Posted Updated a few seconds read (About 4 words)
没有首页
没有首页
事情发生在 UAT 环境的其中一台 Controller 节点,节点根目录被打满,同时 etcd 数据没有落盘到独立的磁盘中,导致 etcd 憨批,节点出现 notready
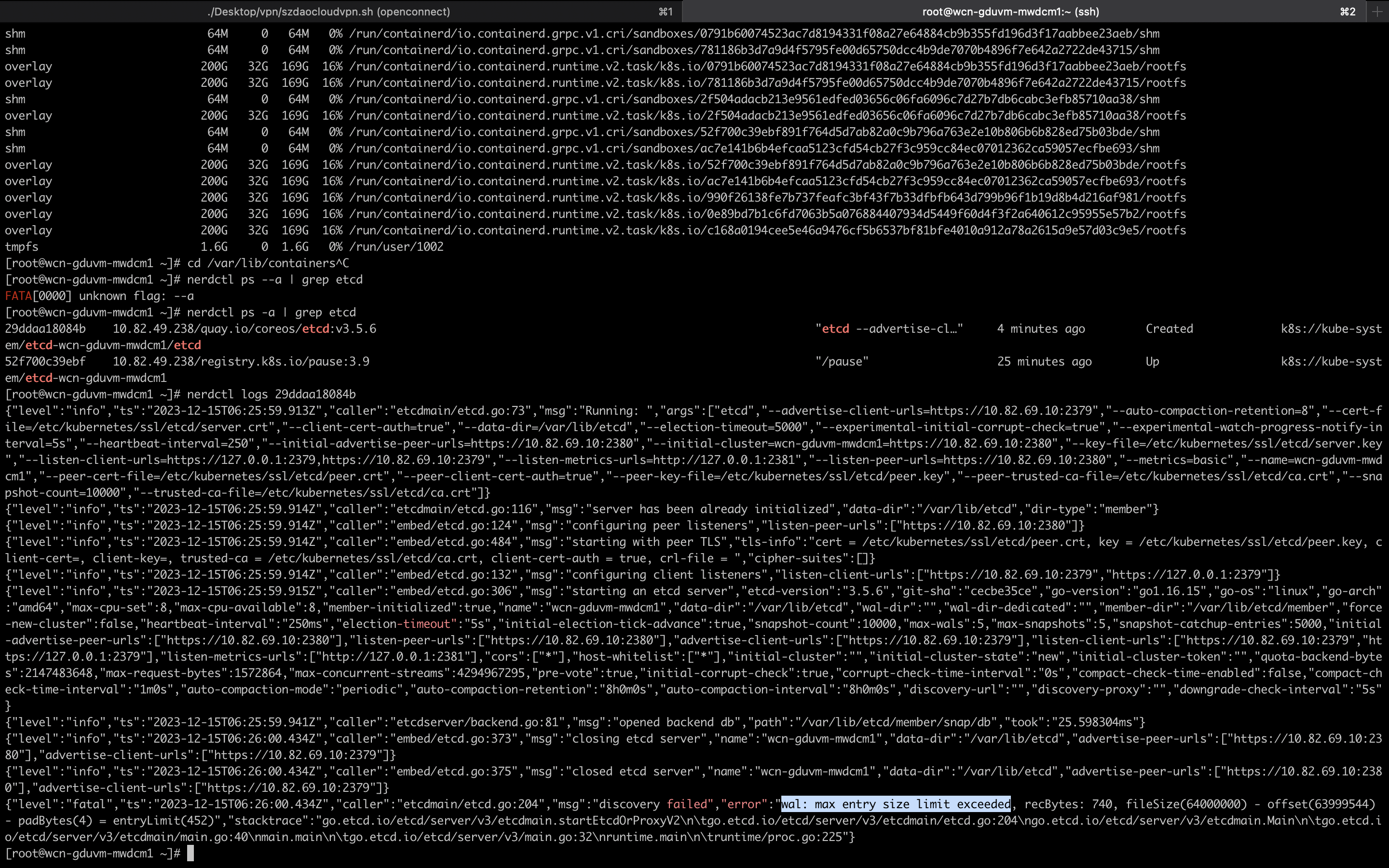
参考了各种网络资料,最终形成如下修复手段:
statis pod yaml,从而停止坏掉的 etcd podetcdctl member remove 移除坏掉的 etcd 实例etcdctl member add 添加新实例,记录 etcdctl 输出的配置信息statis pod yaml 和第 4 步输出的配置信息etcdctl endpoint status -w table 查看状态statis pod yaml 放回对应的目录中,集群修复具体的操作命令:
1 | # stop issue etcd pod |
Cgroup 即 Control Group,是一种 Linux 内核机制,它允许对进程进行资源控制和管理。Cgroup 可以限制进程的 CPU 使用率、内存使用量、磁盘 I/O 等资源。
Cgroup 主要作用:
Netns 即 Network Namespace,是一种 Linux 内核机制,它允许在不同的进程之间隔离网络资源。这意味着每个 Network Namespace 都有自己的独立网络配置,例如 IP 地址、端口号和路由表。
Netns 主要作用:
Mountns 即 Mount namespace,是一种 Linux 内核机制,它允许在不同的进程之间隔离挂载点。这意味着每个 mount namespace 都有自己的独立挂载视图,即使它们位于同一个物理主机上。
Mountns 主要作用:
Cgroup、Netns、Mountns 都是 Linux 内核机制,用于处理不同类型资源的隔离。
Calico 的运行支持三种模式:
封包解包: 在 vxlan 设备上将 Pod 发来的数据包源、目的 mac 地址替换为本主机 vxlan 网卡和对端 vxlan 网卡的 mac 地址
优缺点: vxlan 的数据包会封装在 udp 数据包中,所以要求节点之间三层互通,支持跨网段。但封包解包的过程会有一定网络性能损耗
封包解包: 在 tun0 设备上将 Pod 发来的数据包的 mac 层去除,留下 ip 层并使用宿主机的 ip 进行一次封包
优缺点: 要求节点之间三层互通,支持跨网段。但封包解包的过程会有一定网络性能损耗
封包解包: 不进行封包解包
优缺点: 通过 bgp 协议就可以支持节点之间的三层互通。
vxlan 和 ipip 都支持配置 CrossSubnet 模式,这种模式下,只有跨网段节点的 Pod 之间的通信才会进行封包解包,而同一网段节点的 Pod 之间则使用 bgp 模式进行通信,能够在一定程度上提高网络性能。
PPP协议即点对点协议,属于数据链路层协议,一般用于广域网。PPP协议首先会建立物理链路,当物理链路建立成功,就通过链路控制协议LCP来建立数据链路连接,接着网络控制协议NCP就会协商该链路上所传输的数据包格式和类型,从而建立不同的网络层协议。
CSMA/CD协议即载波监听多点接入/碰撞检测协议,属于数据链路层协议。工作原理是发送数据之前会先侦听信道是否空闲,如果空闲就发送数据,如果忙碌就等待一段时间再发送,即载波监听;当上一段信息发送完后,发生了两个或两个以上的节点同时发送数据,那就判定为冲突,会立即停止发送,等待一段时间再发送数据,即碰撞检测。节点在发送过程中也会监听信道。所以CSMA/CD的工作原理可以概括为:先听后发、边发边听、冲突停发、随机延迟后重发。
vlan 即虚拟局域网,就是把一个大的局域网,划分为多个相互隔离的小局域网,用于划分数据链路层,可以实现隔离广播域,避免每个节点收到太多无用的广播包,减小节点性能和网络宽带的消耗,同时可以隔离常见的攻击,如 arp 攻击,受到攻击的影响范围仅限于该 vlan。
地址解析协议ARP,是根据IP地址来获取物理地址的协议,工作在数据链路层,源主机发送信息时会将目标地址主机的IP地址通过广播的形式发送到局域网内的所有主机上,目标地址主机收到广播后就会将自己的MAC地址发送给源主机,这样源主机就会将目标地址主机的IP地址和MAC地址保存在ARP缓存中,从而节约网络资源。
RIP是采用距离向量的路由选择协议,属于内部网关协议,使用 “跳数” 来衡量到达目标地址的路由距离。距离的取值为0 - 16,16即为不可达。RIP协议仅和相邻路由器交换信息,交换的信息是自己的路由表,每30秒就会交换一次,如果超过180秒没收到相邻路由器发送过来的信息,则视为不可达。
OSPF即开放最短路径优先,属于内部网关协议,是采用洪泛法向自治系统内的所有路由器发送信息,每一个相邻路由器会将此消息再次发送给相邻的路由器,交换的信息是与本路由器相邻的所有路由器的链路状态,链路状态可以是费用、距离、时延、带宽等,只有当链路状态发生变化时,路由器才会向所有路由器采用洪泛法发送消息。
OSPF工作状态:
OSPF的五种包类型:
OSPF区域:
同一区域内的路由器才会建立关系,交换LSA,收敛后,同一区域内的路由器都拥有相同的LSDB。
如果有多个区域,那么每个区域都会选择一个性能较好的路由器来作为ABR(区域边界路由器),不同区域内的路由器进行通信直接通过这个ABR转发路由。
每个区域都有一个区域ID,为32位二进制数,可以表达为一个十进制数,也可以表达为一个点分十进制数字,例如区域0等价于0.0.0.0,区域1等价于0.0.0.1
骨干区域为区域0
非骨干区域间进行通信都要通过骨干区域0进行转发
如果网络中有不同的OSPF区域,那么有个区域肯定是区域0
BGP即边界网关协议,属于外部网关协议,是不同自治系统AS使用的协议,每个自治系统都要有一个BGP发言人,用来交换信息,交换的信息是网络可达性的信息,即要到达某一网络所经过的一系列自治系统,且只有在信息发生变化时才会进行信息交换。
PING实际就是发送一个ICMP回送请求报文给目的主机,并等待回送的ICMP响应。实际就是利用了IP地址的唯一性,给目标主机的IP地址发送一个ICMP数据包,再要求对方返回一个同等大小的数据包来确定两台主机是否相互连通,以及时延是多少。
Traceroute是通过TTL和ICMP报文来确定从一个主机到网络上其他主机的路由。首先会发送一个TTL为1的数据包到目的主机,经过一个路由器TTL就减1,此时TTL为0数据包就会被丢弃,路由器会回送一个ICMP超时报文给源主机,源主机收到超时报文后,就会将TTL的值加1,再发送数据包到目的主机,不断重复以上的过程直到数据包到达目的主机,目的主机收到数据包后就会会送一个ICMP响应报文。
IP 是以网络号和主机号构成的,只有在同一个网络号下的主机才能够相互通信,不同网络号的主机要通信就要通过网关来实现,但只通过网络号来划分并不灵活,而子网就是将一个网络划分为更多个小的网络,这些小的网络就是子网,每一个子网都有相应的子网掩码,子网掩码就是用来判断多个 IP 是否在同一子网中的。
TCP与UDP的区别:
TCP的流量控制:
TCP的拥塞控制(加法增大乘法减小算法 AIMD):
流量控制和拥塞控制的区别:
TCP的三次握手和四次挥手
TIME_WAIT 状态产生的原因:
大量 TIME_WAIT 状态所带来的危害:
为什么会采用三次握手,二次握手可以吗?第三次握手失败了怎么办?
为什么断开连接要四次挥手?
TCP连接数过高怎么办?
产生大量TIME_WAIT的原因有哪些?
DNS 即域名系统,在互联网中为域名和IP地址进行相互映射的一个分布式数据库,采用UDP协议,使用UDP53端口进行传输。
DNS 中,主机向本地域名服务器的查询一般都是采用递归查询,如果主机所询问的本地域名服务器不知道被查询域名的IP地址时,那么本地域名服务器就会以DNS客户的身份向其它域名服务器发送查询请求,就是代替主机继续查询;本地域名服务器向根域名服务器的查询通常是采用迭代查询,当根域名服务器收到本地域名服务器发出的迭代查询请求报文时,要么给出所要查询的IP地址,要么告诉本地域名服务器下一步应当向哪一个域名服务器进行查询,然后让本地域名服务器进行后续的查询,查询到结果就会回送给源主机。
DHCP 即动态主机配置协议,是用与局域网的协议,采用UDP进行传输,服务端采用67端口,客户端采用68端口。
Linux在完成核内引导以后,就开始运行init程序,包括以下几个运行级:
Linux 是一个支持多任务的操作系统,支持远大于 CPU 数量的任务同时运行,其实这些任务不是真正在同时运行,而是系统在很短时间内,将 CPU 轮流分配给它们,速度极快造成了像是在同时运行的错觉。而每个任务在运行前,CPU 都需要知道任务从哪里加载、从哪里运行,也就是需要系统为它们设置好 CPU 寄存器和程序计数器。
CPU 寄存器和程序计数器都是 CPU 在运行任何任务前,必须依赖的环境,就被称为 CPU 上下文。
CPU 上下文切换就是指把先前一个任务的 CPU 上下文(CPU 寄存器和程序计数器的位置)保存起来,再加载新任务的上下文到这些寄存器和计数器,最后再跳转到程序计数器所指的新位置,运行新任务。而保存下来的上下文,会存储在系统内核中,并在任务重新调度执行时再加载进来,这样就能保证任务原来的状态不受影响,让任务看起来像是连续运行。
进程上下文切换
进程的运行空间分为内核空间和用户空间,分别对应 CPU 特权等级的 Ring0 和 Ring3。
内核空间(Ring0)具有最高权限,可以直接访问所有资源;用户空间(Ring3)只能访问受限资源,不能直接访问系统资源,必须通过系统调用陷入到内核才可以使用。
所以说进程可以在内核空间和用户空间运行,在前者运行被称为内核态,后者被称为用户态。从用户态到系统态的转变,就需要通过系统调用,比如查看文件内容就要依次调用 open()、read()、close()。在这期间就发生了上下文切换,CPU 寄存器里原来的用户态的指令位置需存起来,然后更行为内核态指令的新位置,最后跳转到内核态运行任务。系统调用结束后,CPU 寄存器需要恢复到原来用户态的指令位置,所以一次系统调用是发生了两次上下文切换。但系统调用又和进程上下文切换不太一样,进程上下文切换时一个进程切换到另一个进程运行,系统调用是在通过一个进程上运行的,后者常被称为特权模式切换。