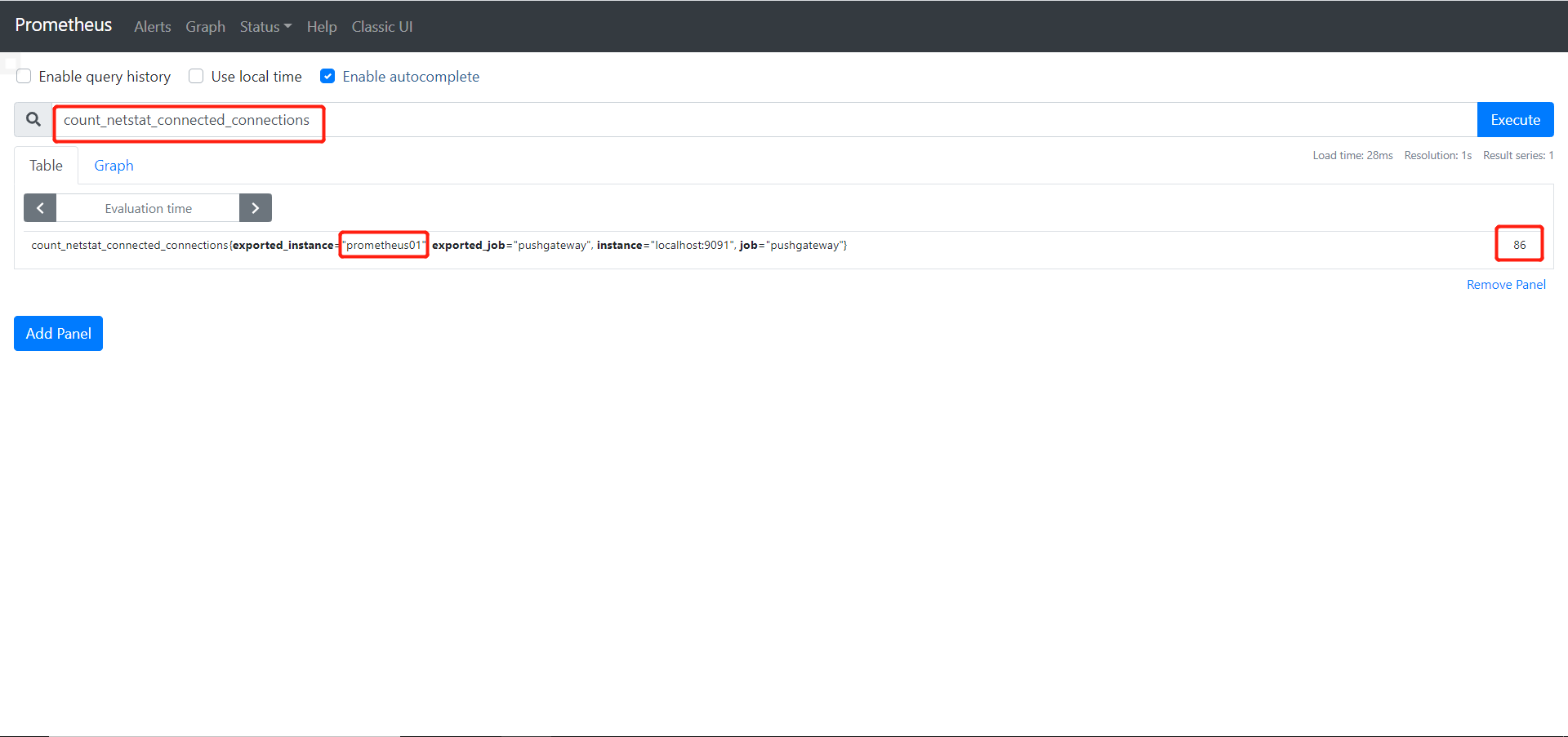
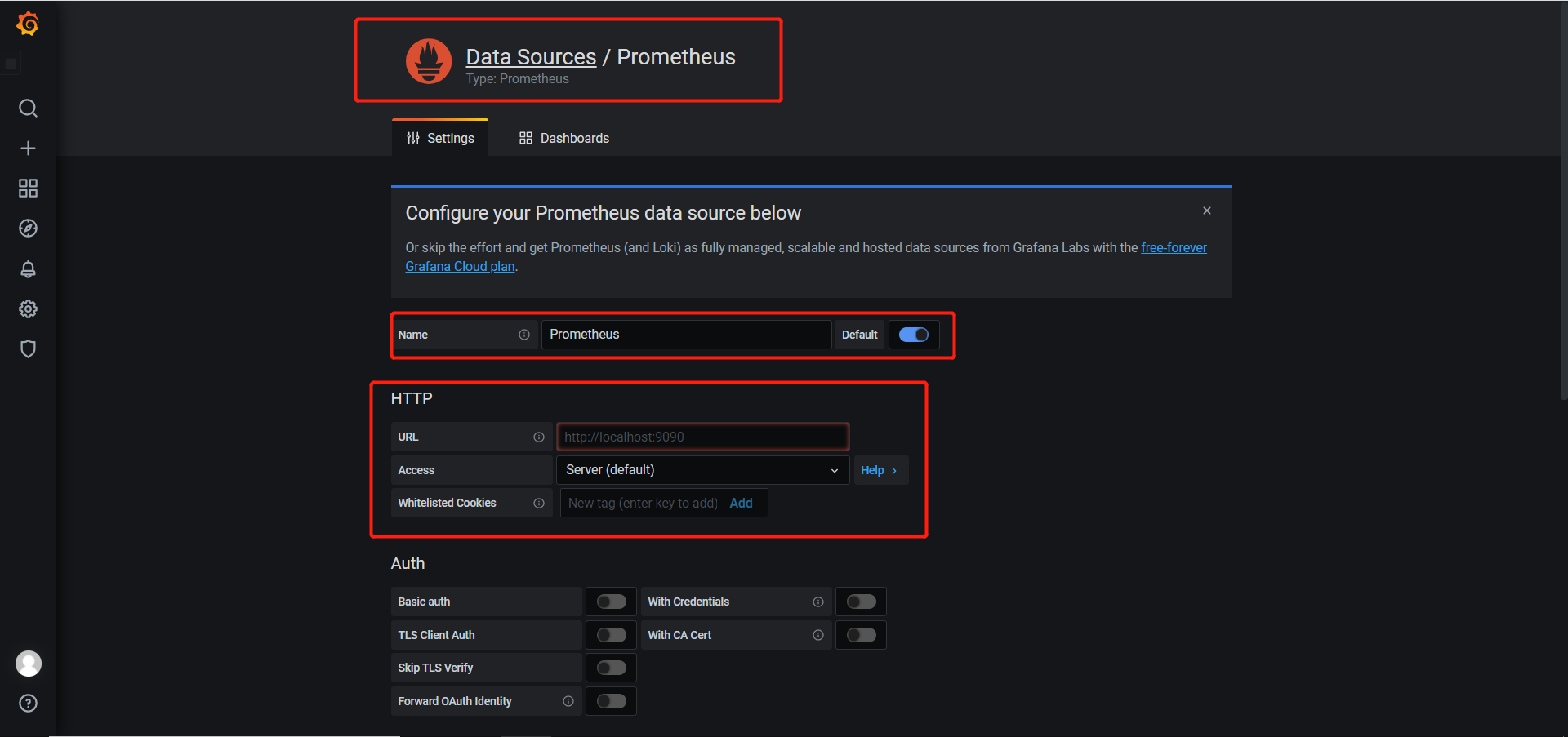
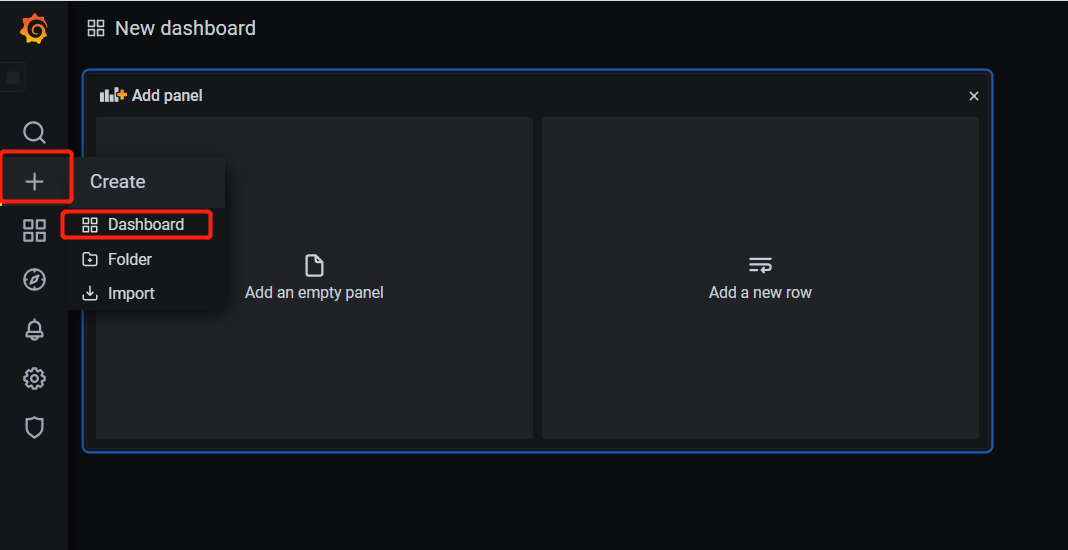
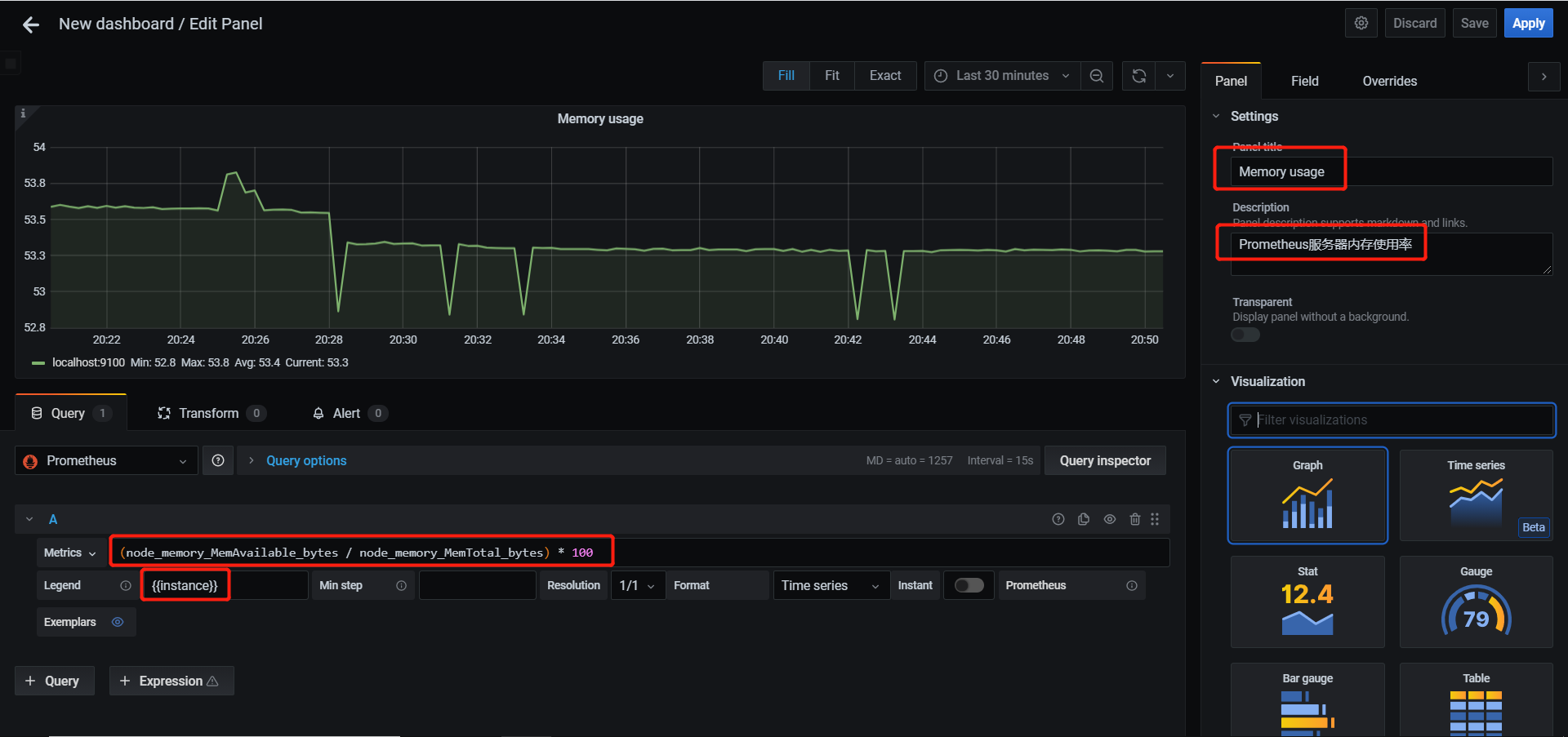
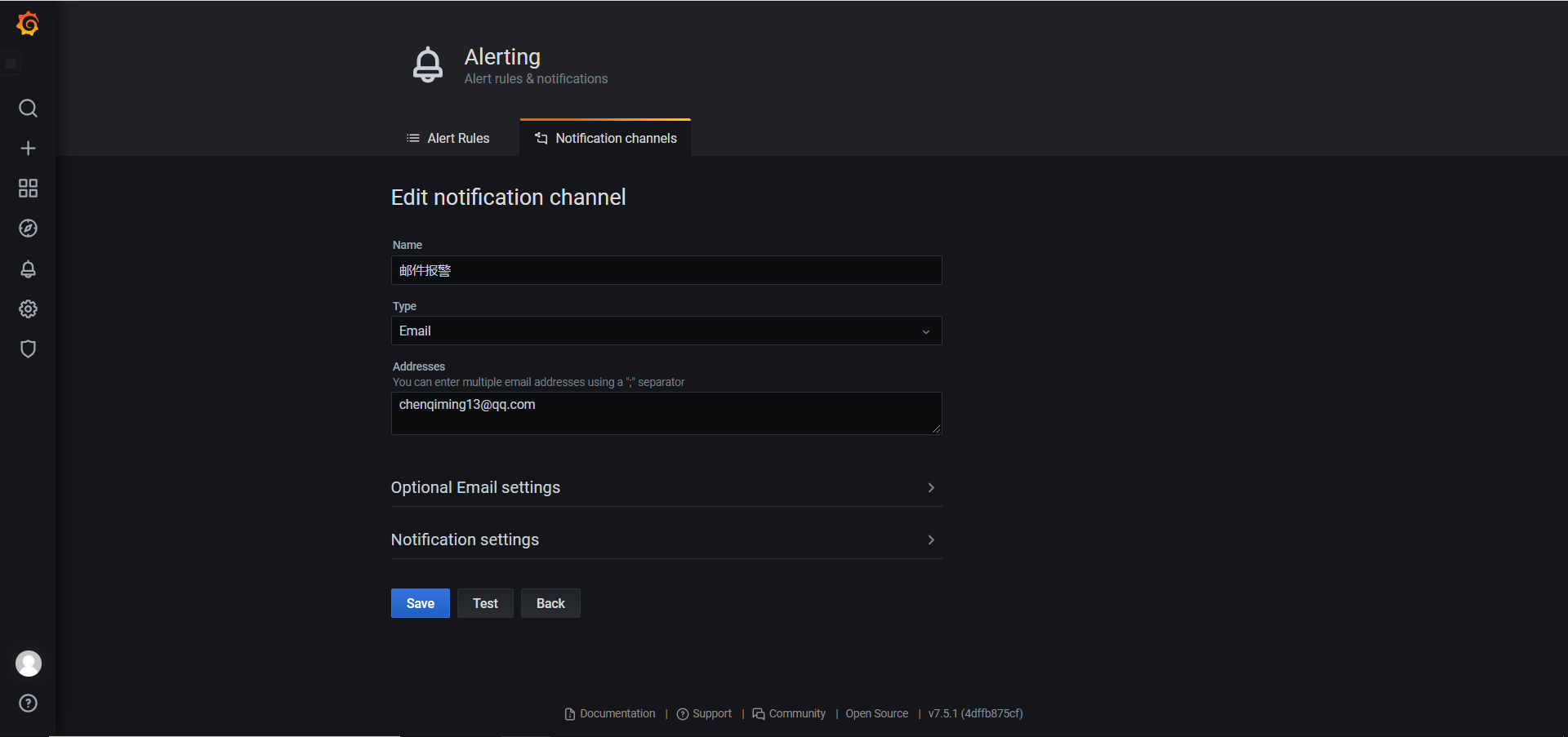
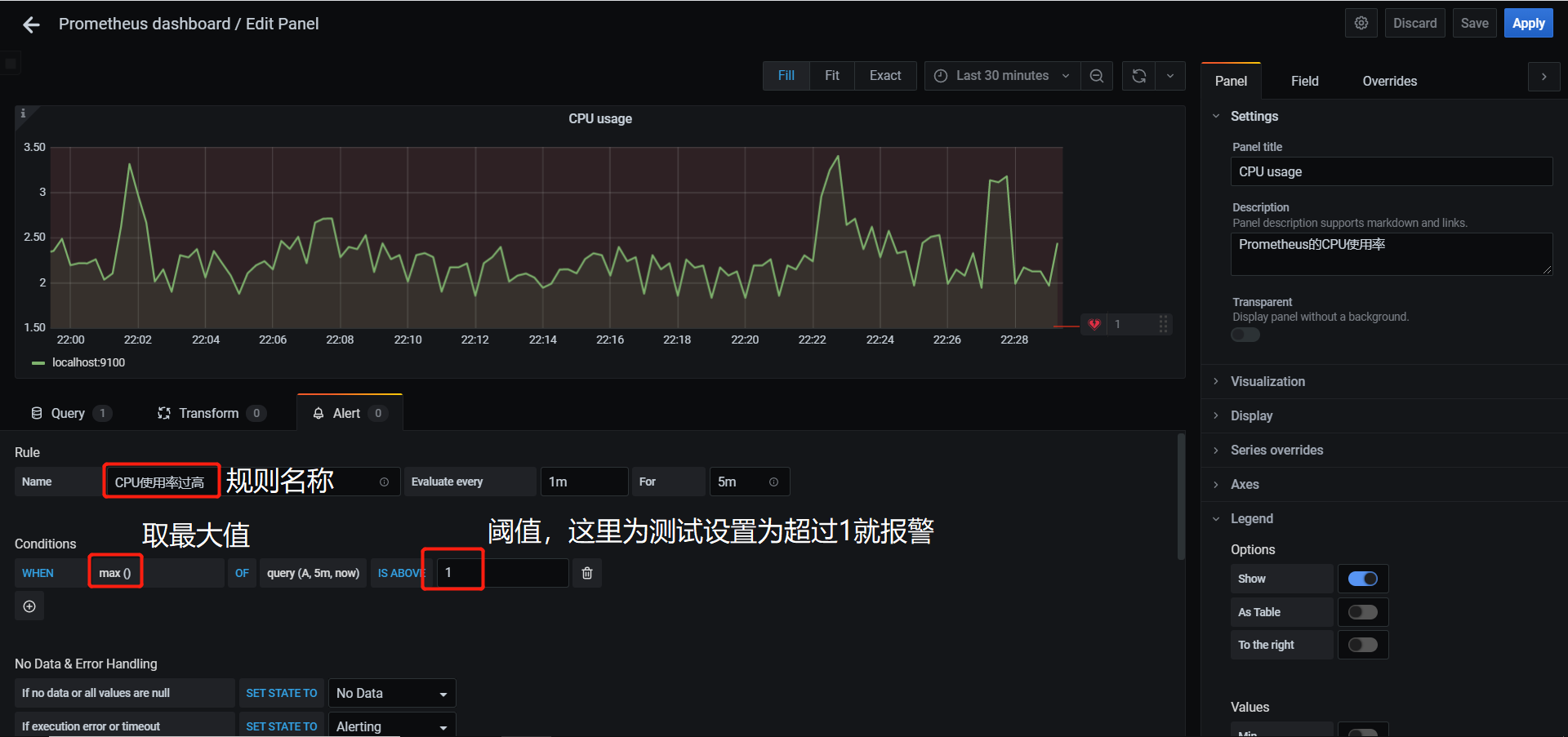
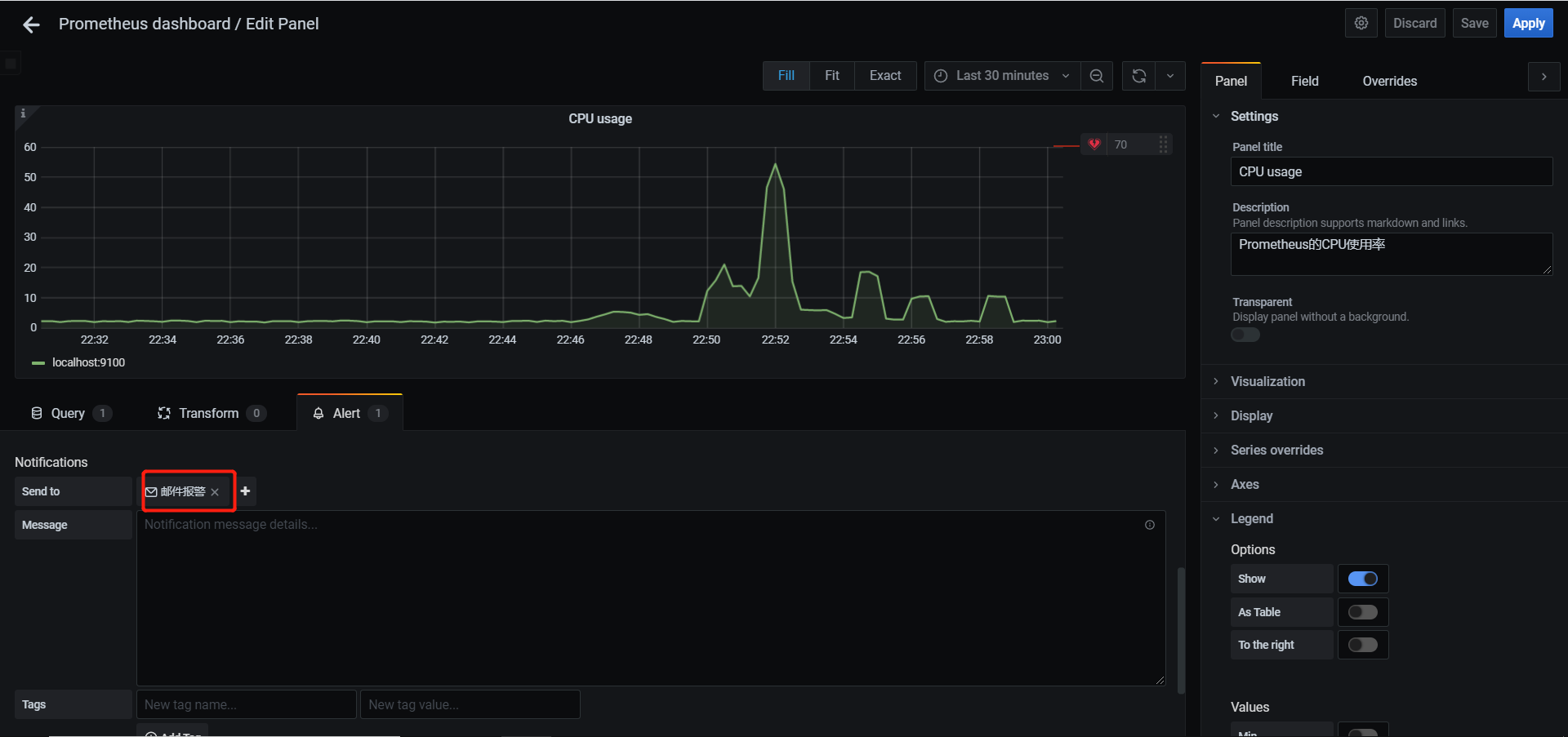
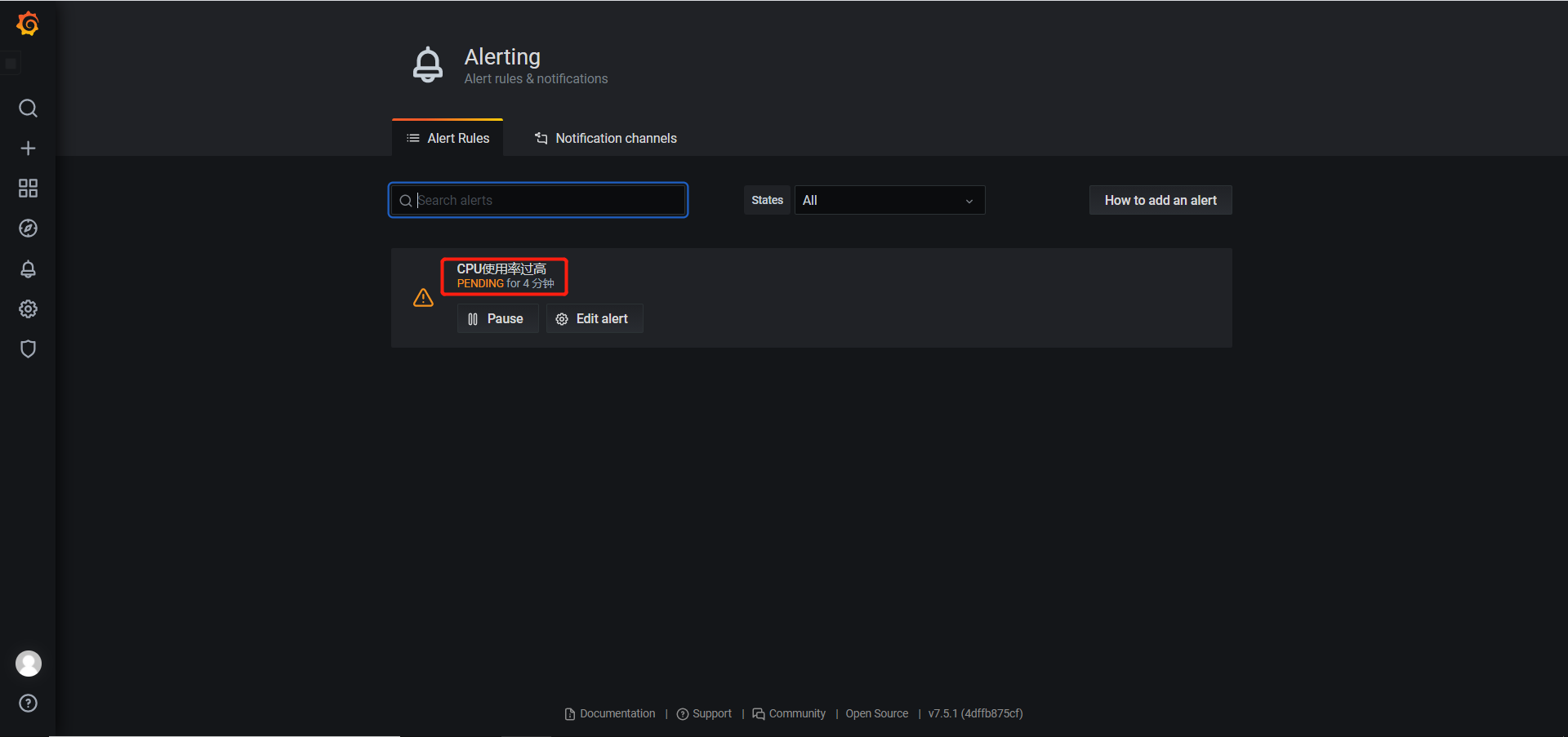
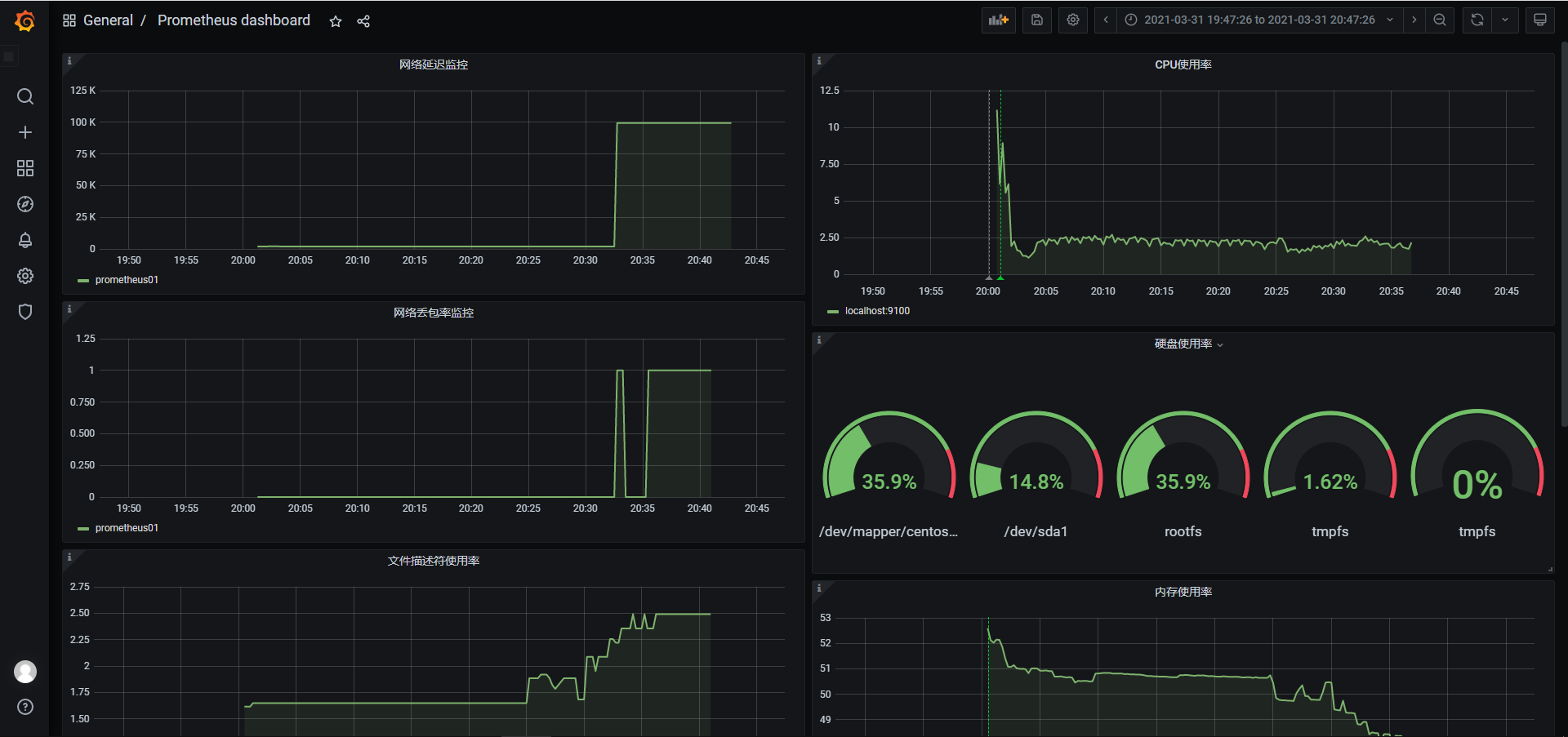
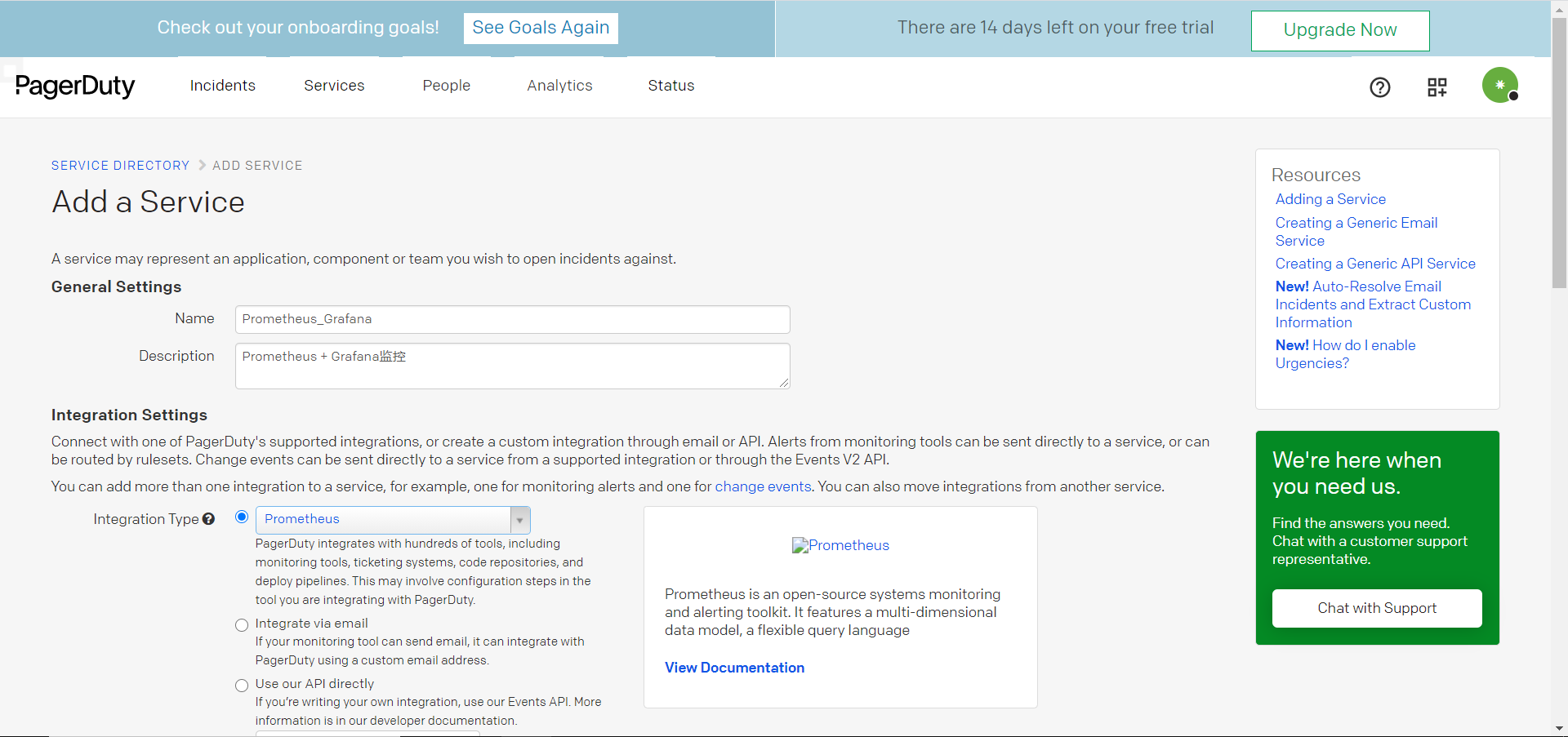
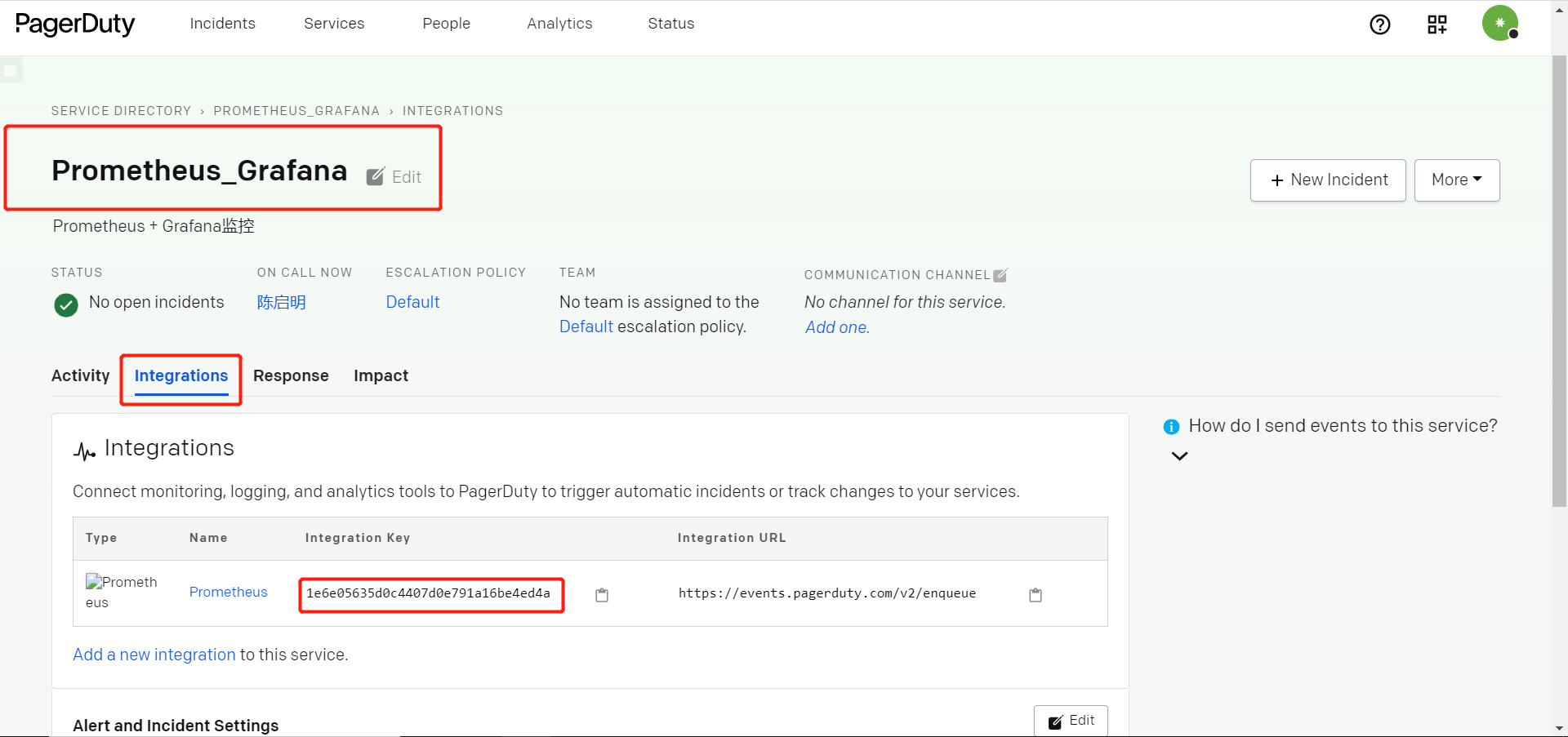
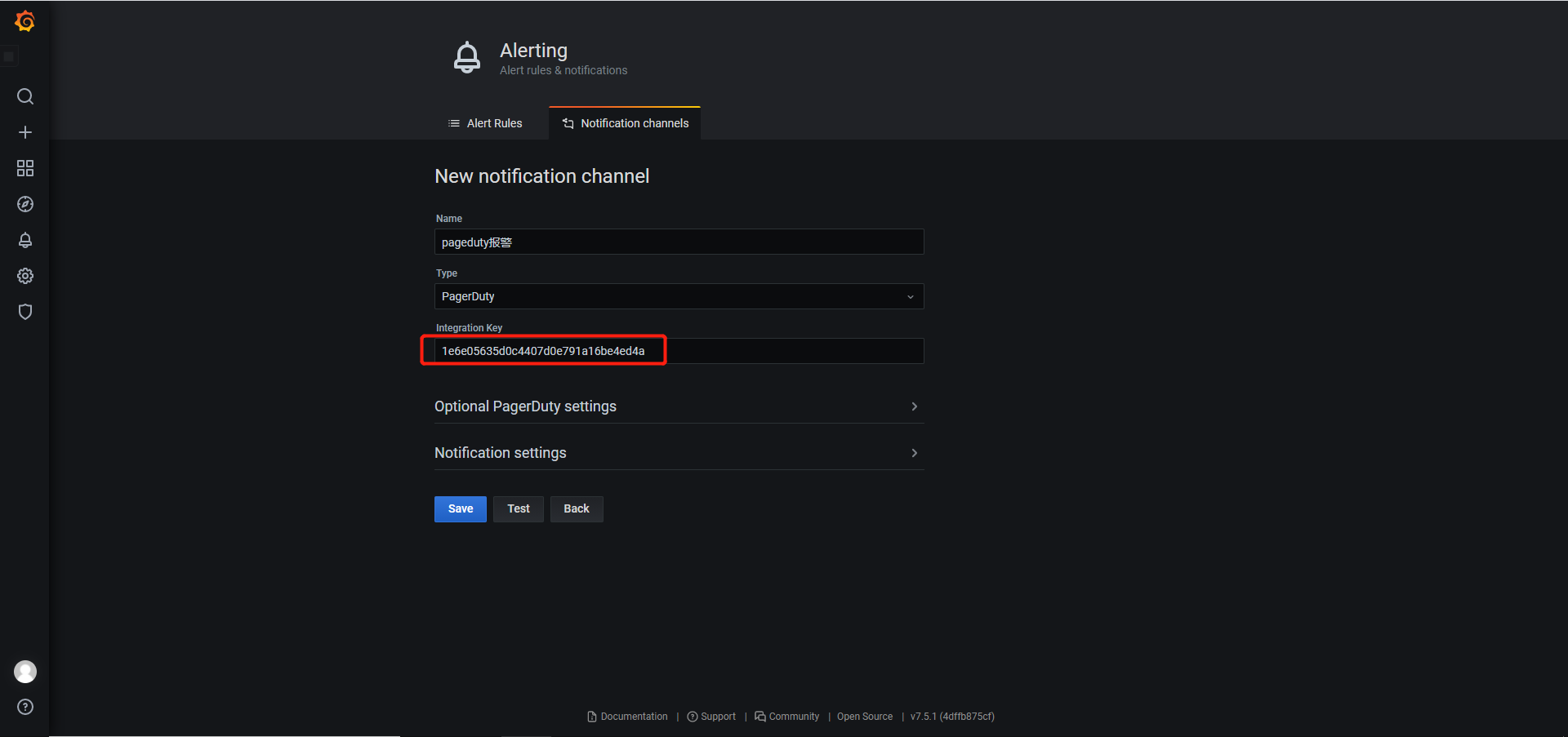
一、Apache 1.1 Apache介绍 Apache HTTP Server(简称Apache)是Apache软件基金会的一个开放源码的网页服务器,是世界使用排名第一的Web服务器软件。它可以运行在几乎所有广泛使用的计算机平台上,由于其跨平台和安全性被广泛使用,是最流行的Web服务器端软件之一。它快速、可靠并且可通过简单的API扩充,将Perl/Python等解释器编译到服务器中。
Apache HTTP服务器是一个模块化的服务器,源于NCSAhttpd服务器,经过多次修改,成为世界使用排名第一的Web服务器软件。
Apache官方文档:http://httpd.apache.org/docs/
1.2 通过脚本源码安装Apache
编写安装脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 useradd -s /sbin/nologin -r www vim apache-install.sh # !/bin/bash apr_version=1.7.0 apr_iconv_version=1.2.2 apr_util_version=1.6.1 apache_version=2.4.46 # 检查 function check() { # 检查是否为root用户 if [ $USER != 'root' ] then echo -e "\e[1;31m error:need to be root so that \e[0m" exit 1 fi # 检查是否安装了wget if [ `rpm -qa | grep wget | wc -l` -lt 1 ] then echo -e "\e[1;31m error:not found wget \e[0m" exit 1 fi } # 安装前准备 function install_pre() { # 安装依赖 if [ ! `yum -y install zlib-devel pcre-devel libxml2 expat-devel &> /dev/null` ] then echo -e "\e[1;31m error:yum install dependency package failed \e[0m" exit 1 fi # 下载apr cd /usr/local if [ ! `wget https://downloads.apache.org/apr/apr-${apr_version}.tar.bz2 &> /dev/null` ] then tar -xf apr-${apr_version}.tar.bz2 if [ ! -d apr-${apr_version} ] then echo -e "\e[1;31m error:not found apr-${apr_version} \e[0m" exit 1 else cd apr-${apr_version} fi else echo -e "\e[1;31m error:Failed to download apr-${apr_version}.tar.bz2 \e[0m" exit 1 fi # 安装apr echo "apr configure..." ./configure --prefix=/usr/local/apr &> /dev/null if [ `echo $?` -eq 0 ] then echo "apr make && make install..." make && make install &> /dev/null if [ `echo $?` -eq 0 ] then echo -e "\e[1;32m apr installed successfully \e[0m" else echo -e "\e[1;31m apr installed failed \e[0m" exit 1 fi else echo -e "\e[1;31m error:apr configure failed \e[0m" exit 1 fi # 下载apr-iconv cd /usr/local if [ ! `wget https://www.apache.org/dist/apr/apr-iconv-${apr_iconv_version}.tar.bz2 &> /dev/null` ] then tar -xf apr-iconv-${apr_iconv_version}.tar.bz2 if [ ! -d apr-iconv-${apr_iconv_version} ] then echo -e "\e[1;31m error:not found apr-iconv-${apr_iconv_version} \e[0m" exit 1 else cd apr-iconv-${apr_iconv_version} fi else echo -e "\e[1;31m error:Failed to download apr-iconv-${apr_iconv_version}.tar.bz2 \e[0m" exit 1 fi # 安装apr-iconv echo "apr-iconv configure..." ./configure --prefix=/usr/local/apr-iconv --with-apr=/usr/local/apr &> /dev/null if [ `echo $?` -eq 0 ] then echo "apr-iconv make && make install..." make && make install &> /dev/null if [ `echo $?` -eq 0 ] then echo -e "\e[1;32m apr-iconv installed successfully \e[0m" else echo -e "\e[1;31m apr-iconv installed failed \e[0m" exit 1 fi else echo -e "\e[1;31m error:apr-iconv configure failed \e[0m" exit 1 fi # 下载apr-util cd /usr/local if [ ! `wget https://www.apache.org/dist/apr/apr-util-${apr_util_version}.tar.bz2 &> /dev/null` ] then tar -xf apr-util-${apr_util_version}.tar.bz2 if [ ! -d apr-util-${apr_util_version} ] then echo -e "\e[1;31m error:not found apr-util-${apr_util_version} \e[0m" exit 1 else cd apr-util-${apr_util_version} fi else echo -e "\e[1;31m error:Failed to download apr-util-${apr_util_version}.tar.bz2 \e[0m" exit 1 fi # 安装apr-util echo "apr-util configure..." ./configure --prefix=/usr/local/apr-util --with-apr=/usr/local/apr/ &> /dev/null if [ `echo $?` -eq 0 ] then echo "apr-util make && make install..." make && make install &> /dev/null if [ `echo $?` -eq 0 ] then echo -e "\e[1;32m apr-util installed successfully \e[0m" else echo -e "\e[1;31m apr-util installed failed \e[0m" exit 1 fi else echo -e "\e[1;31m error:apr-util configure failed \e[0m" exit 1 fi } # 下载安装Apache function apache_install() { # 下载Apache cd /usr/local if [ ! `wget https://downloads.apache.org/httpd/httpd-${apache_version}.tar.gz &> /dev/null` ] then tar -xf httpd-${apache_version}.tar.gz if [ ! -d httpd-${apache_version} ] then echo -e "\e[1;31m error:not found httpd-${apache_version} \e[0m" exit 1 else cd httpd-${apache_version} fi else echo -e "\e[1;31m error:Failed to download httpd-${apache_version} \e[0m" exit 1 fi # 安装Apache echo "Apache configure..." ./configure --prefix=/usr/local/apache --enable-mpms-shared=all --with-mpm=event --with-apr=/usr/local/apr --with-apr-util=/usr/local/apr-util --enable-so --enable-remoteip --enable-proxy --enable-proxy-fcgi --enable-proxy-uwsgi --enable-deflate=shared --enable-expires=shared --enable-rewrite=shared --enable-cache --enable-file-cache --enable-mem-cache --enable-disk-cache --enable-static-support --enable-static-ab --disable-userdir --enable-nonportable-atomics --disable-ipv6 --with-sendfile &> /dev/null if [ `echo $?` -eq 0 ] then echo "Apache make && make install..." make && make install &> /dev/null if [ `echo $?` -eq 0 ] then echo -e "\e[1;32m Apache installed sucessfully \e[0m" else echo -e "\e[1;31m Apache installed failed \e[0m" exit 1 fi else echo -e "\e[1;31m Apache configure failed \e[0m" exit 1 fi } check install_pre apache_install
编写启动脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 # !/bin/bash apache_doc=/usr/local/apache/bin apache_pid=/usr/local/apache/logs/httpd.pid function apache_start() { apache_num=`ps -ef | grep httpd | wc -l` if [ $apache_num -gt 1 ] && [ -f $apache_pid ] then echo -e "Apache [\e[1;32m running \e[0m]" exit 1 elif [ $apache_num -eq 1 ] && [ -f $apache_pid ] then killall httpd fi cd /usr/local/apache/bin;./apachectl echo -e "start Apache [\e[1;32m OK \e[0m]" } function apache_stop() { apache_num=`ps -ef | grep httpd | wc -l` if [ $apache_num -eq 1 ] then echo -e "Apache [\e[1;31m stopping \e[0m]" else killall httpd echo -e "stop Apache [\e[1;32m OK \e[0m]" fi } function apache_restart() { cd /usr/local/apache/bin;./apachectl restart echo -e "restart Apache [\e[1;32m OK \e[0m]" } function apache_status() { apache_num=`ps -ef | grep httpd | wc -l` if [ $apache_num -gt 1 ] && [ -f $nginx_pid ] then echo -e "Apache [\e[1;32m running \e[0m]" else echo -e "Apache [\e[1;31m stopping \e[0m]" fi } function apache_reload() { apache_num=`ps -ef | grep httpd | wc -l` if [ $apache_num -gt 1 ] && [ -f $nginx_pid ] then cd /usr/local/apache/bin;./apachectl graceful echo -e "reload Apache [\e[1;32m OK \e[0m]" else echo -e "Apache [\e[1;31m stopping \e[0m]" fi } case $1 in start) apache_start ;; stop) apache_stop ;; restart) apache_restart ;; status) apache_status ;; reload) apache_reload esac
1.3 多处理模块MPM Apache HTTP 服务器被设计为一个功能强大,并且灵活的 web 服务器, 可以在很多平台与环境中工作。不同平台和不同的环境往往需要不同 的特性,或可能以不同的方式实现相同的特性最有效率。Apache 通过模块化的设计来适应各种环境。这种设计允许网站管理员通过在 编译时或运行时,选择哪些模块将会加载在服务器中,来选择服务器特性。
实际上就是用来接受请求 和处理请求 的。
Apache的三种工作方式:
Prefork MPM:使用多个进程,每个进程只有一个线程,每个进程再某个确定的时间只能维持一个连接,有点是稳定,缺点是内存消耗过高。

Worker MPM:使用多个进程,每个进程有多个线程,每个线程在某个确定的时间只能维持一个连接,内存占用比较小,是个大并发、高流量的场景,缺点是一个线程崩溃,整个进程就会连同其任何线程一起挂掉。

Event MPM:使用多进程多线程+epoll的模式。

1.4 虚拟主机 默认情况下,一个web服务器只能发布一个默认网站,也就是只能发布一个web站点,对于大网站来说还好,但对于访问量较少的小网站那就显得有点浪费了。
而虚拟主机就可以实现在一个web服务器上发布多个站点,分为基于IP地址、域名和端口三种。
Apache的虚拟主机和默认网站不能够同时存在,如果设置了虚拟主机那么默认网站也就失效了,需要在用虚拟主机发布默认站点才可解决。
基于IP:基于IP的虚拟主机需要耗费大量的IP地址,只适合IP地址充足的环境。
基于端口:需要耗费较多的端口,适合私网环境。
基于域名:需要耗费较多的域名,适合公网环境。
1.4.1 基于IP的虚拟主机
在主配文件中调用虚拟主机文件
1 2 3 vim /usr/local/apache/conf/httpd.conf # Virtual hosts Include conf/extra/httpd-vhosts.conf
修改虚拟主机文件
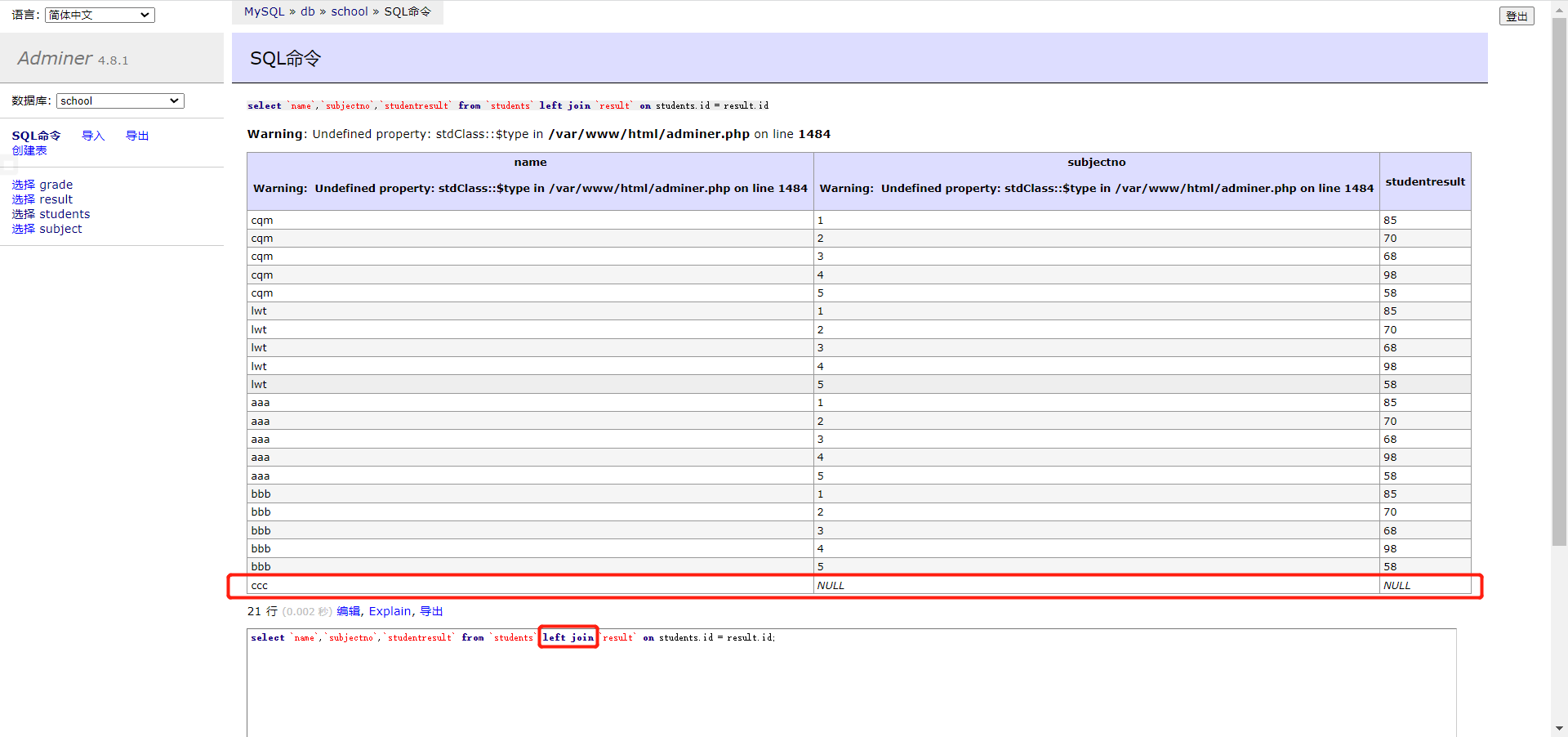
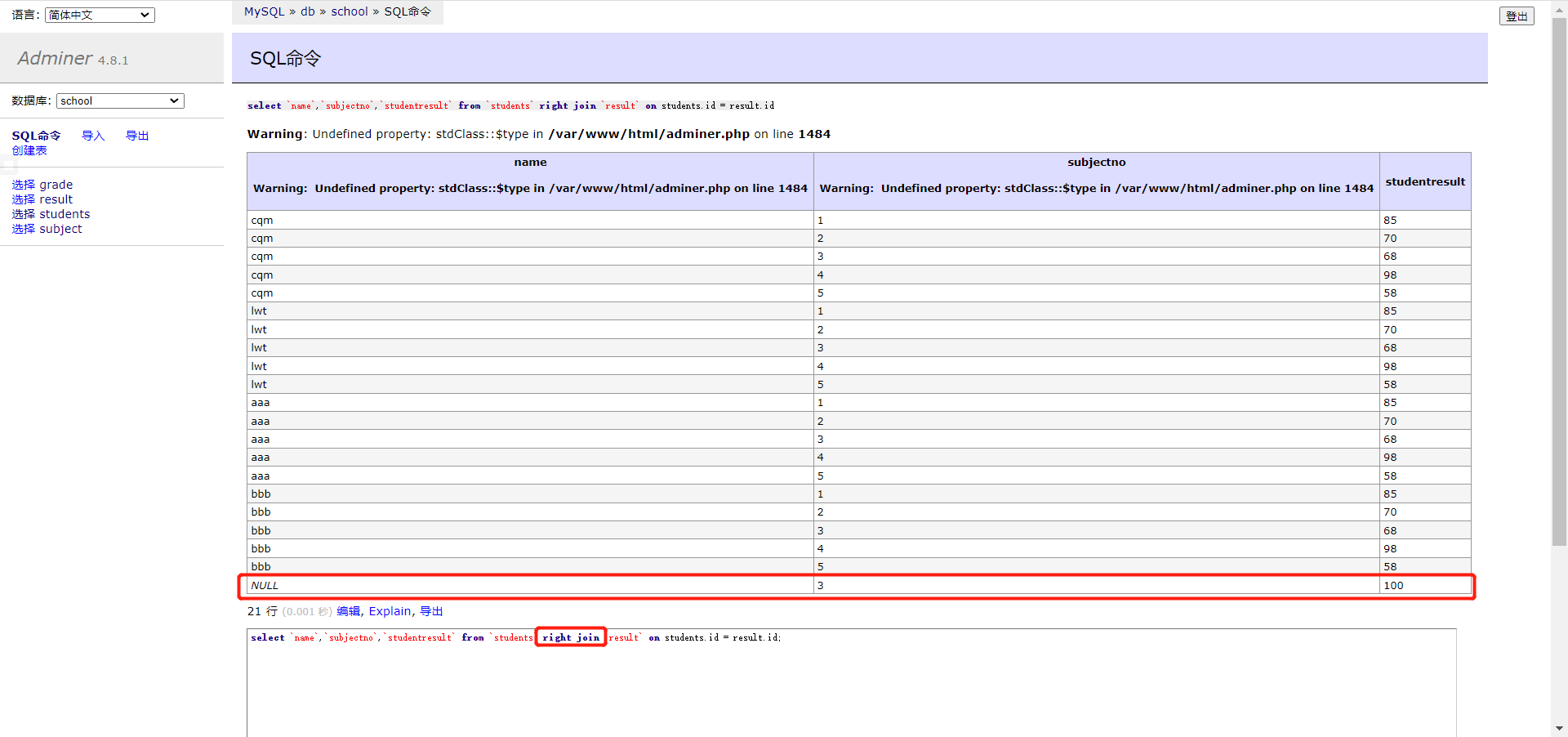
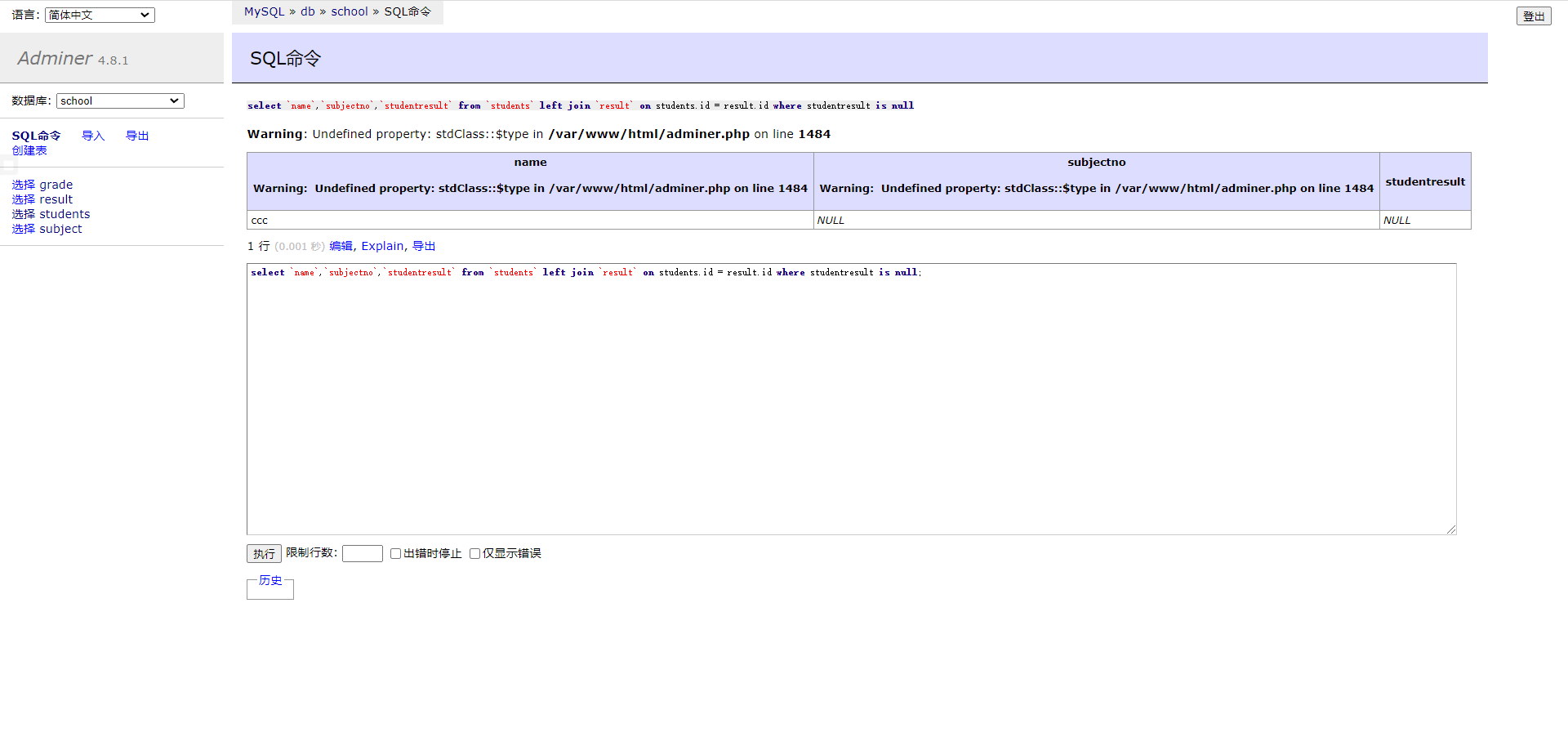
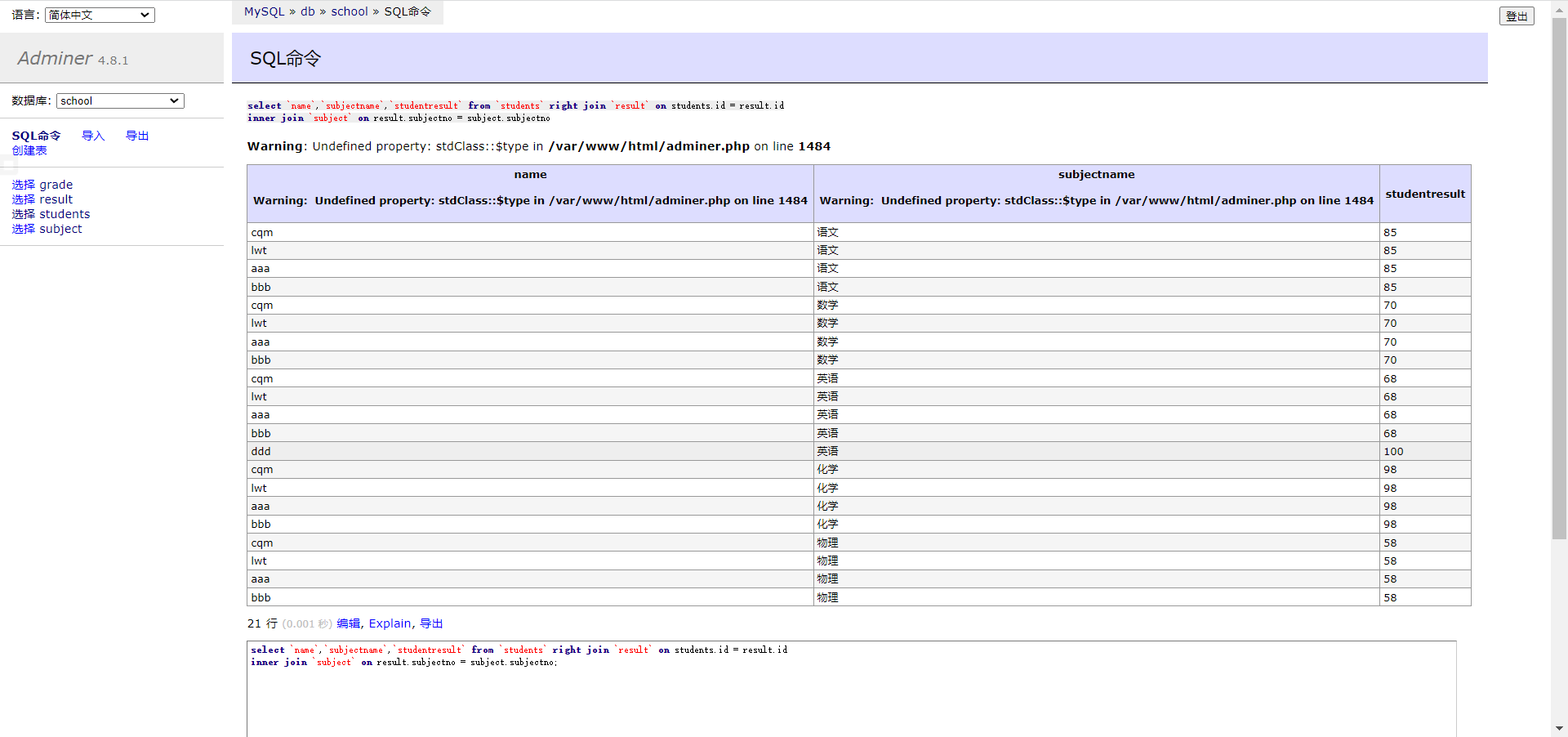
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 # 添加一个逻辑网卡,重启即失效 ifconfig eth0:1 192.168.88.100/24 up vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost 49.232.160.75:80> # 管理员邮箱 # ServerAdmin webmaster@dummy-host.example.com # web目录 DocumentRoot "/usr/local/apache/htdocs/web1" # 域名 # ServerName dummy-host.example.com # 给域名起别名,起到重定向作用 # ServerAlias www.dummy-host.example.com # 错误日子 # ErrorLog "logs/dummy-host.example.com-error_log" # 访问日志 # CustomLog "logs/dummy-host.example.com-access_log" common </VirtualHost> <VirtualHost 192.168.88.100:80> DocumentRoot "/usr/local/apache/htdocs/web2" </VirtualHost>
创建站点目录和文件
1 2 3 4 mkdir /usr/local/apache/htdocs/web{1..2} echo 'this is web1' > /usr/local/apache/htdocs/web1/index.html echo 'this is web2' > /usr/local/apache/htdocs/web2/index.html ./apache start
测试
1.4.2 基于端口的虚拟主机
修改虚拟主机文件
1 2 3 4 5 6 7 8 <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web1" </VirtualHost> Listen 81 <VirtualHost *:81> DocumentRoot "/usr/local/apache/htdocs/web2" </VirtualHost>
测试
1.4.3 基于域名的虚拟主机
修改虚拟主机文件
1 2 3 4 5 6 7 8 9 <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web1" ServerName www.cqm1.com </VirtualHost> <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web2" ServerName www.cqm2.com </VirtualHost>
测试
1.5 LAMP LAMP:Linux + Apache + Mysql + PHP
作用就是构建一个PHP业务环境,用来发布PHP网站。
1.5.1 Mysql通过脚本源码安装
编写安装脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 # !/bin/bash mysql_version=5.7.35 install_dir=/opt data_dir=/data wget_url="https://mirrors.tuna.tsinghua.edu.cn/mysql/downloads/MySQL-5.7/mysql-${mysql_version}-linux-glibc2.12-x86_64.tar.gz" function loginfo(){ if [[ $? -eq 0 ]];then echo -e "\033[32m[INFO][$(date +"%F %T")] $1 succeed! \033[0m" else echo -e "\033[31m[ERROR][$(date +"%F %T")] $1 failed! \033[0m" fi } function mysql_install(){ echo -e "\033[32mBegin install mysql V${mysql_version} ...\033[0m" # 安装依赖 sudo yum -y install libaio >/dev/null 2>&1 loginfo "libaio install" # 下载mysql echo -e "\033[32mBegin download mysql V${mysql_version} ...\033[0m" curl -O $wget_url >/dev/null 2>&1 mv ./mysql-${mysql_version}-linux-glibc2.12-x86_64.tar.gz $install_dir loginfo "mysql software download" # 解压缩mysql sudo tar -xf $install_dir/mysql-${mysql_version}-linux-glibc2.12-x86_64.tar.gz -C $install_dir loginfo "mysql software decompression" # 创建配置文件目录和数据目录 if [[ -d $install_dir/mysql ]];then rm -rf $install_dir/mysql fi sudo ln -s $install_dir/mysql-${mysql_version}-linux-glibc2.12-x86_64 $install_dir/mysql loginfo "create mysql config dir soft link" if [[ -d $data_dir/mysql ]];then rm -rf $data_dir/mysql fi sudo mkdir -p $data_dir/mysql loginfo "create mysql data dir" # 修改启动脚本 sudo sed -i "46s#basedir=#basedir=${install_dir}/mysql#" ${install_dir}/mysql/support-files/mysql.server sudo sed -i "47s#datadir=#datadir=${data_dir}/mysql#" ${install_dir}/mysql/support-files/mysql.server sudo cp ${install_dir}/mysql/support-files/mysql.server /etc/init.d/mysqld sudo chmod 755 /etc/init.d/mysqld # 创建用户组及用户 if ! grep -q '^mysql:' /etc/group then sudo groupadd mysql loginfo "create user mysql" fi if ! grep -q '^mysql:' /etc/passwd then sudo useradd -r -g mysql -s /bin/false mysql loginfo "create group mysql" fi # 授权 sudo chown -R mysql:mysql $install_dir/mysql sudo chown -R mysql:mysql $data_dir/mysql # 为二进制文件创建软连接 if [ ! -f /usr/bin/mysql ] then sudo ln -s /opt/mysql/bin/mysql /usr/bin/ fi # 创建配置文件 if [ -f /etc/my.cnf ] then sudo rm -f /etc/my.cnf fi sudo bash -c "cat >> /etc/my.cnf" <<EOF [mysqld] datadir = /data/mysql basedir = /opt/mysql # tmpdir = /data/mysql/tmp_mysql port = 3306 socket = /data/mysql/mysql.sock pid-file = /data/mysql/mysql.pid max_connections = 8000 max_connect_errors = 100000 max_user_connections = 3000 check_proxy_users = on mysql_native_password_proxy_users = on local_infile = OFF symbolic-links = FALSE group_concat_max_len = 4294967295 max_join_size = 18446744073709551615 max_execution_time = 20000 lock_wait_timeout = 60 autocommit = 1 lower_case_table_names = 1 thread_cache_size = 64 disabled_storage_engines = "MyISAM,FEDERATED" character_set_server = utf8mb4 character-set-client-handshake = FALSE collation_server = utf8mb4_general_ci init_connect = 'SET NAMES utf8mb4' transaction-isolation = "READ-COMMITTED" skip_name_resolve = ON explicit_defaults_for_timestamp = ON log_timestamps = SYSTEM local_infile = OFF event_scheduler = OFF query_cache_type = OFF query_cache_size = 0 sql_mode = NO_ENGINE_SUBSTITUTION,STRICT_TRANS_TABLES,NO_AUTO_CREATE_USER,NO_ZERO_DATE,NO_ZERO_IN_DATE,ERROR_FOR_DIVISION_BY_ZERO log_error = /data/mysql/mysql.err slow_query_log = ON slow_query_log_file = /data/mysql/slow.log long_query_time = 1 general_log = OFF general_log_file = /data/mysql/general.log expire_logs_days = 99 log-bin = /data/mysql/mysql-bin log-bin-index = /data/mysql/mysql-bin.index max_binlog_size = 500M binlog_format = mixed binlog_rows_query_log_events = ON binlog_cache_size = 128k binlog_stmt_cache_size = 128k log-bin-trust-function-creators = 1 max_binlog_cache_size = 2G max_binlog_stmt_cache_size = 2G relay_log = /data/mysql/relay relay_log_index = /data/mysql/relay.index max_relay_log_size = 500M relay_log_purge = ON relay_log_recovery = ON server_id = 1 read_buffer_size = 1M read_rnd_buffer_size = 2M sort_buffer_size = 64M join_buffer_size = 64M tmp_table_size = 64M max_allowed_packet = 128M max_heap_table_size = 64M connect_timeout = 43200 wait_timeout = 43200 back_log = 512 interactive_timeout = 300 net_read_timeout = 30 net_write_timeout = 30 skip_external_locking = ON key_buffer_size = 16M bulk_insert_buffer_size = 16M concurrent_insert = ALWAYS open_files_limit = 65000 table_open_cache = 16000 table_definition_cache = 16000 default_storage_engine = InnoDB default_tmp_storage_engine = InnoDB internal_tmp_disk_storage_engine = InnoDB [client] socket = /data/mysql/mysql.sock default_character_set = utf8mb4 [mysql] default_character_set = utf8mb4 [ndatad default] TransactionDeadLockDetectionTimeOut = 20000 EOF sudo chown -R mysql:mysql /etc/my.cnf loginfo "configure my.cnf" # 创建SSL证书 # sudo mkdir -p ${install_dir}/mysql/ca-pem/ # sudo ${install_dir}/mysql/bin/mysql_ssl_rsa_setup -d ${install_dir}/mysql/ca-pem/ --uid=mysql # sudo chown -R mysql:mysql ${install_dir}/mysql/ca-pem/ # sudo bash -c "cat >> ${data_dir}/mysql/init_file.sql" <<EOF # set global sql_safe_updates=0;# set global sql_select_limit=50000;# EOF # sudo chown -R mysql:mysql ${data_dir}/mysql/init_file.sql # sudo chown -R mysql:mysql /etc/init.d/mysqld # 初始化 ${install_dir}/mysql/bin/mysqld --initialize --user=mysql --basedir=${DEPLOY_PATH}/mysql --datadir=/data/mysql loginfo "initialize mysql" # 客户端环境变量 echo "export PATH=\$PATH:${install_dir}/mysql/bin" | sudo tee /etc/profile.d/mysql.sh source /etc/profile.d/mysql.sh loginfo "configure envirement" # 获取初始密码 mysql_init_passwd=$(grep 'A temporary password is generated' ${data_dir}/mysql/mysql.err | awk '{print $NF}') # 启动服务 chkconfig --add mysqld sudo systemctl start mysqld loginfo "start mysqld" # 修改密码 mysql --connect-expired-password -uroot -p${mysql_init_passwd} -e 'alter user user() identified by "toortoor";' >/dev/null 2>&1 loginfo "edit mysql root password" } mysql_install
1.5.2 PHP通过脚本源码安装
编写安装脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 # !/bin/bash cmake_version=3.22.0 libzip_version=1.8.0 php_version=7.4.16 # 检查 function check() { # 检查是否为root用户 if [ $USER != "root" ] then echo -e "\e[1;31m error:need to be root so that \e[0m" exit 1 fi # 检查是否安装了wget if [ `rpm -qa | grep wget | wc -l` -lt 1 ] then echo -e "\e[1;31m error:not found wget \e[0m" exit 1 fi } # 安装前准备 function pre() { # 安装依赖包 if [ ! `yum -y install gcc-c++ libxml2 libxml2-devel openssl openssl-devel bzip2 bzip2-devel libcurl libcurl-devel libjpeg libjpeg-devel libpng libpng-devel freetype freetype-devel gmp gmp-devel libmcrypt libmcrypt-devel readline readline-devel libxslt libxslt-devel gd net-snmp-* sqlite-devel oniguruma-devel &> /dev/null` ] then echo -e "\e[1;31m error:yum install dependency package failed \e[0m" exit 1 fi # 下载最新版cmake cd /usr/local if [ ! `wget https://github.com/Kitware/CMake/releases/download/v${cmake_version}/cmake-${cmake_version}.tar.gz &> /dev/null` ] then tar -xf cmake-${cmake_version}.tar.gz if [ ! -d cmake-${cmake_version} ] then echo -e "\e[1;31m error:no found cmake-${cmake_version} \e[0m" exit 1 else cd cmake-${cmake_version} fi else echo -e "\e[1;31m error:Failed to download cmake-${cmake_version} \e[0m" exit 1 fi # 安装cmake echo "cmake configure..." ./configure &> /dev/null if [ `echo $?` -eq 0 ] then echo "cmake make && make install..." make && make install &> /dev/null if [ `echo $?` -eq 0 ] then echo -e "\e[1;32m cmake installed sucessfully \e[0m" else echo -e "\e[1;31m cmake installed failed \e[0m" exit 1 fi else echo -e "\e[1;31m error:cmake configure failed \e[0m" exit 1 fi # 下载libzip1.1以上版本 cd /usr/local if [ ! `wget --no-check-certificate https://libzip.org/download/libzip-${libzip_version}.tar.gz &> /dev/null` ] then echo "tar libzip..." tar -xf libzip-${libzip_version}.tar.gz if [ ! -d libzip-${libzip_version} ] then echo -e "\e[1;31m error:not found libzip-${libzip_version} \e[0m" exit 1 else cd libzip-${libzip_version} fi else echo -e "\e[1;31m error:Failed to download libzip-${libzip_version}.tar.gz \e[0m" exit 1 fi # 安装libzip mkdir build;cd build echo "cmake libzip..." cmake .. &> /dev/null if [ `echo $?` -eq 0 ] then echo "make && make install libzip..." make && make install &> /dev/null if [ `echo $?` -eq 0 ] then echo -e "\e[1;32m libzip install sucessfully \e[0m" echo -e '/usr/local/lib64\n/usr/local/lib\n/usr/lib\n/usr/lib64'>> /etc/ld.so.conf ldconfig -v &> /dev/null else echo -e "\e[1;31m error:libzip install failed \e[0m" exit 1 fi else echo -e "\e[1;31m error:lipzip cmake failed \e[0m" exit 1 fi } function php_install() { # 下载php cd /usr/local if [ ! `wget https://www.php.net/distributions/php-${php_version}.tar.bz2 &> /dev/null` ] then echo "tar php..." tar -xf php-${php_version}.tar.bz2 if [ ! -d php-${php_version} ] then echo -e "\e[1;31m error:not found php-${php_version} \e[0m" exit 1 else cd php-${php_version} fi else echo -e "\e[1;31m error:Failed to download php-${php_version}.tar.bz2 \e[0m" exit 1 fi # 安装php echo "configure php..." # 要php以apache模块运行需加上--with-apxs2=/usr/localapache/bin/apxs参数 ./configure --prefix=/usr/local/php --with-config-file-path=/usr/local/php/etc --with-mysqli=mysqlnd --enable-pdo --with-pdo-mysql=mysqlnd --with-iconv-dir=/usr/local/ --enable-fpm --with-fpm-user=www --with-fpm-group=www --with-pcre-regex --with-zlib --with-bz2 --enable-calendar --disable-phar --with-curl --enable-dba --with-libxml-dir --enable-ftp --with-gd --with-jpeg-dir --with-png-dir --with-zlib-dir --with-freetype-dir --enable-gd-jis-conv --with-mhash --enable-mbstring --enable-opcache=yes --enable-pcntl --enable-xml --disable-rpath --enable-shmop --enable-sockets --enable-zip --enable-bcmath --with-snmp --disable-ipv6 --with-gettext --disable-rpath --disable-debug --enable-embedded-mysqli --with-mysql-sock=/var/lib/mysql/ &> /dev/null if [ `echo $?` -eq 0 ] then echo "make && make install php..." make && make install &> /dev/null if [ `echo $?` -eq 0 ] then echo -e "\e[1;32m php install sucessfully \e[0m" else echo -e "\e[1;31m php install failed \e[0m" exit 1 fi else echo -e "\e[1;31m configure php failed \e[0m" exit 1 fi } function php_set() { if [ ! -f /usr/local/php-${php_version}/sapi/fpm/php-fpm.service ] then echo -e "\e[1;31m No found php-fpm.service \e[0m" exit 1 else cp /usr/local/php-${php_version}/sapi/fpm/php-fpm.service /etc/systemd/system if [ `echo $?` -ne 0 ] then echo -e "\e[1;31m Copy php-fpm.service failed \e[0m" exit 1 else sed -i '/PrivateTmp=true/a\ProtectSystem=false' /etc/systemd/system/php-fpm.service systemctl daemon-reload echo -e "\e[1;32m php set sucessfully \e[0m" fi fi } check pre php_install php_set
配置PHP
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 cd /usr/local/php/etc cp php-fpm.conf.default php-fpm.conf cp php-fpm.d/www.conf.default php-fpm.d/www.conf egrep -v '^;|^$' php-fpm.conf [global] pid = run/php-fpm.pid error_log = log/php-fpm.log daemonize = yes include=/usr/local/php/etc/php-fpm.d/*.conf egrep -v '^;|^$' php-fpm.d/www.conf [www] user = www group = www listen = 127.0.0.1:9000 listen.owner = www listen.group = www listen.mode = 0660 pm = dynamic pm.max_children = 5 pm.start_servers = 2 pm.min_spare_servers = 1 pm.max_spare_servers = 3
启动
1.5.3 PHP作为Apache模块运行
在apache主配置文件中调用子配置文件
1 2 vim /usr/local/apache/conf/httpd.conf include conf/extra/php.conf
配置子配置文件
1 2 3 vim /usr/local/apache/conf/extra/php.con LoadModule php7_module modules/libphp7.so AddType application/x-httpd-php .php
配置虚拟主机
1 2 3 4 vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web" </VirtualHost>
写web目录
1 2 3 4 5 echo 'this is cqm web' > /usr/local/apache/htdocs/web/index.html vim /usr/local/apache/htdocs/web/phpinfo.php <?php phpinfo() ?>
测试
1.5.4 PHP作为独立服务运行 PHP作为独立服务运行有两种模式:
TCP socket模式
UNIX socket模式
TCP socket模式
修改www.conf文件
1 2 vim /usr/local/php/etc/php-fpm.d/www.conf listen = 127.0.0.1:9000
配置虚拟主机文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web" </VirtualHost> <Directory "/usr/local/apache/htdocs/web"> Options Indexes FollowSymLinks AllowOverride None Require all granted </Directory> <IfModule dir_module> DirectoryIndex index.php index.html </IfModule> <FilesMatch \.php$> SetHandler "proxy:fcgi://127.0.0.1:9000" </FilesMatch>
在apache主配文件添加关联
1 2 vim /usr/local/apache/conf/httpd.conf include conf/extra/php-fpm.conf
配置子配文件
1 2 3 4 vim /usr/local/apache/conf/php-fpm.conf # 载入需要的模块 LoadModule proxy_module modules/mod_proxy.so LoadModule proxy_fcgi_module modules/mod_proxy_fcgi.so
UNIX socket模式
修改www.conf文件
1 2 vim /usr/local/php/etc/php-fpm.d/www.conf listen = /usr/local/php/etc/php-fpm.socket
配置虚拟主机
1 2 3 <FilesMatch \.php$> SetHandler "proxy:unix:/usr/local/php/etc/php-fpm.socket|fcgi://localhost/" </FilesMatch>
1.6 Apache常用模块 1.6.1 长连接 HTTP采用TCP进行传输,是面向连接的协议,每完成一次请求就要经历以下过程:
那么N个请求就要建立N次连接,如果希望用户能够更快的拿到数据,服务器的压力降到最低,那么靠长连接就可以解决。
长连接实际上就是优化了TCP连接。
Apache默认开启了长连接,持续时间为5秒,在httpd-default.conf中可以定义。
1 2 3 4 5 6 7 vim /usr/local/apache/conf/extra/httpd-default.conf # 开启长连接 KeepAlive On # 限制每个连接允许的请求数 MaxKeepAliveRequests 500 # 长连接时间 KeepAliveTimeout 5
1.6.2 静态缓存 用户每次访问网站都会将页面中的所有元素都请求一遍,全部下载后通过浏览器渲染,展示到浏览器中。但是,网站中的某些元素我们一般都是固定不变的,比如logo、框架文件等。用户每次访问都需要加载这些元素。这样做好处是保证了数据的新鲜,可是这些数据不是常变化的,很久才变化一次。每次都请求、下载浪费了用户时间和公司带宽。
所以我们通过静态缓存的方式,将这些不常变化的数据缓存到用户本地磁盘,用户以后再访问这些请求,直接从本地磁盘打开加载,这样的好处是加载速度快,且节约公司带宽及成本。
在apache主配文件中加载缓存模块
1 2 vim /usr/local/apache/conf/httpd.conf LoadModule expires_module modules/mod_expires.so
修改虚拟主机文件调用模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web" <IfMoudle expires_module> #开启缓存 ExpiresActive on #针对不同类型元素设置缓存时间 ExpiresByType image/gif "access plus 1 days" ExpiresByType image/jpeg "access plus 24 hours" ExpiresByType image/png "access plus 24 hours" #now 相当于 access ExpiresByType text/css "now plus 2 hour" ExpiresByType application/x-javascript "now plus 2 hours" ExpiresByType application/x-shockwave-flash "now plus 2 hours” #其他数据不缓存 ExpiresDefault "now plus 0 min" </IfModule> </VirtualHost>
1.6.3 数据压缩 数据从服务器传输到客户端,需要传输时间,文件越大传输时间就越长,为了减少传输时间,我们一般把数据压缩后在传给客户端。
apache支持两种模式的压缩:
两者的区别:
mod_deflate 压缩速度快。
mod_gzip 的压缩比略高。
一般情况下,mod_gzip 会比 mod_deflate 多出 4%~6% 的压缩量。
mod_gzip 对服务器CPU的占用要高一些,所以 mod_deflate 是专门为确保服务器的性能而使用的一个压缩模块,只需较少的资源来进行压缩。
在apache主配文件中加载压缩模块
1 2 vim /usr/local/apache/conf/httpd.conf LoadModule deflate_module modules/mod_deflate.so
修改虚拟主机文件调用模块
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web" <IfMoudle deflate_module> #压缩等级1-9,数字越大压缩能力越好,相应地也越耗CPU性能 DeflateCompressionLevel 4 #压缩类型,html、xml、php、css、js AddOutputFilterByType DEFLATE text/html text/plain text/xml application/x-javascript application/x-httpd-php AddOutputFilter DEFLATE js css # 浏览器匹配为IE1-6的不压缩 BrowserMatch \bMSIE\s[1-6] dont-vary # 设置不压缩的文件 SetEnvIfNoCase Request_URI .(?:gif|jpe?g|png)$ no-gzip dont-vary SetEnvIfNoCase Request_URI .(?:exe|t?gz|zip|bz2|sit|rar)$ no-gzip dont-vary SetEnvIfNoCase Request_URI .(?:pdf|doc)$ no-gzip dont-vary </IfModule> </VirtualHost>
1.6.4 限速 网站除了能共享页面给用户外,还能作为下载服务器存在。但是作为下载服务器时,我们应该考虑服务器的带宽和IO的性能,防止部分邪恶分子会通过大量下载的方式来攻击你的带宽和服务器IO性能。
问题:
假如你的服务器被邪恶分子通过下载的方式把带宽占满了,那么你或其他用户在访问的时候就会造成访问慢或者根本无法访问。
假如你的服务器被邪恶分子通过下载的方式把服务器IO占满了,那么你的服务器将会无法处理用户请求或宕机。
以上问题可以通过限速来解决,apache自带了基于宽带限速的模块:
ratelimit_module:只能对连接下载速度做限制,且是单线程的下载,迅雷等下载工具使用的是多线程下载。
mod_limitipconn:限制每 IP 的连接数,需要额外安装该模块。
ratelimit_module模块
在apache主配文件中加载压缩模块
1 2 vim /usr/local/apache/conf/httpd.conf LoadModule ratelimit_module modules/mod_ratelimit.so
修改虚拟主机文件调用模块
1 2 3 4 5 6 7 8 9 10 11 12 vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web" </VirtualHost> # Location相对路径:/usr/local/apache/htdocs/... # Directory绝对路径:... <Location /download> SetOutputFiler RATE_LIMIT # 限速100k SetEnv rate-limit 100 </Location>
mod_limitipconn模块
下载安装模块
1 2 3 4 5 6 wget http://dominia.org/djao/limit/mod_limitipconn-0.24.tar.bz2 tar -xf mod_limitipconn-0.24.tar.bz2 cd mod_limitipconn-0.24 vim Makefile apxs = "/usr/local/apache/bin/apxs" make && make install
在apache主配文件启用模块
1 2 vim /usr/local/apache/conf/httpd.conf LoadModule limitipconn_module modules/mod_limitipconn.so
修改虚拟主机文件调用模块
1 2 3 4 5 6 7 8 9 <Location /download> SetOutputFiler RATE_LIMIT # 限速100k SetEnv rate-limit 100 # 限制线程数 MaxConnPerIP 3 # 对index.html文件不作限制 NoIPLimit index.html </Location>
1.6.5 访问控制 在生产环境中,网站分为公站和私站,公站允许所有人访问,但私站就只允许内部人员访问,Require就可以实现访问控制的功能。
容器:
RequireAny:一个符合即可通过
RequireAll:所有符合才可通过
Requirenone:所有都不符合才可通过
普通的访问控制
修改虚拟主机文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web" </VirtualHost> <Directory "/usr/local/apache/htdocs/web/test"> AllowOverride None # 拒绝所有人访问 Require all denied # 允许该地址段的用户访问 Require ip 192.168.88 # 允许该主机访问 Require host www.cqm.com </Directory>
用户登录验证访问控制
修改虚拟主机文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web" </VirtualHost> <Directory "/usr/local/apache/htdocs/web/test"> # 定义提示信息,用户访问时提示信息会出现在认证的对话框中 AuthName "Private" # 定义认证类型,在HTTP1.0中,只有一种认证类型:basic。在HTTP1.1中有几种认证类型,如:MD5 AuthType Basic # 定义包含用户名和密码的文本文件,每行一对 AuthUserFile "/usr/local/apache/user.dbm" # 配合容器使用,只有条件全部符合才能通过 <RequireAll> Require not ip 192.168.88 # require user user1 user2 (只有用户user1和user2可以访问) # requires groups group1 (只有group1中的成员可以访问) # require valid-user (在AuthUserFile指定的文件中的所有用户都可以访问) Require valid-user </RequireAll> </Directory>
生成用户文件
1 2 3 # 生成cqm用户 /usr/local/apache/bin/htpasswd -cm /usr/local/apache/user.dbm cqm ...
1.6.6 URL重写 Apache通过mod_rewrite模块可以实现URL重写的功能,URL重写其实就是改写用户浏览器中的URL地址。
在主配文件开启模块
1 2 vim /usr/local/apache/conf/httpd.conf LoadModule rewrite_module modules/mod_rewrite.so
修改虚拟主机文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web" # 开启URL重写功能 RewriteEngine on # 重写规则,跳转到百度 RewriteRule "^/$" "http://www.baidu.com" [NC,L] # 匹配条件,根据请求头进行匹配 RewriteCond "%{HTTP_USER_AGENT}" "chrome" [NC,OR] RewriteCond "%{HTTP_USER_AGENT}" "curl" # 重写规则,和匹配到的条件配合使用,请求头匹配到chrome或curl则返回403状态码 RewriteRule "^/$" - [F] </VirtualHost> RewreteRule [flag] 部分标记规则 R:强制外部重定向 F:禁用URL,返回403HTTP状态码 G:强制URL为GONE,返回410HTTP状态码 P:强制使用代理转发 L:表明当前规则是最后一条规则,停止分析以后规则的重写 N:重新从第一条规则开始运行重写过程 C:与下一条规则关联 NS:只用于不是内部子请求 NC:不区分大小写
通过URL重写实现分流功能
1 2 3 4 5 6 7 8 9 vim /usr/local/apache/conf/extra/httpd-vhosts.conf <VirtualHost *:80> DocumentRoot "/usr/local/apache/htdocs/web" RewriteEngine on RewriteCond "%{HTTP_USER_AGENT}" "(chrome|curl)" [NC,OR] RewriteRule "^/$" "http://pc.cqm.com" [NC] RewriteCond "%{HTTP_USER_AGENT}" "(iPhone|Blackberry|Android|ipad)" [NC] RewriteRule "^/$" "http://phone.cqm.com" [NC] </VirtualHost>
1.6.7 压力测试 Apache压力测试使用ab命令
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 ab -A:指定连接服务器的基本的认证凭据 -c:指定一次向服务器发出请求数 -C:添加cookie -g:将测试结果输出为“gnuolot”文件 -h:显示帮助信息 -H:为请求追加一个额外的头 -i:使用“head”请求方式 -k:激活HTTP中的“keepAlive”特性 -n:指定测试会话使用的请求数 -p:指定包含数据的文件 -q:不显示进度百分比 -T:使用POST数据时,设置内容类型头 -v:设置详细模式等级 -w:以HTML表格方式打印结果 -x:以表格方式输出时,设置表格的属性 -X:使用指定的代理服务器发送请求 -y:以表格方式输出时,设置表格属性
1 2 3 /usr/local/apache/bin/ab -n 10000 -c 200 http:... # 并发数 per second...
二、Nginx 2.1 Nginx介绍 Nginx是一款是由俄罗斯的程序设计师Igor Sysoev所开发高性能的 Web和 反向代理服务器,也是一个 IMAP/POP3/SMTP 代理服务器。和apache一样,都是web服务器软件,因为其性能优异,所以被广大运维喜欢。又因为nginx是一个轻量级的web服务器,相比apache来说资源消耗更低。
Nginx中文文档:https://www.nginx.cn/doc/index.html
2.2 通过脚本源码安装Nginx
编写安装脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 vim nginx-install.sh # !/bin/bash nginx_version=1.21.3 # 检测 function check() { # 检测是否为root if [ $USER != "root" ] then echo -e "\e[1;31m error:need to be root so that \e[0m" exit 1 fi # 检测wget是否安装 if [ ! -e /usr/bin/wget ] then echo -e "\e[1;31m error:not found command /usr/bin/wget \e[0m" exit 1 fi } # 安装前准备 function install_pre() { # 安装依赖 # 0:stdin标准输入 1:stdout标准输出 2:stderr错误输出 if [ ! `yum -y install gcc-* pcre-devel zlib-devel &> /dev/null` ] then echo -e "\e[1;31m error:yum install dependency package failed \e[0m" exit 1 fi # 下载源码包 cd /usr/local/ if [ ! `wget http://nginx.org/download/nginx-${nginx_version}.tar.gz &> /dev/null` ] then tar -xf nginx-${nginx_version}.tar.gz if [ ! -d nginx-${nginx_version} ] then echo -e "\e[1;31m error:not found nginx-${nginx_version} \e[0m" exit 1 fi else echo -e "\e[1;31m error:wget file nginx-${nginx_version}.tar.gz failed \e[0m" exit 1 fi } # 安装 function install_nginx() { cd /usr/local/nginx-${nginx_version} echo "nginx configure..." ./configure --prefix=/usr/local/nginx &> /dev/null if [ `echo $?` -eq 0 ] then echo "nginx make..." make && make install &> /dev/null if [ `echo $?` -eq 0 ] then echo -e "\e[1;32m nginx install success \e[0m" else echo -e "\e[1;31m error:nginx install fail \e[0m" exit 1 fi else echo -e "\e[1;31m error:nginx configure fail \e[0m" exit 1 fi } check install_pre install_nginx
编写启动脚本
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 # !/bin/bash # Source function libiary if [ -f /etc/init.d/functions ] then . /etc/init.d/functions else echo "Not found file /etc/init.d/functions" exit fi nginxd=/usr/local/nginx/sbin/nginx nginx_pid=/usr/local/nginx/logs/nginx.pid function nginx_start() { nginx_num=`ps -ef | grep nginx | wc -l` if [ $nginx_num -gt 1 ] && [ -f $nginx_pid ] then echo -e "nginx [\e[1;32m running \e[0m]" exit 1 elif [ $nginx_num -eq 1 ] && [ -f $nginx_pid ] then killall nginx fi $ nginxd } function nginx_stop() { nginx_num=`ps -ef | grep nginx | wc -l` if [ $nginx_num -eq 1 ] then echo -e "nginx [\e[1;31m stopping \e[0m]" exit 1 elif [ $nginx_num -gt 1 ] then killall nginx fi } function nginx_status() { nginx_num=`ps -ef | grep nginx | wc -l` if [ $nginx_num -gt 1 ] && [ -f $nginx_pid ] then echo -e "nginx [\e[1;32m running \e[0m]" else echo -e "nginx [\e[1;31m stopping \e[0m]" fi } function nginx_restart() { nginx_stop nginx_start } function nginx_reload() { nginx_num=`ps -ef | grep nginx | wc -l` if [ $nginx_num -gt 1 ] && [ -f $nginx_pid ] then $nginxd -s reload else echo -e "nginx [\e[1;31m stopping \e[0m]" fi } case $1 in start) nginx_start echo -e "nginx start [\e[1;32m OK \e[0m]" ;; stop) nginx_stop echo -e "nginx stop [\e[1;32m OK \e[0m]" ;; status) nginx_status ;; restart) nginx_restart echo -e "nginx restart [\e[1;32m OK \e[0m]" ;; reload) nginx_reload echo -e "nginx reload [\e[1;32m OK \e[0m]" esac
2.3 Nginx的Server块 当Nginx配置文件只有一个Server块时,那么该Server块就被Nginx认为是默认网站,所有发给Nginx的请求都会传给该Server块。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 server { # 监听80端口 listen 80; # 域名 server_name localhost; # 字符集 charset koi8-r; # 访问日志路径 access_log logs/host.access.log main; # web根路径 # /代表相对路劲,这里代表/usr/local/nginx location / { # 根目录路径,这里代表/usr/local/nginx/html root html; # 索引页 index index.html index.htm; } # 404状态码 error_page 404 /404.html; location = /404.html{ root html; } # 50x状态码 error_page 500 502 503 504 /50x.html; location = /50x.html { root html; }
2.4 Nginx的访问控制
编写主配文件
1 2 3 4 5 6 7 8 9 10 11 12 13 location / { root html; index index.html index.htm; # 允许192.168.88.0/24的用户访问 allow 192.168.88.0/24; # 拒绝所有 deny all; # 基于客户端IP做过滤,符合条件的允许访问,不符合的返回404 # 这里为不是192.168.88的就返回404 if ( $remote_addr !~ "192.168.88" ){ return 404; } }
2.5 Nginx的用户验证
编写主配文件
1 2 3 4 5 6 7 8 location / { root html; index index.html index.htm; # 欢迎词 auth_basic "welcome to cqm's web"; # 存放用户文件 auth_basic_user_file /usr/local/nginx/htpasswd; }
生成用户文件
1 /usr/local/apache/bin/htpasswd -cm /usr/local/nginx/htpasswd cqm
2.6 Nginx参数 1 2 3 4 5 6 7 8 9 10 11 # nginx中的log_format可以用来自定义日志格式 # log_format变量: $ remote_addr:记录访问网站的客户端地址 $ remote_user:远程客户端用户名 $ time_local:记录访问时间与时区 $ request:用户的http请求起始行信息 $ status:http状态码,记录请求返回的状态码,例如:200、301、404等 $ body_bytes_sent:服务器发送给客户端的响应body字节数 $ http_referer:记录此次请求是从哪个连接访问过来的,可以根据该参数进行防盗链设置。 $ http_user_agent:记录客户端访问信息,例如:浏览器、手机客户端等 $ http_x_forwarded_for:当前端有代理服务器时,设置web节点记录客户端地址的配置,此参数生效的前提是代理服务器也要进行相关的x_forwarded_for设置
2.7 Nginx防盗链 盗链用大白话讲就是抓取别人网站的资源,加以利用,以至于被抓取资源的网站消耗了带宽,而收益的是抓取资源的人。
而反盗链就可以防止别人抓取自身网站的资源。
编写主配文件
1 2 3 4 5 6 7 location / { # 除了www.cqm.com之外,都返回403 valid_referers none blocked www.cqm.com; if ($invalid_referer){ return 403; } }
2.8 Nginx虚拟主机 Nginx的虚拟主机是通过server块来实现的。
2.8.1 基于IP的虚拟主机
修改主配文件
1 2 vim /usr/local/nginx/conf/nginx.conf include /usr/local/nginx/conf/conf.d/nginx_vhosts.conf;
修改虚拟主机文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vim /usr/local/nginx/conf/conf.d/nginx_vhosts.conf server { listen 192.168.88.100; location / { root html/web1; index index.html index.htm index.php; } } server { listen 192.168.88.101; location / { root html/web2; index index.html index.htm index.php; } }
其它配置
1 2 3 4 5 # 添加一个逻辑网卡,重启即失效 ifconfig eth0:1 192.168.88.100/24 up mkdir /usr/local/nginx/html/web{1..2} echo 'this is web1' > /usr/local/nginx/html/web1/index.html echo 'this is web2' > /usr/local/nginx/html/web2/index.html
测试
1 2 3 4 curl http://192.168.88.100/ this is web1 curl http://192.168.88.101/ this is web2
2.8.2 基于端口的虚拟主机
修改虚拟主机文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 vim /usr/local/nginx/conf/conf.d/nginx_vhosts.conf server { listen 80; location / { root html/web1; index index.html index.htm index.php; } } server { listen 81; location / { root html/web2; index index.html index.htm index.php; } }
2.8.3 基于域名的虚拟主机 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 vim /usr/local/nginx/conf/conf.d/nginx_vhosts.conf server { listen 80; server_name www.cqm1.com; location / { root html/web1; index index.html index.htm index.php; } } server { listen 80; server_name www.cqm2.com; location / { root html/web2; index index.html index.htm index.php; } }
2.9 Nginx反向代理 代理最常见的使用方式就是翻墙,能够实现让国内的用户访问国外的网站。
原理:
用户讲请求发给代理服务器
代理服务器代替用户去获取数据
代理服务器将数据发送给用户
正常没有代理的上网
使用代理服务器的上网
=
代理服务器又分为两种:正向代理、反向代理
正向代理:代理用户向服务器获取资源
反向代理:代理服务器去管理网络资源,用户有请求找反向代理就可以了
编写反向代理服务器主配文件
1 2 3 4 5 6 vim /usr/local/nginx/conf/nginx.conf location / { index index.html index.htm index.php; # 访问代理服务器就会跳转到http://192.168.88.100 proxy_pass http://192.168.88.100; }
反向代理其它配置
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 proxy_set_header Host $host; proxy_set_header X-Real-IP $remote_addr; proxy_set_header X-Forwarded-For $proxy_add_x_forwarded_for; client_max_body_size 10m; #允许客户端请求的最大单文件字节数 client_body_buffer_size 128k; #缓冲区代理缓冲用户端请求的最大字节数, proxy_connect_timeout 90; #nginx跟后端服务器连接超时时间(代理连接超时) proxy_send_timeout 90; #后端服务器数据回传时间(代理发送超时) proxy_read_timeout 90; #连接成功后,后端服务器响应时间(代理接收超时) proxy_buffer_size 4k; #设置代理服务器(nginx)保存用户头信息的缓冲区大小 proxy_buffers 4 32k; #proxy_buffers缓冲区,网页平均在32k以下的话,这样设置 proxy_busy_buffers_size 64k; #高负荷下缓冲大小(proxy_buffers*2) proxy_temp_file_write_size 64k; #设定缓存文件夹大小,大于这个值,将从upstream服务器传
2.10 Nginx下载限速 限速方法主要分为:
下载速度限制
单位时间内请求数限制
基于客户端的并发数限制
Nginx官方提供的限制IP连接和并发的模块有两个:
limit_req_zone:用来限制单位时间内的请求数,即速率限制,采用的漏桶算法
limit_req_conn:来限制同一时间连接数,即并发限制
单位时间内请求数限制
修改主配文件
1 2 3 4 5 6 7 8 9 10 11 12 13 # 在http快下调用模块 # $binary_remote_addr :基于ip地址做限制# zone:创建缓存域和缓存大小 # rate:设置访问频数 limit_req_zone $binary_remote_addr zone=cqm:10m rate=1r/s; # server块 location /test { ... # 调用模块 # 当请求数超过5次时,就拒绝访问,并返回503状态码 limit_req zone=cqm burst=5 nodelay; }
限制并发连接数
修改主配文件
1 2 3 4 5 6 7 8 9 10 11 # 在http快下调用模块 # $binary_remote_addr :基于ip地址做限制# zone:创建缓存域和缓存大小 limit_req_conn $binary_remote_addr zone=cqm:10m; # server块 location /test { ... # 限制同一时间内下载数为1个 limit_conn cqm 1; }
限制下载速度
修改主配文件
1 2 3 4 5 location /test { ... # 限制下载速度为1k limit_rate 1k; }
2.11 Nginx的URL重写 rewrite的主要功能是实现URL地址的重定向。Nginx的rewrite功能需要PCRE软件的支持,即通过perl兼容正则表达式语句进行规则匹配的。默认参数编译nginx就会支持rewrite的模块,但是也必须要PCRE的支持。
URL模板语块:
set:设置变量
if:判断
return:返回值或URL
break:终止
rewrite:重定向URL
例一:根据不同域名跳转到主域名的不同目录下
创建测试目录
1 2 3 4 mkdir /usr/local/nginx/html/{cn,jp,us} echo 'this is China' > /usr/local/nginx/html/cn/index.html echo 'this is Japan' > /usr/local/nginx/html/jp/index.html echo 'this is America' > /usr/local/nginx/html/us/index.html
修改hosts文件,以便解析
1 2 3 4 5 vim /etc/hosts 192.168.88.100 www.cqm.com 192.168.88.100 www.cqm.com.cn 192.168.88.100 www.cqm.com.jp 192.168.88.100 www.cqm.com.us
修改主配文件
1 include /usr/local/nginx/conf/conf.d/rewrite.conf
修改重定向文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 vim /usr/local/nginx/conf/conf.d/rewrite.conf # 设置重定向server server { listen 80; server_name www.cqm.com.cn www.cqm.com.jp www.cqm.com.us; location / { # 模糊匹配到cn的话,就跳转到http://www.cqm.com/cn下 if ($http_host ~ (cn)$){ set $nation cn; rewrite ^/$ http://www.cqm.com/$nation; } if ($http_host ~ (jp)$){ set $nation jp; rewrite ^/$ http://www.cqm.com/$nation; } if ($http_host ~ (us)$){ set $nation us; rewrite ^/$ http://www.cqm.com/$nation; } } } server { listen 80; server_name www.cqm.com; location / { root html; index index.html; } }
测试
1 2 3 4 5 6 7 curl -L http://www.cqm.com.cn this is China curl -L http://www.cqm.com.jp this is Japan curl -L http://www.cqm.com.us this is America -L:自动获取重定向
例二:retuen以及break的简单实用
修改重定向文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 vim /usr/local/nginx/conf/conf.d/rewrite.conf server { listen 80; server_name www.cqm.com; location / { root html; index index.html; # 模糊匹配 ~ # 精确匹配 = # 不匹配 !~ # 如果匹配请求头不是chrome的话,就返回403 if ($http_user_agent !~ 'chrome'){ return 403; # break放在return上面的话就不会执行return操作 # break; # return http://www.baidu.com; } } }
flag
flag是放在rewrite重定向的URL后边的,格式为:rewrite URL flag
flag的选项有:
last:本条规则匹配完成后继续执行到最后。
break:本条规则匹配完成即终止。
redirect:返回302临时重定向。
permanent:返回301永久重定向。
redirect和permanent的区别:设置permanent的话,新网址就会完全继承旧网址,旧网址的排名等完全清零,如果不是暂时迁移的情况下都建议使用permanent;设置redirect的话,新网址对旧网址没有影响,且新网址也不会有排名。
2.12 Nginx优化 2.12.1 大并发 Nginx的工作模式:主进程 + 工作进程
假如Nginx服务器有4个CPU
设置主配文件来实现高并发
1 2 3 4 5 6 7 8 vim /usr/local/nginx/conf/nginx.conf worker_processes 4; # 指定运行的核的编号,采用掩码的方式设置编号 worker_cpu_affinity 0001 0010 0100 1000; events { # 单个工作进程维护的请求队列长度,根据实际情况调整 worker_connections 1024; }
2.12.2 长连接
修改主配文件
1 2 3 4 5 6 7 vim /usr/local/nginx/conf/nginx.conf # keepalive_timeout用来设置长连接,0代表关闭 keepalive_timeout 0; # 设置长连接时间100s # keepalive_timeout 100; # 设置每秒可以接受的请求数 # keepalive_requests 8192;
2.12.3 压缩 Nginx是采用gzip进行压缩。
修改主配文件
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 vim /usr/local/nginx/conf/nginx.conf # 开启缓存 gzip on; # Nginx做为反向代理的时候启用 # off:关闭所有的代理结果数据压缩 # expired:如果header中包含”Expires”头信息,启用压缩 # no-cache:如果header中包含”Cache-Control:no-cache”头信息,启用压缩 # no-store:如果header中包含”Cache-Control:no-store”头信息,启用压缩 # private:如果header中包含”Cache-Control:private”头信息,启用压缩 # no_last_modified:启用压缩,如果header中包含”Last_Modified”头信息,启用压缩 # no_etag:启用压缩,如果header中包含“ETag”头信息,启用压缩 # auth:启用压缩,如果header中包含“Authorization”头信息,启用压缩 # any:无条件压缩所有结果数据 gzip_proxied any; # 启用gzip压缩的最小文件,小于设置值的文件将不会压缩 gzip_min_length 1k; # 设置压缩所需要的缓冲区大小 # 32 4K表示按照内存页(one memory page)大小以4K为单位(即一个系统中内存页为4K),申请32倍的内存空间 # 建议此项不设置,使用默认值 gzip_buffers 32 4k; # 设置gzip压缩级别,级别越底压缩速度越快文件压缩比越小,反之速度越慢文件压缩比越大 gzip_comp_level 1; # 用于识别http协议的版本,早期的浏览器不支持gzip压缩,用户会看到乱码,所以为了支持前期版本加了此选项。默认在http/1.0的协议下不开启gzip压缩 gzip_http_version 1.1; # 设置需要压缩的MIME类型,如果不在设置类型范围内的请求不进行压缩 gzip_types text/plain application/javascript application/x-javascript text/css application/xml text/javascript application/x-httpd-php image/jpeg image/gif image/png application/vnd.ms-fontobject font/ttf font/opentype font/x-woff image/svg+xml;
2.12.4 静态缓存 将部分数据缓存在用户本地磁盘,用户加载时,如果本地和服务器的数据一致,则从本地加载。提升用户访问速度,提升体验度。节省公司带宽成本。
修改主配文件
1 2 3 4 5 # 模糊匹配以png或gif结尾的文件 location ~* \.(png|gif)$ { # 缓存时间为1小时 expires 1h; }
三、Tomcat 3.1 Tomcat介绍 Tomcat 服务器是一个免费的开放源代码的 Web 应用服务器,属于轻量级应用服务器,在中小型系统和并发访问用户不是很多的场合下被普遍使用,是开发和调试 JSP 程序的首选。
实际上 Tomcat 是 Apache 服务器的扩展,但运行时它是独立运行的,所以当你运行 tomcat 时,它实际上作为一个与 Apache 独立的进程单独运行的。
Tomcat 官方文档:https://tomcat.apache.org/
3.2 Tomcat安装
安装jdk和tomcat
1 2 3 4 5 6 yum -y install java-1.8.0-openjdk* wget https://downloads.apache.org/tomcat/tomcat-9/v9.0.43/bin/apache-tomcat-9.0.43.tar.gz tar -xf apache-tomcat-9.0.43.tar.gz mkdir /root/tomcat mv apache-tomcat-9.0.43.tar.gz/* /root/tomcat ./root/tomcat/bin/startup.sh