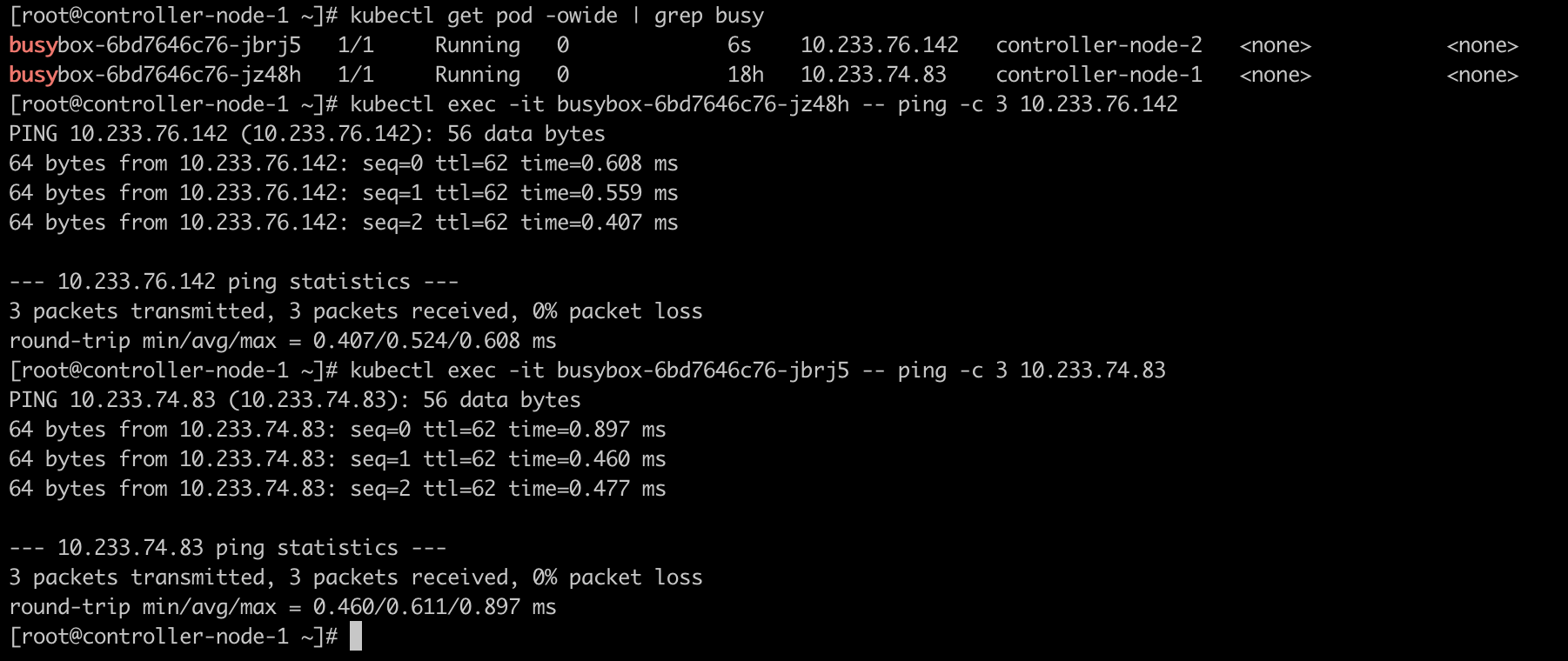
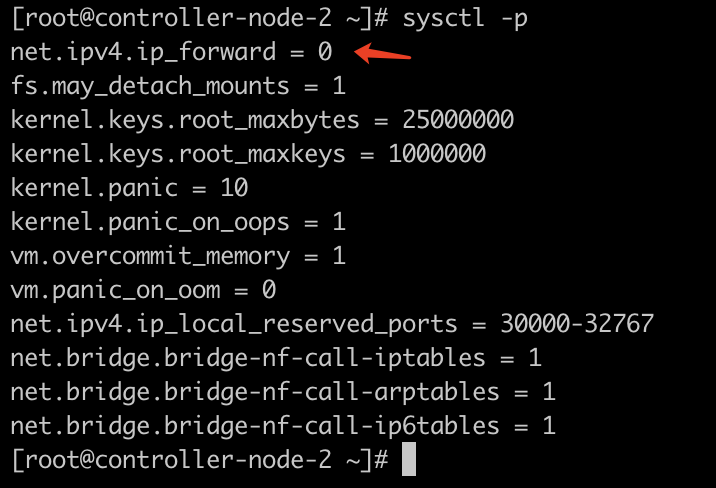
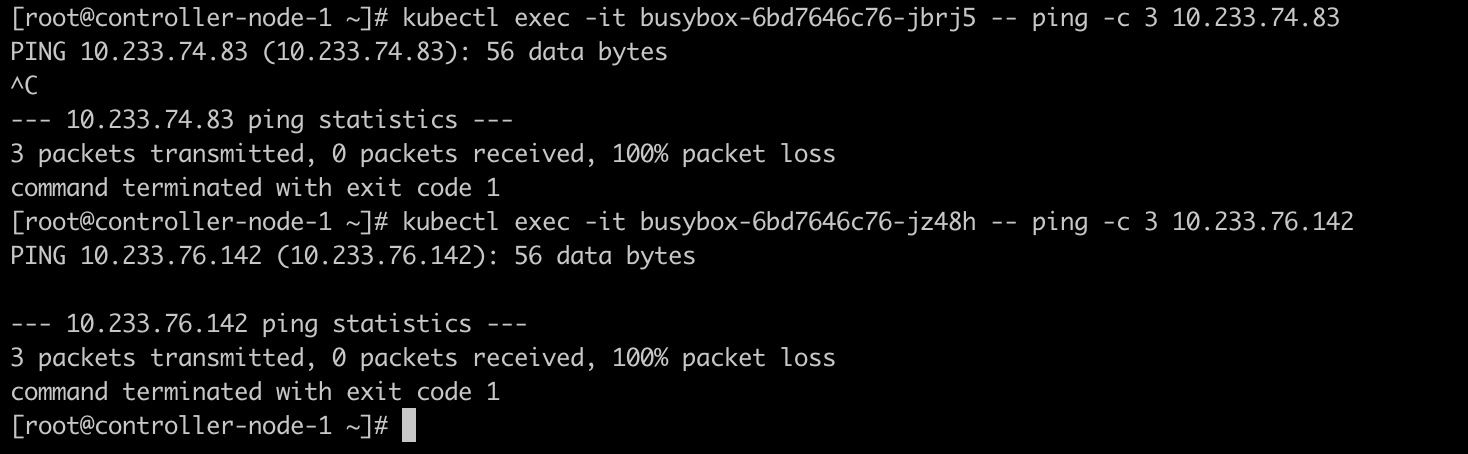
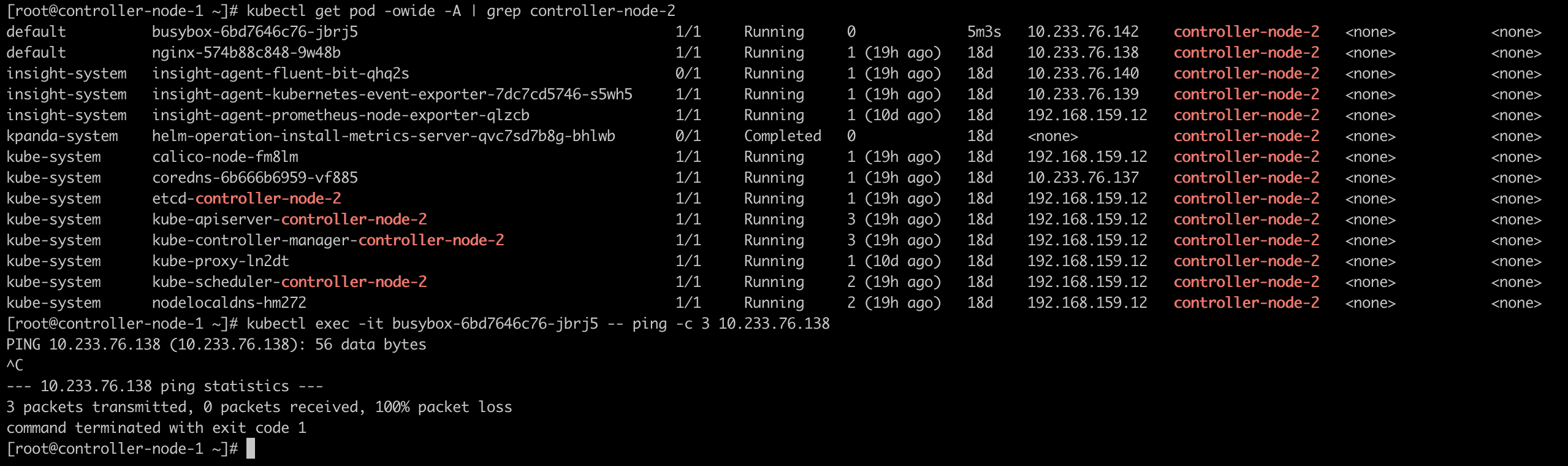
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
| [root@controller-node-1 ~]
tcpdump: listening on any, link-type LINUX_SLL (Linux cooked), capture size 262144 bytes
22:58:29.405332 IP (tos 0x0, ttl 64, id 48447, offset 0, flags [DF], proto UDP (17), length 59)
10.233.74.83.38430 > 10.233.0.3.53: [bad udp cksum 0x6060 -> 0xdcc6!] 28765+ A? www.baidu.com. (31)
22:58:29.405423 IP (tos 0x0, ttl 64, id 48448, offset 0, flags [DF], proto UDP (17), length 59)
10.233.74.83.38430 > 10.233.0.3.53: [bad udp cksum 0x6060 -> 0xcdcd!] 25686+ AAAA? www.baidu.com. (31)
22:58:29.405881 IP (tos 0x0, ttl 64, id 42712, offset 0, flags [DF], proto UDP (17), length 59)
10.233.74.66.56555 > 192.168.0.5.53: [bad udp cksum 0x1611 -> 0x2f90!] 1558+ AAAA? www.baidu.com. (31)
22:58:29.405950 IP (tos 0x0, ttl 63, id 42712, offset 0, flags [DF], proto UDP (17), length 59)
192.168.159.41.56555 > 192.168.0.5.53: [bad udp cksum 0x20b8 -> 0x24e9!] 1558+ AAAA? www.baidu.com. (31)
22:58:29.406110 IP (tos 0x0, ttl 64, id 42713, offset 0, flags [DF], proto UDP (17), length 59)
10.233.74.66.58403 > 192.168.0.5.53: [bad udp cksum 0x1611 -> 0xf518!] 21589+ A? www.baidu.com. (31)
22:58:29.406191 IP (tos 0x0, ttl 63, id 42713, offset 0, flags [DF], proto UDP (17), length 59)
192.168.159.41.58403 > 192.168.0.5.53: [bad udp cksum 0x20b8 -> 0xea71!] 21589+ A? www.baidu.com. (31)
22:58:29.410592 IP (tos 0x0, ttl 63, id 39983, offset 0, flags [DF], proto UDP (17), length 118)
192.168.0.5.53 > 192.168.159.41.58403: [udp sum ok] 21589 q: A? www.baidu.com. 3/0/0 www.baidu.com. [2m9s] CNAME www.a.shifen.com., www.a.shifen.com. [2m9s] A 183.2.172.185, www.a.shifen.com. [2m9s] A 183.2.172.42 (90)
22:58:29.410637 IP (tos 0x0, ttl 62, id 39983, offset 0, flags [DF], proto UDP (17), length 118)
192.168.0.5.53 > 10.233.74.66.58403: [udp sum ok] 21589 q: A? www.baidu.com. 3/0/0 www.baidu.com. [2m9s] CNAME www.a.shifen.com., www.a.shifen.com. [2m9s] A 183.2.172.185, www.a.shifen.com. [2m9s] A 183.2.172.42 (90)
22:58:29.410972 IP (tos 0x0, ttl 63, id 64831, offset 0, flags [DF], proto UDP (17), length 166)
10.233.0.3.53 > 10.233.74.83.38430: [bad udp cksum 0x60cb -> 0xe43e!] 28765 q: A? www.baidu.com. 3/0/0 www.baidu.com. [30s] CNAME www.a.shifen.com., www.a.shifen.com. [30s] A 183.2.172.42, www.a.shifen.com. [30s] A 183.2.172.185 (138)
22:58:29.413159 IP (tos 0x0, ttl 63, id 39984, offset 0, flags [DF], proto UDP (17), length 142)
192.168.0.5.53 > 192.168.159.41.56555: [udp sum ok] 1558 q: AAAA? www.baidu.com. 3/0/0 www.baidu.com. [3m29s] CNAME www.a.shifen.com., www.a.shifen.com. [3m29s] AAAA 240e:ff:e020:9ae:0:ff:b014:8e8b, www.a.shifen.com. [3m29s] AAAA 240e:ff:e020:966:0:ff:b042:f296 (114)
22:58:29.413203 IP (tos 0x0, ttl 62, id 39984, offset 0, flags [DF], proto UDP (17), length 142)
192.168.0.5.53 > 10.233.74.66.56555: [udp sum ok] 1558 q: AAAA? www.baidu.com. 3/0/0 www.baidu.com. [3m29s] CNAME www.a.shifen.com., www.a.shifen.com. [3m29s] AAAA 240e:ff:e020:9ae:0:ff:b014:8e8b, www.a.shifen.com. [3m29s] AAAA 240e:ff:e020:966:0:ff:b042:f296 (114)
22:58:29.413922 IP (tos 0x0, ttl 63, id 64833, offset 0, flags [DF], proto UDP (17), length 190)
10.233.0.3.53 > 10.233.74.83.38430: [bad udp cksum 0x60e3 -> 0x9ac9!] 25686 q: AAAA? www.baidu.com. 3/0/0 www.baidu.com. [30s] CNAME www.a.shifen.com., www.a.shifen.com. [30s] AAAA 240e:ff:e020:966:0:ff:b042:f296, www.a.shifen.com. [30s] AAAA 240e:ff:e020:9ae:0:ff:b014:8e8b (162)
|