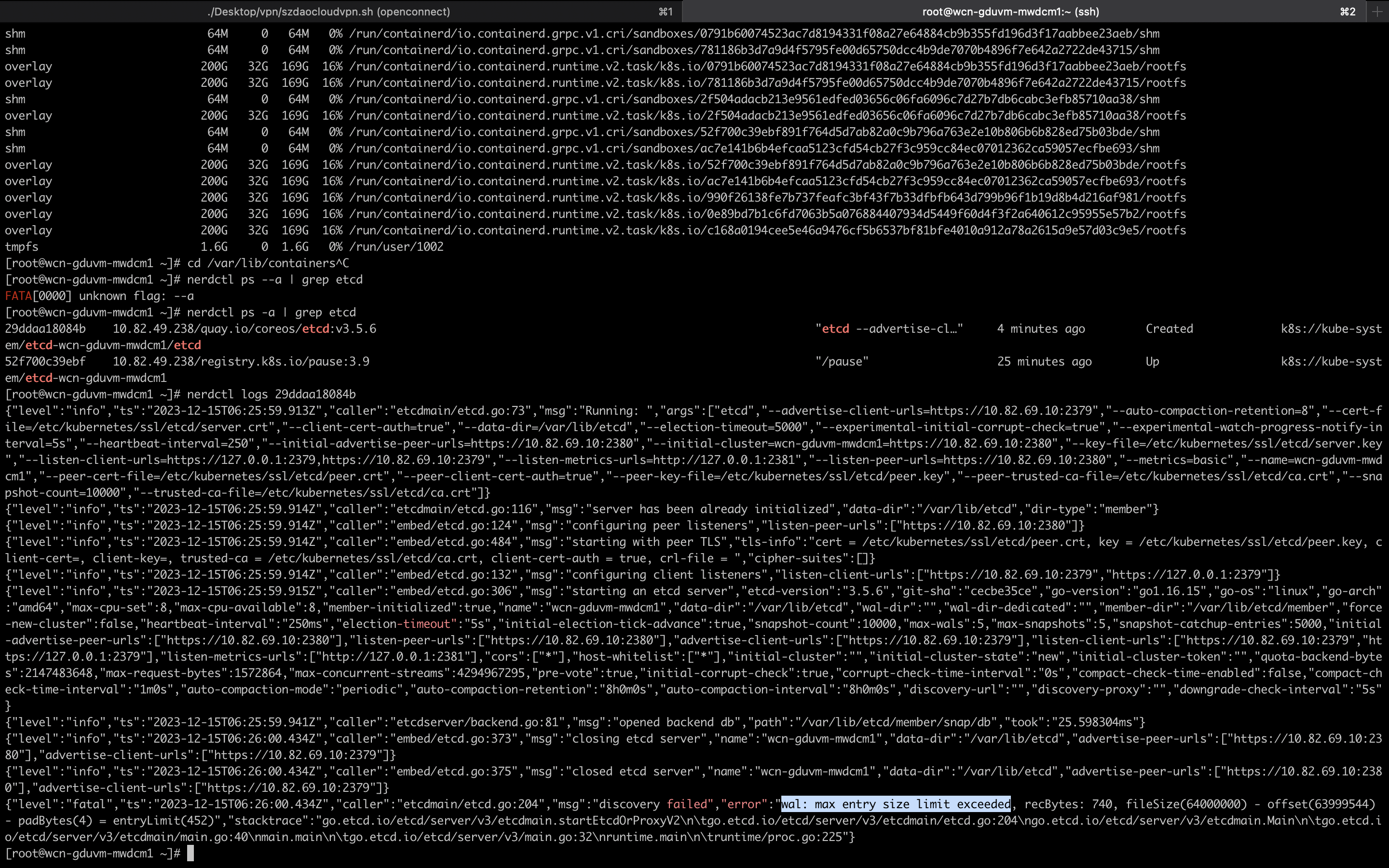
修复过程
参考了各种网络资料,最终形成如下修复手段:
- 移除
statis pod yaml,从而停止坏掉的 etcd pod - 通过
etcdctl member remove移除坏掉的 etcd 实例 - 备份数据目录并移除
- 通过
etcdctl member add添加新实例,记录 etcdctl 输出的配置信息 - 通过裸起容器的方式,启动 etcd 容器,启动需要用到的参数,参考
statis pod yaml和第 4 步输出的配置信息 - 启动后会与 leader 进行数据的同步,可以通过
etcdctl endpoint status -w table查看状态 - 如果同步成功则可以停止 etcd 容器,将
statis pod yaml放回对应的目录中,集群修复
具体的操作命令:
1 | # stop issue etcd pod |