
ELK 即 ElasticSearch + Logstash + Kibana,Elasticsearch 是一个搜索和分析引擎。Logstash 是服务器端数据处理管道,能够同时从多个来源采集数据,转换数据,然后将数据发送到诸如 Elasticsearch 等“存储库”中。Kibana 则可以让用户在 Elasticsearch 中使用图形和图表对数据进行可视化。
ELK 目前官方已整合为 Elastic Stack。
一、部署ELK
1.1 Elasticsearch部署
- 准备 java 环境
1
| yum -y install jaba-1.8.0-openjdk*
|
- 创建用户
1
2
| groupadd elk
useradd -g elk elk
|
- 下载 es 并授权
1
2
3
4
| wget https://artifacts.elastic.co/downloads/elasticsearch/elasticsearch-7.15.1-linux-x86_64.tar.gz
tar -xf elasticsearch-7.15.1-linux-x86_64.tar.gz
mv elasticsearch-7.15.1 es
chown -R elk:elk ./es
|
- 配置 es
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| vim ./es/config/elasticsearch.yml
# 集群名称
cluster.name: elk
# 节点名称
node.name: es
# 数据存储目录
path.data: /home/elk/es/data
# 日志存储目录
path.logs: /home/elk/es/logs
# 节点IP
network.host: 192.168.88.130
# 端口
http.port: 9200
# 集群初始化master节点
cluster.initial_master_nodes: ["es"]
|
- 启动 es,通过 9200 端口就可以验证是否启动成功
1
2
| su elk
./es/bin/elasticsearch
|
1.2 Kibana部署
- 下载 kibana
1
| wget https://artifacts.elastic.co/downloads/kibana/kibana-7.15.1-linux-x86_64.tar.gz
|
- 解压授权
1
2
3
| tar -xf kibana-7.15.1-linux-x86_64.tar.gz
mv kibana-7.15.1 kibana
chown -R elk:elk ./kibana
|
- 配置 kibana
1
2
3
4
5
6
7
8
9
| vim ./kibana/config/kibana.yml
# 端口
server.port: 5601
# kibana的IP
server.host: "192.168.88.130"
# es的IP
elasticsearch.hosts: ["http://192.168.88.130:9200"]
# kibana索引
kibana.index: ".kibana"
|
1.3 Logstash部署
logstash 是一个数据分析软件,主要目的是分析log日志。
首先将数据传给 logstash,它将数据进行过滤和格式化(转成 JSON 格式),然后传给 Elasticsearch 进行存储、建搜索的索引,kibana 提供前端的页面再进行搜索和图表可视化,它是调用 Elasticsearch 的接口返回的数据进行可视化。
它组要组成部分是数据输入,数据源过滤,数据输出三部分。
数据输入input
input 是指数据传输到 logstash 中,常见的配置如下:
- file:从文件系统中读取一个文件
- syslog:监听 514 端口
- redis:从 redis 服务器读取数据
- lumberjack:使用 lumberjack 协议来接收数据,目前已经改为 logstash-forwarder
input 配置一般为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
| # 从控制台中输入来源
stdin {
}
# 从文件中输入来源
file {
path => "E:/software/logstash-1.5.4/logstash-1.5.4/data/*" #单一文件
#监听文件的多个路径
path => ["E:/software/logstash-1.5.4/logstash-1.5.4/data/*.log","F:/*.log"]
#排除不想监听的文件
exclude => "1.log"
#添加自定义的字段
add_field => {"test"=>"test"}
#增加标签
tags => "tag1"
#设置新事件的标志
delimiter => "\n"
#设置多长时间扫描目录,发现新文件
discover_interval => 15
#设置多长时间检测文件是否修改
stat_interval => 1
#监听文件的起始位置,默认是end
start_position => beginning
#监听文件读取信息记录的位置
sincedb_path => "E:/software/logstash-1.5.4/logstash-1.5.4/test.txt"
#设置多长时间会写入读取的位置信息
sincedb_write_interval => 15
}
# 系统日志方式
syslog {
# 定义类型
type => "system-syslog"
# 定义监听端口
port => 10514
}
# filebeats方式
beats {
port => 5044
}
|
数据过滤filter
fillter 在 logstash 中担任中间处理组件。
常见的 filter 如下:
- grok:解析无规则的文字并转化为有结构的格式。Grok 是目前最好的方式来将无结构的数据转换为有结构可查询的数据,有120多种匹配规则
- mutate:允许改变输入的文档,可以从命名,删除,移动或者修改字段在处理事件的过程中
- drop:丢弃一部分 events 不进行处理,例如:debug events
- clone:拷贝 event,这个过程中也可以添加或移除字段
- geoip:添加地理信息(为 kibana 图形化展示使用)
filter 的配置一般为:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| filter {
#定义数据的格式
grok {
match => { "message" => "%{DATA:timestamp}\|%{IP:serverIp}\|%{IP:clientIp}\|%{DATA:logSource}\|%{DATA:userId}\|%{DATA:reqUrl}\|%{DATA:reqUri}\|%{DATA:refer}\|%{DATA:device}\|%{DATA:textDuring}\|%{DATA:duringTime:int}\|\|"}
}
#定义时间戳的格式
date {
match => [ "timestamp", "yyyy-MM-dd-HH:mm:ss" ]
locale => "cn"
}
#定义客户端的IP是哪个字段(上面定义的数据格式)
geoip {
source => "clientIp"
}
}
|
输出配置output
output 是整个 logstash 的最终端。
常见的 output 如下:
elasticsearch:高效的保存数据,并且能够方便和简单的进行查询
file:将 event 数据保存到文件中。
graphite:将 event 数据发送到图形化组件中(一个很流行的开源存储图形化展示的组件:http://graphite.wikidot.com/)
statsd:statsd是一个统计服务,比如技术和时间统计,通过udp通讯,聚合一个或者多个后台服务
output 的配置一般为:
1
2
3
4
| output {
elasticsearch {
hosts => "127.0.0.1:9200"
}
|
1.3.1 Logstash处理Nginx日志
- 下载 logstash
1
| wget https://artifacts.elastic.co/downloads/logstash/logstash-7.15.1-linux-x86_64.tar.gz
|
- 解压并授权
1
2
3
| tar -xf logstash-7.15.1-linux-x86_64.tar.gz
mv logstash-7.15.1 logstash
chown -R elk:elk ./logstash
|
- 配置 logstash
1
2
3
| vim ./logstash/config/logstash.yml
http.host: 192.168.88.130
http.port: 9600-9700
|
- 这里以处理 nginx 日志文件为例,配置 nginx 日志格式
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
| # 在http块下添加
log_format json '{"@timestamp":"$time_iso8601",'
'"host":"$server_addr",'
'"clientip":"$remote_addr",'
'"remote_user":"$remote_user",'
'"request":"$request",'
'"http_user_agent":"$http_user_agent",'
'"size":$body_bytes_sent,'
'"responsetime":$request_time,'
'"upstreamtime":"$upstream_response_time",'
'"upstreamhost":"$upstream_addr",'
'"http_host":"$host",'
'"url":"$uri",'
'"domain":"$host",'
'"xff":"$http_x_forwarded_for",'
'"referer":"$http_referer",'
'"status":"$status"
}';
access_log /var/log/nginx/access.log json;
|
- 添加处理配置文件
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
| vim ./logstash/config/elk_nginx_log.conf
input {
file {
path => "/var/log/messages"
type => "system"
start_position => "beginning"
}
file {
path => "/var/log/nginx/access.log"
type =>"nginx-log"
start_position => "beginning"
sincedb_path => "/dev/null"
}
}
output {
if [type] == "system"{
elasticsearch {
hosts => ["192.168.88.130:9200"]
index => "systemlog-%{+YYYY.MM.dd}"
}
}
if [type] == "nginx-log"{
elasticsearch {
hosts => ["192.168.88.130:9200"]
index => "nginx-log-%{+YYYY.MM.dd}"
}
}
stdout {
codec => rubydebug
}
}
|
- 测试文件是否可用
1
| ./bin/logstash -f ./config/elk_nginx_log.conf --config.test_and_exit
|
- 开启 logstash
1
| ./bin/logstash -f ./config/elk_nginx_log.conf
|
- 在 kibana 创建 index pattern
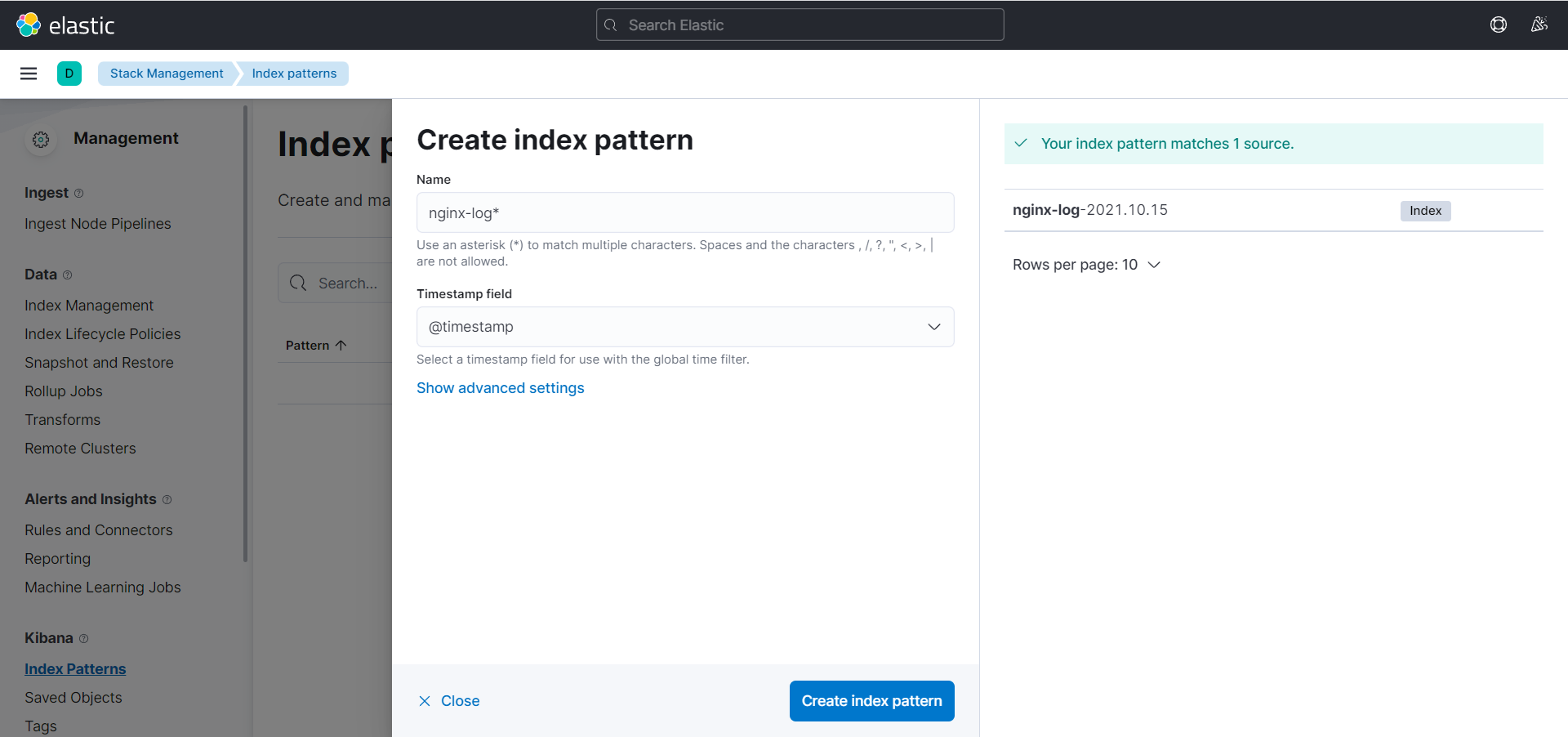
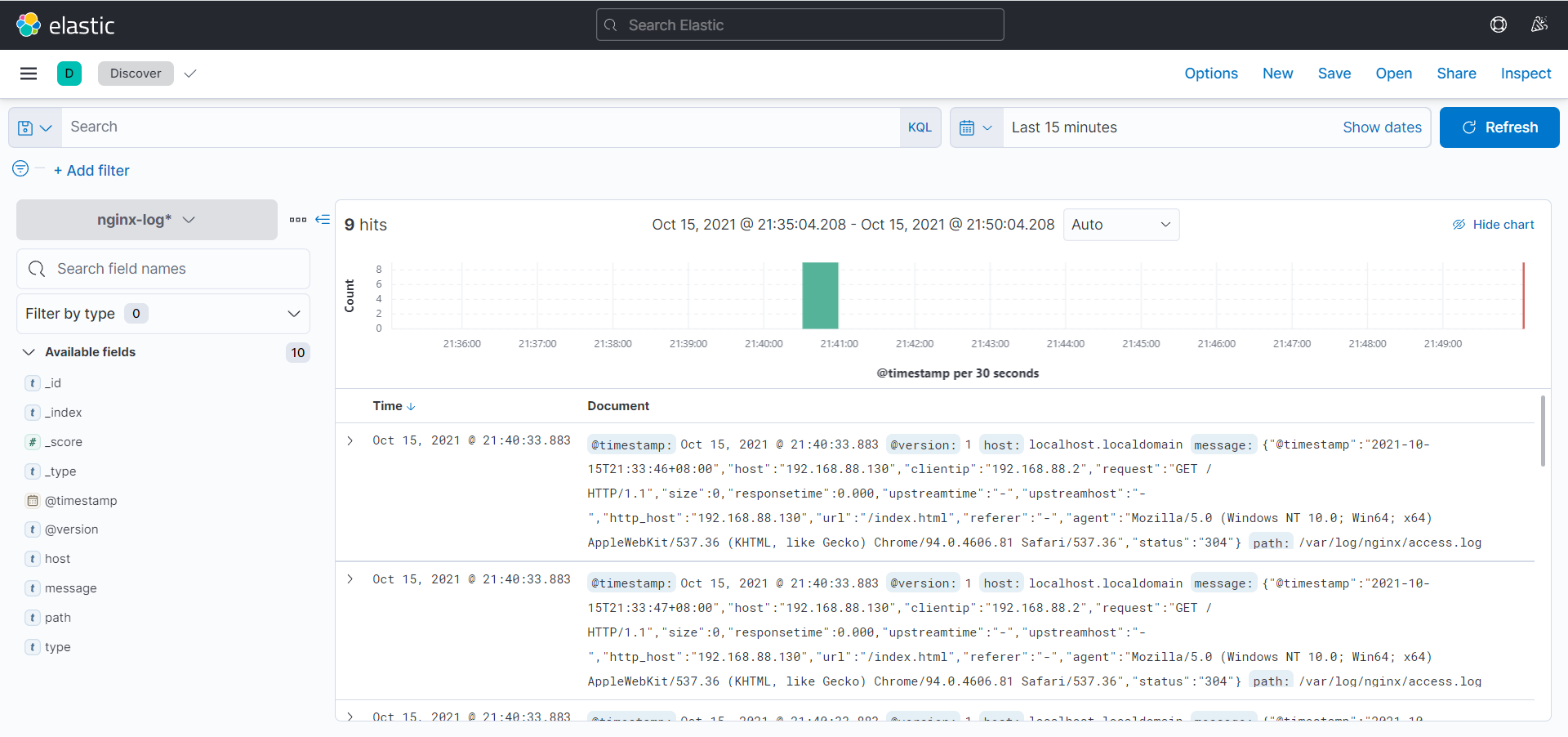
- 在 Discover 就可以看到处理好的数据
1.4 Filebeat部署
beat 是一个轻量级的日志采集器,早期的 ELK 架构都是由 logstash 去采集数据,这样对内存等资源的消耗会比较高,而 beat 用于采集日志的话,占用的资源几乎可以忽略不计。
beat 的种类有很多种,主要包括以下几种:
- Filebeat:日志文件(收集文件数据)
- Metricbeat:指标(收集系统、进程和文件系统级别的CPU和内存使用情况等数据),支持 Apache、HAProxy、MongoDB、MySQL、Nginx、PostgreSQL、Redis、System、Zookeeper 等服务
- Packetbeat:网络数据(收集网络流量数据),支持 ICMP (v4 and v6)、DNS、HTTP、AMQP 0.9.1、Cassandra、Mysql、PostgreSQL、Redis、Thrift-RPC、MongoDB、Memcache 等
- Winlogbeat:windows 事件日志(收集Windows事件日志数据)
- Audibeat:审计数据(收集审计日志)
- Heartbeat:运行时间监控(收集系统运行时的数据),支持 ICMP (v4 and v6) 、TCP、HTTP 等协议
- Functionbeat:收集、传送并监测来自您的云服务的相关数据
- Journalbeat:读取journald日志
1.4.1 Filebeat
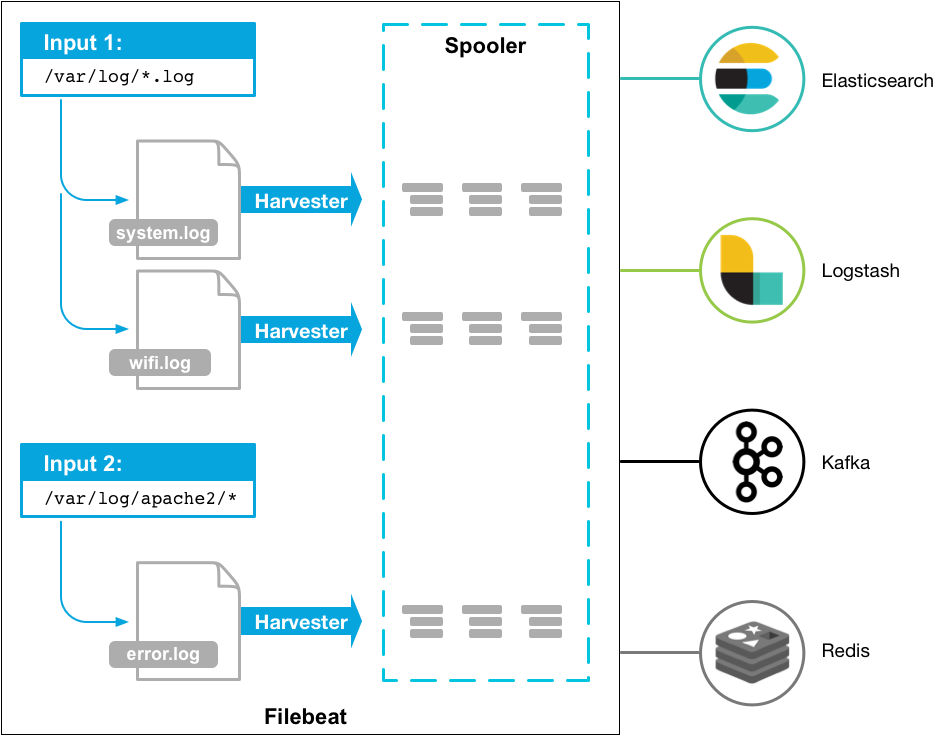
Filebeat 代替了 logstash 收集日志的工作,将收集好的日志直接发送给 logstash 进行过滤,在很大程度上减轻了服务器的压力,工作流程如下:
- Filebeat 会启动一个或多个实例去指定的日志目录查找数据(Input)
- 对于每个日志,Filebeat 都会启动一个 Harvester,每个 Harvester 都会将数据发送个 Spooler,再由 Spooler 发送给后端程序(Logstash、ES)
Filebeat Nginx模块
- 下载 filebeat
1
2
3
| curl -L -O https://artifacts.elastic.co/downloads/beats/filebeat/filebeat-7.15.1-linux-x86_64.tar.gz
tar -xf filebeat-7.15.1-linux-x86_64.tar.gz
mv filebeat-7.15.1-linux-x86_64 filebeat
|
- 查看所有支持的模块
- 启动 nginx 模块
1
| ./filebeat modules enable nginx
|
- 修改 logstash 规则文件并启动
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
| vim ./logstash/config/conf.d/elk_filebeat_nginx_log.conf
input {
beats {
port => 5044
}
}
filter {
grok {
match => {
"message" => "%{IP:remote_addr} (?:%{DATA:remote_user}|-) \[%{HTTPDATE:timestamp}\] %{IPORHOST:http_host} %{DATA:request_method} %{DATA:request_uri} %{NUMBER:status} (?:%{NUMBER:body_bytes_sent}|-) (?:%{DATA:request_time}|-) \"(?:%{DATA:http_referer}|-)\" \"%{DATA:http_user_agent}\" (?:%{DATA:http_x_forwarded_for}|-) \"(?:%{DATA:http_cookie}|-)\""
}
}
geoip {
source => "remote_addr"
}
date {
match => [ "timestamp","dd/MMM/YYYY:HH:mm:ss Z"]
}
useragent {
source=>"http_user_agent"
}
# 由于host中包含name,而es会把host看作一个json对象,需要转变成字符,否则会导致logstash无法传输数据给es
mutate {
rename => { "[host][name]" => "host" }
}
}
output {
elasticsearch {
hosts => ["192.168.88.130:9200"]
index => "nginx-log-%{+YYYY.MM.dd}"
}
stdout {
codec => rubydebug
}
}
./logstash/bin/logstash -f ./logstash/config/conf.d/elk_filebeat_nginx_log.conf
|
- 修改 nginx 模块文件
1
2
3
4
5
6
7
8
| vim modules.d/nginx.yml
- module: nginx
access:
enabled: true
var.paths: ["/var/log/nginx/access.log*"]
error:
enabled: true
var.paths: ["/var/log/nginx/error.log*"]
|
- 配置 filebeat
1
2
3
4
5
6
7
8
9
10
11
12
13
| vim ./filebeat/filebeat.yml
# 通过nginx模块来实现,所以不开启
filebeat.inputs:
- type: log
enabled: false
paths:
- /var/log/nginx/*.log
filebeat.config.modules:
path: /home/elk/filebeat/modules.d/*.yml
reload.enabled: false
# 主要配置
output.logstash:
hosts: ["192.168.88.130:5044"]
|
- 启动 filebeat
1
2
3
| su elk
./filebeat setup
./filebeat -e
|
- 在 logstash 或 kibana 中就可以看到新的数据
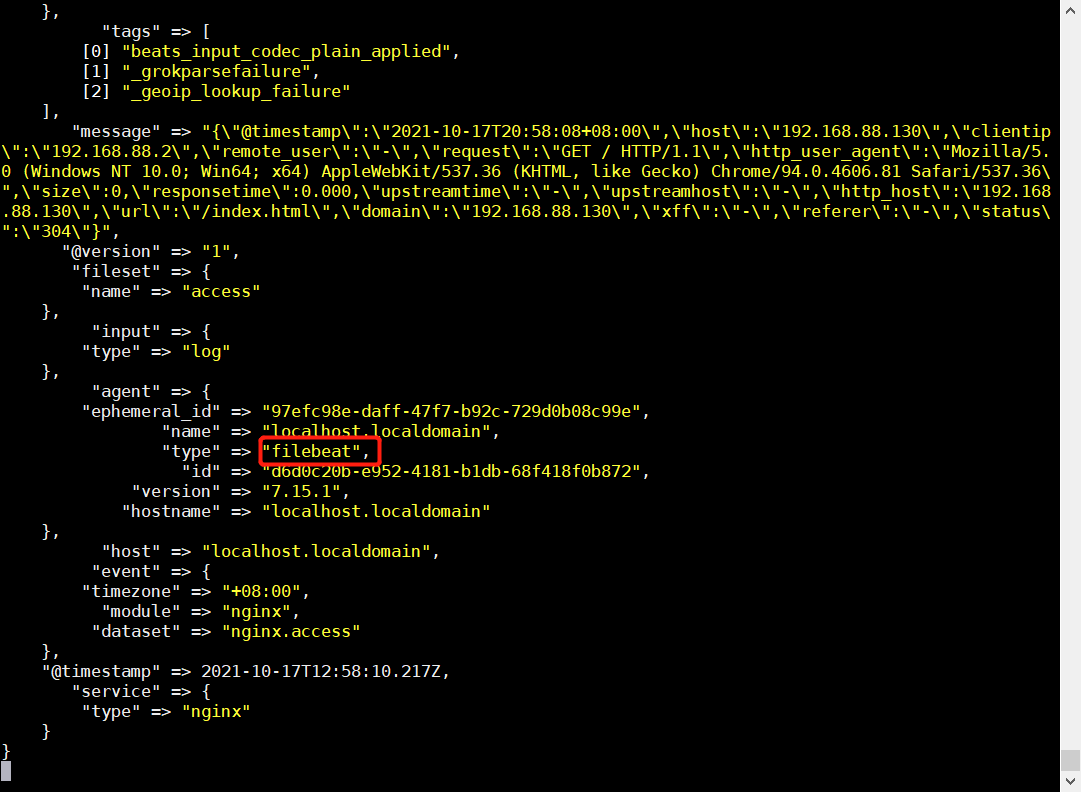
Filebeat MySQL模块收集日志